

文章目录
前言
本章是编译原理 (Compiler Construction) 的课程笔记。本课程使用教科书:《Compiler Construction: Principles and Practice》 (Kenneth C. Louden, ISBN:9780534939724, Publisher: Course Technology, 1997),中文为:《编译原理及实践》
NOTE课程资料:
Introduce to Compiler
编译器 (Compiler) 是一种将高级编程语言(如C、C++、Java等)翻译 成机器语言(即计算机能够直接执行的二进制代码)的程序。
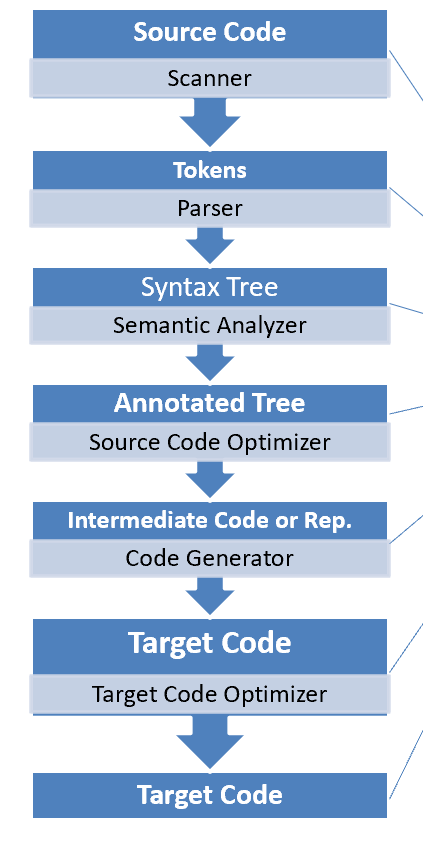
编译器通常分为前端和后端:
- 前端:Scanner (词法分析)、Parser (语法分析)、Semantic Analyzer (语义分析)
- 后端:Code Generator (代码优化)、Target Code Optimizer (目标代码生成)
- Scanner(词法分析器): 将源代码分解为词法单元(tokens),例如关键字、标识符、常量、运算符等。Scanner接收源代码作为输入,并输出一系列的tokens供Parser使用。
- Parser(语法分析器) : 根据语言的语法规则,分析tokens的结构,构建语法树(或抽象语法树)。Parser接收来自Scanner的tokens,并输出语法树,供Semantic Analyzer使用。
- Semantic Analyzer(语义分析器) :检查语法树的语义正确性,包括类型检查、作用域检查等,确保程序的逻辑是合理的。Semantic Analyzer接收语法树作为输入,并在检查后输出一个经过验证的语法树(带注释的语法分析树,Annotated Tree)或中间表示(IR),供Code Generator使用。
- Code Generator(代码生成器) :将经过语义分析的中间表示转换为目标机器代码。Code Generator接收经过语义分析的中间表示,并生成对应的机器代码或汇编代码,供Target Code Optimizer使用。
- Target Code Optimizer(目标代码优化器) :对生成的目标代码进行优化,以提高执行效率,减少资源消耗。Optimizer接收目标代码,进行各种优化,并输出优化后的目标代码,最终形成可执行文件。
Theory of Computation
Grammar
Grammar (文法) 是用来定义编程语言语法的一种形式化工具。它可以通过一个四元组定义,
- V (Variables, 变量): 非终结符号的集合。可以把非终结符想象成句子中的主语、谓语、宾语等成分,它们是可以被进一步分解和替换的符号。 通常用大写字母表示,例如 A, B, S 等。
- T (Terminals, 终结符):终结符号的集合。这些是语言中的基本单元,无法再被分解的符号。在编程语言中,终结符通常是关键字(如
if,else)、标识符(变量名)、运算符(如+,-)和常量(如数字、字符串)等。通常用小写字母或者数字、符号表示,例如a,b,0,1,+等。V 和 T 是非空且互不相交的 - S (Start Symbol, 起始符):文法的开始符号,表示一个完整的语句。S 一定属于非终结符集合 V。
- P (Productions,产生式):一组替换规则,产生式定义了将非终结符 (V) 转换成终结符 (T) 或者其他非终结符 (V) 的规则。
每个产生式都具有 x → y 的形式,其中 x 是一个由至少一个符号组成的串,这个串中至少包含一个非终结符,即 x ∈ (V ∪ T)+ 并且 x 至少包含一个 V 中的元素。y 是一个由终结符和非终结符组成的任意串,即 y ∈ (V ∪ T)*。产生式的含义是,可以将 x 替换为 y。
让我们用一个简单的例子来说明, 假设我们要定义一个由若干个 ‘a’ 组成的字符串的语言。我们可以定义一个文法 G 如下:
V = {S}T = {a}Start Symbol = SP = {S → aS, S → a}
在这个例子中,S 是非终结符,a 是终结符。 产生式 S → aS 表示可以将 S 替换为 aS,而 S → a 表示可以将 S 替换为 a。
推导 (derivation) 是指从文法的起始符号开始,不断应用产生式规则,最终得到一个由终结符组成的串的过程。
给定一个产生式规则 x → y,如果有一个包含 x 的字符串 w = uxv,我们可以将 x 替换为 y,得到新的字符串 z = uyv。这时我们称 “w 推导出 z”,记作 w ⇒ z。可以理解为,我们根据文法的规则,一步步地将非终结符展开成终结符。
如果存在一个推导序列 w₁ ⇒ w₂ ⇒ w₃ … ⇒ wₙ,那么我们称 w₁ 推导出 wₙ,记作 w₁ ⇒* wₙ。这里的 ⇒* 表示经过零步或多步推导。
在上面的例子中,我们可以通过以下推导步骤得到字符串 “aaa”:
S ⇒ aS(应用产生式S → aS)aS ⇒ aaS(应用产生式S → aS)aaS ⇒ aaa(应用产生式S → a)
因此,我们说 S 推导出 “aaa”。
总的来说,文法通过定义非终结符、终结符、起始符号和产生式规则,描述了一个语言的所有可能的字符串结构。推导则是根据这些规则 生成语言中字符串的过程。
DFA
介绍了文法之后,我们来介绍 有限自动机 (Finite Automaton, FA)。有限自动机是一种抽象的计算模型,它可以识别特定的语言。想象一个只有有限数量 内存的机器,它 读取输入串,并根据读取到的符号从一个状态转换到另一个状态。
有限自动机主要分为两种类型:确定性有限自动机 (Deterministic Finite Automaton, DFA) 和 非确定性有限自动机 (Nondeterministic Finite Automaton, NFA)
DFA 是一个五元组,表示为 ,其中:
-
(States): 是一个有限的状态集合。自动机在任何时刻都处于这些状态中的某一个。
-
(Alphabet): 是一个有限的输入字母表。这是自动机可以接收的所有输入符号的集合。
-
(Transition function): 是转移函数,它定义了自动机在给定状态和输入符号下如何转移到下一个状态。 对于 DFA 来说,这个转移是确定 的,也就是说,对于任何一个状态 和任何一个输入符号 ,都唯一对应着一个下一个状态。 我们可以将转移函数表示为 。 例如, 表示当自动机处于状态 ,并且读取到输入符号 时,它会转移到状态 。
-
s (Start state): 是起始状态,也称为初始状态。它是自动机开始处理输入之前的状态。。
-
F (Final states): 是接受状态的集合,也称为终止状态。。如果自动机在读取完整个输入字符串后,停留在某个接受状态,那么我们就说这个 DFA 接受了该输入字符串。
对于一个 DFA ,它所接受的语言 定义为所有能让 DFA 从起始状态开始,经过一系列状态转移,最终停留在接受状态的输入字符串的集合。它可以表示为:, 是对转移函数 的扩展,使其可以处理字符串输入。
这里的转移函数可以嵌套,例如:
从非形式化的角度来看,DFA 的工作方式可以这样理解:
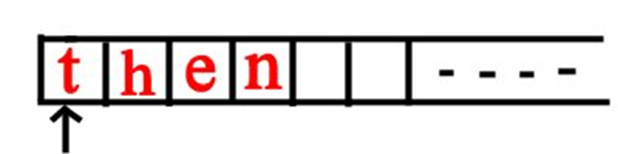
- 输入准备:首先,将要被处理的输入字符串放在一个“纸带”上,通常是左对齐的。
- 初始状态:DFA 从起始状态开始运行。
- 头字符定位:一个“header”指针指向纸带上最左边的符号,也就是输入字符串的第一个符号。
- 循环处理:DFA 进入一个循环,直到整个输入字符串被读取完毕。
- 查阅转移表:在每一步,DFA 根据当前的 状态 (s) 和读头指向的 输入符号 (σ) 查阅它的 转移表。
- 状态转移:根据转移表中的指示,DFA 转换到下一个状态。转移表可以看作是一个函数,输入是当前状态和输入符号,输出是下一个状态。
- 接受或拒绝:当整个输入字符串被读取完毕后,DFA 停止运行。如果 DFA 当前所处的状态是 接受状态 (final state),那么 DFA 就 接受 这个输入字符串。 否则,如果 DFA 停留在非接受状态,则 拒绝 该字符串。
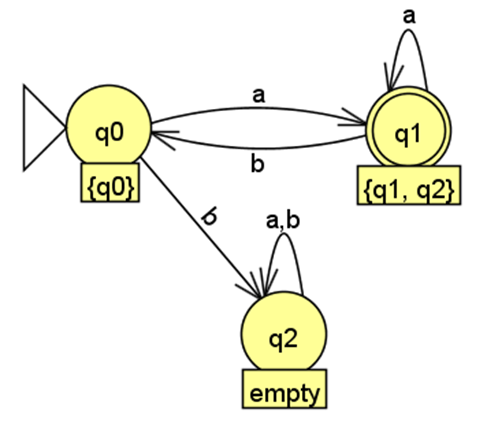
DFA 可以用 状态转移图 (state transition diagram) 来直观地表示。状态转移图由以下元素组成:
- 状态 (States):DFA 的每个状态都用一个 圆圈 表示。
- 转移 (Transitions):状态之间的转移用 带箭头的有向边 表示。 箭头从一个状态指向另一个状态,箭头上的 标签 是触发该转移的 输入符号。 例如,如果从状态 到状态 有一个标有 ‘a’ 的箭头,表示当 DFA 处于状态 并读取到输入符号 ‘a’ 时,会转移到状态 。
- 起始状态 (Start state):起始状态用一个 指向该状态的三角形 表示,箭头没有起点。
- 接受状态 (Final states):接受状态用 双层圆圈 表示。
例如下面这个例子:
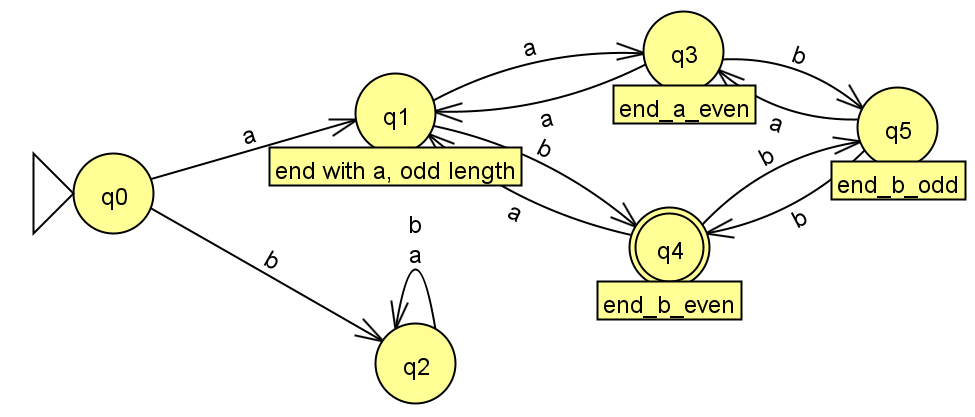
-
状态 (States):
q0: 初始状态,可以理解为“已读取的字符长度为 0 (偶数)”q1: 标记为 “end with a, odd length”,可以理解为“已读取的字符长度为奇数,且最后一个字符是 ‘a’”q2: 接受首次输入为 ‘b’ 时跳转,此处不符合由 ‘a’ 开头的接收状态。q3: 标记为 “end_a_even”,可以理解为“已读取的字符长度为偶数,且最后一个字符是 ‘a’”q4: 标记为 “end_b_even”,并且是 接受状态,可以理解为“已读取的字符长度为偶数,且最后一个字符是 ‘b’”q5: 标记为 “end_b_odd”,可以理解为“已读取的字符长度为奇数,且最后一个字符是 ‘b’”
-
转移 (Transitions):
-
from 0 to 1 on a: 在初始状态q0读到 ‘a’,转移到q1(长度变为奇数) -
from 0 to 2 on b: 在初始状态q0读到 ‘b’,转移到q2 -
from 1 to 3 on a: 在状态q1读到 ‘a’,转移到q3(长度变为偶数) -
from 3 to 1 on a: 在状态q3读到 ‘a’,转移到q1(长度变为奇数) -
from 1 to 4 on b: 在状态q1读到 ‘b’,转移到q4(长度变为偶数,且以 ‘b’ 结尾,是接受状态) -
from 3 to 5 on b: 在状态q3读到 ‘b’,转移到q5(长度变为奇数) -
from 4 to 1 on a: 在状态q4读到 ‘a’,转移到q1(长度变为奇数) -
from 5 to 3 on a: 在状态q5读到 ‘a’,转移到q3(长度变为偶数) -
from 4 to 5 on b: 在状态q4读到 ‘b’,转移到q5(长度变为奇数) -
from 5 to 4 on b: 在状态q5读到 ‘b’,转移到q4(长度变为偶数,且以 ‘b’ 结尾,是接受状态)
-
NFA
在之前学习 DFA 的时候,我们强调了“确定性”,即在任何给定状态下,对于任何输入的符号,DFA 要转换到的下一个状态是唯一的。
而 NFA (Nondeterministic Finite Automaton) 的核心特点就是它的“非确定性”。可以把 NFA 想象成一个在多个方向上同时进行计算的机器,在某个状态下,对于同一个输入符号,NFA 可以有 多个 下一个状态。
与 DFA 类似,一个 NFA 也可以用一个五元组来定义:
- (States):有限的状态集合,与 DFA 相同。
- (Alphabet):有限的输入字母表,与 DFA 相同。
- (Transition function):对于 NFA 来说,转移函数 的输入是一个状态和一个输入符号,输出是一个状态的集合。,其中 表示 所有子集的集合。从一个状态读取一个符号后,NFA 可以转移到多个可能的状态。例如, 表示当 NFA 处于状态 ,读取到输入符号 a 时,它可以同时转移到状态 。
- (Start state):起始状态,与 DFA 相同。
- (Final states):接受状态的集合,与 DFA 相同。
当 NFA 接收一个输入字符串时,它会从起始状态开始,根据输入的符号进行状态转移。由于 NFA 的非确定性,对于每个输入符号,NFA 可能会同时探索多条可能的计算路径。
一个 NFA 接受一个输入字符串,当且仅当存在 至少一条 从起始状态到某个接受状态的路径,使得这条路径上的符号与输入字符串匹配。只要存在一种可能的计算路径能够成功到达接受状态,NFA 就认为该字符串是被接受的。
下面是一个NFA的设计问题例子:
这个语言包含所有以字符串 “aaabb” 结尾的由 ‘a’ 和 ‘b’ 组成的字符串。
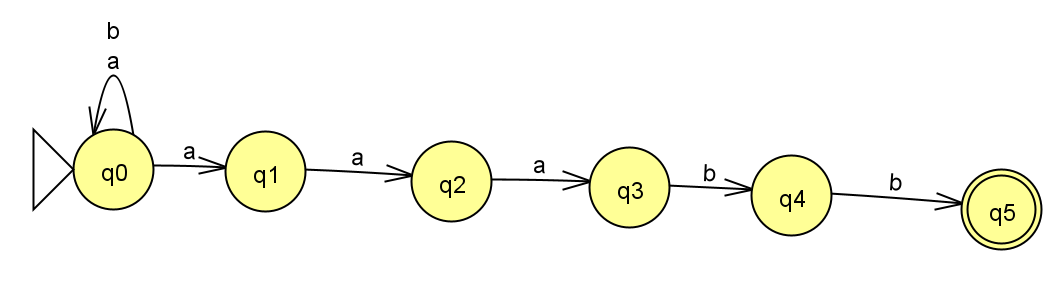
- 状态 (States):
q0: 起始状态。 在读取 “aaabb” 的任何前缀之前。这个状态有一个自环,遇到 ‘a’ 或 ‘b’ 仍然回到自身,可以在开始时读取任意数量的 ‘a’ 和 ‘b’。q1: 表示到目前为止,可能已经读取了 “a”。q2: 表示到目前为止,可能已经读取了 “aa”。q3: 表示到目前为止,可能已经读取了 “aaa”。q4: 表示到目前为止,可能已经读取了 “aaab”。q5: 接受状态。 表示已经成功读取了 “aaabb”。
- 转移 (Transitions):
from 0 to 0 on a: 在q0状态读取 ‘a’,仍然保持在q0(可以读取任意数量的 ‘a’ 开头)。from 0 to 0 on b: 在q0状态读取 ‘b’,仍然保持在q0(可以读取任意数量的 ‘b’ 开头)。from 0 to 1 on a: 在q0状态读取 ‘a’,可以转移到q1(开始匹配 “aaabb” 的第一个 ‘a’)。 注意这里从q0读取 ‘a’ 有两个可能的转移,这就是非确定性的体现。from 1 to 2 on a: 在q1状态读取 ‘a’,转移到q2(匹配到 “aaabb” 的前两个 ‘a’)。from 2 to 3 on a: 在q2状态读取 ‘a’,转移到q3(匹配到 “aaabb” 的前三个 ‘a’)。from 3 to 4 on b: 在q3状态读取 ‘b’,转移到q4(匹配到 “aaabb” 的前四个字符 “aaab”)。from 4 to 5 on b: 在q4状态读取 ‘b’,转移到接受状态q5(成功匹配 “aaabb”)。
通常情况下,对于同一个正则语言,描述它的 NFA 所需的状态数量往往比等价的 DFA 更少,或者至多相等。因为 NFA 的非确定性允许它在状态转移时“猜测”正确的路径,从而可以用更简洁的方式来描述模式。
在NFA中,存在一种特殊的转换,称为 转换。指的是在自动机中,不消耗任何输入符号就能发生的状态转移。可以把它想象成一种“自由移动”,自动机可以在不读取任何输入的情况下,从一个状态瞬间转移到另一个状态。
例如,如果一个 NFA 从状态 有一个 转换到状态 ,那么当 NFA 处于状态 时,它可以“选择”立即转移到 ,而不需要读取任何输入.
Regular Expression
正则表达式是描述正则语言的一种形式化工具,它与有限自动机(NFA 和 DFA)以及正则文法等价。正则表达式是用来描述正则语言的一种形式化工具。给定一个字母表 ,正则表达式的定义如下 :
- :表示空集,即不包含任何字符串的语言。
- :表示只包含空串的语言,即。与 的区别是, 是一个集合,而 是一个元素。
- :对于字母表 中的每个符号 ,表示包含该符号的语言,例如,如果 ,那么 表示语言 , 表示语言 。
通过组合已有的正则表达式,我们可以构建更复杂的正则表达式。如果 和 是正则表达式,那么以下也是正则表达式:
- :表示 和 的并集,即 。
- :表示 和 的连接,,即由 中的字符串后跟 中的字符串组成的所有字符串的集合 。
- :表示 的克莱尼星号 (Kleene star),即由 中的字符串连接任意多次(包括零次)组成的所有字符串的集合。例如,如果 ,那么 。
- :表示 分组,用于改变运算的优先级,或者使表达式更清晰。例如, 表示语言 ,而 表示语言 。
每个正则表达式都代表一个特定的语言:
- (空集)
- ,对于每个
- ( 和 的连接)
- ( 的克莱尼闭包)
为了避免歧义,正则表达式的运算符有以下优先级规则(和我们日常使用差不多):
- 克莱尼星号 () 优先级最高。
- 连接 () 优先级次之。
- 并集 () 优先级最低。
例如, 等价于 ,而不是 。可以使用括号来显式地改变优先级。
正则表达式和非确定性有限自动机 (NFA) 在表达能力上是等价的。
对于任何正则表达式 ,存在一个 NFA ,使得 。因此, 是一个正则语言。
对于基本正则表达式 , , 和 ,可以直接构造出简单的 NFA。对于复合正则表达式,可以通过组合其子表达式对应的 NFA 来构建。例如,
- 对于 ,可以将 和 对应的 NFA 并联起来;
- 对于 ,可以将它们串联起来;
- 对于 ,可以添加 转移来形成闭环
接下来,我们通过两个例子来说明他们之间的转换关系。
假设这是一个NFA的语言:
语言 包含所有由 0 和 1 组成的字符串,且这些字符串中恰好有一对连续的 0。这意味着:
- 字符串中必须包含子串 00。
- 字符串中不能包含更多的 00 子串。
假设一个串中间为”00”,则前缀/后缀部分不能包含 00 和 10,因此前缀/后缀可以是任意数量的 1 或 01。所以可以写为:
下面还有一个例子:给定字母表 ,正则表达式 表示的语言是什么?
表示由 或 组成的任意长度的字符串, 表示 或空串。因此,整个正则表达式表示由 或 组成的字符串,最后可能以 结尾。
Regular Languages
上下文无关文法(Context-Free Grammar, CFG)是一种形式文法,其特点是每个产生式的左侧只有一个非终结符,右侧可以是任意长度的终结符和非终结符的组合,形式化定义如下:
- :非终结符集合(变量)。
- :终结符集合(字母表)。
- :起始符号,。
- :产生式规则集合,形式为 ,其中 ,。
CFG 的关键特征在于其产生式规则的形式。每个产生式规则的左侧必须只有一个非终结符。规则形式通常为 ,其中 , (由终结符和非终结符组成的任意字符串)。“上下文无关”意味着无论非终结符出现在何种上下文中,都可以应用该规则进行替换。
例如,这是一个 CFG 的规则: 表示非终结符 可以被替换为 或空串 ,其中 和 是终结符, 是非终结符。
而正则文法 (Regular grammar) 是上下文无关文法的一个子集,它具有更严格的产生式规则形式。正则文法分为两种类型:
-
右线性文法 (Right-Linear Grammar): 所有产生式规则都具有以下形式之一:
- 其中 ,而 (由终结符组成的字符串)。也就是说,右侧最多出现一个变量B,且必须位于最右端。
-
左线性文法 (Left-Linear Grammar): 所有产生式规则都具有以下形式之一:
- 其中 ,而 。 也就是说,右侧最多出现一个变量B,且必须位于最左端。
一个文法如果既是右线性的又是左线性的,那么它生成的语言是正则语言 (Regular Language)。正则语言可以使用正则表达式、DFA 或 NFA 来描述,这四种描述方式是等价的。
线性文法是上下文无关文法的一个子集,其产生式规则中右侧最多只有一个非终结符,且没有位置限制,例如:
下面是一个例子:找到一个正则文法,该文法生成由{a,b}组成的偶数长度串的组成的语言。
假设是右线性文法,由偶数长度组成的串有如下可能:aa | ab | ba | bb,之后也不能加入其他的字符串了,所以文法可以是:
当然,如果是奇数长度的,我们可以在偶数的基础上修改为:,这是在之后直接偶数后加入一个字符为奇数。
Scanner
Scanner (词法分析器) 是编译器的第一个阶段,负责将源代码文件转换为 Token 序列。Scanner的主要任务是分词(Lexical Analysis),即分解源代码为 Token。
- 输入 (Input):Scanner 的输入是 文本文件 (text file),也就是程序的源代码。
- 输出 (Output):Scanner 的输出是 词法单元链表 (linked list of tokens)。 每个词法单元 (token) 代表源代码中的一个有意义的单元,例如关键字、标识符、运算符、常量等。
- 错误 (Error):Scanner 可以报告的错误主要是 词法错误 (lexical errors)。 不符合语言词法规则的字符或字符序列,例如未闭合的字符串、非法的字符等等。
- 算法 (Algorithm):
- 使用 DFA:Scanner 的核心算法是基于 确定性有限自动机 (DFA) 的设计。为每种类型的词法单元设计一个 DFA。Scanner 逐个读取输入字符,并在 DFA 的状态之间进行转移。当到达 DFA 的 接受状态 (final state) 时,就识别出了一个词法单元。例如:识别标识符的 DFA:
- 状态 0:初始状态,读取字母。
- 状态 1:读取字母或数字。
- 状态 2:接受状态,生成 ID Token。
- 括号匹配检测:使用栈数据结构。遇到左括号(
(、[、{)时,将其压入栈。遇到右括号()、]、})时,弹出栈顶元素并检查是否匹配。
- 使用 DFA:Scanner 的核心算法是基于 确定性有限自动机 (DFA) 的设计。为每种类型的词法单元设计一个 DFA。Scanner 逐个读取输入字符,并在 DFA 的状态之间进行转移。当到达 DFA 的 接受状态 (final state) 时,就识别出了一个词法单元。例如:识别标识符的 DFA:
Parser
Parser (语法分析器) 是编译器的第二个阶段,负责将 Token 序列转换为 语法树(Parse Tree)
- 输入 (Input):Parser 的输入是 词法单元列表 (token list),这是 Scanner 的输出结果。
- 输出 (Output):Parser 的输出是 语法分析树 (parse tree)。语法分析树以树状结构表示了源代码的语法结构,它体现了词法单元之间的层次关系和语法规则的应用。
- 错误(Error): Parser 主要负责检测 语法错误 (syntax errors), 这些错误指的是源代码不符合编程语言的语法规则,例如
while ( ) x >y; y = x / ;while语句的条件部分缺少了内容,并且除法运算符/后面缺少了操作数。
Parser的主要任务是:
- 语法分析:根据上下文无关文法(CFG)验证 Token 序列是否符合语法规则。
- 错误检测:检测语法错误,例如缺少分号、括号不匹配等。
- 构建语法树:将 Token 序列转换为树形结构,便于后续的语义分析和代码生成。
Parser 通常使用 上下文无关文法 (Context-Free Grammar, CFG) 来定义语法规则。语法树 (Parse Tree) 是对一个句子根据给定文法进行推导的过程的图形化表示, 它展示了如何从文法的起始符号开始,逐步应用产生式规则,最终得到该句子的过程。
绘制语法树通常遵循以下步骤:
- 确定起始符号:语法树的根节点是文法的起始符号。
- 应用产生式规则:从根节点开始,根据文法的产生式规则,将非终结符节点展开为其产生式右部的符号。
- 连接节点:将产生式左部的非终结符节点与其右部的符号节点连接起来。如果右部包含非终结符,则作为子节点;如果右部包含终结符,则作为叶子节点。
- 重复展开:重复步骤 2 和 3,直到所有的叶子节点都是终结符,并且从左到右排列这些叶子节点可以得到要分析的句子。
我们以字符串 number + number 为例,来演示如何构建语法和语法树
-
定义 CFG:
E -> T + E | TT -> number这里
E代表表达式,T代表项。 -
推导字符串:
E => T + E=> number + E=> number + T=> number + number -
绘制语法树:
- 从根节点
E开始。 - 根据推导的第一步
E -> T + E,添加子节点T、+、E。E/ | \T + E - 根据推导的第二步
T -> number,将左边的T替换为叶子节点number。E/ | \number + E - 根据推导的第三步
E -> T,将右边的E替换为T。E/ | \number + T - 根据推导的第四步
T -> number,将T替换为叶子节点number。E/ | \number + number
- 从根节点
我们在分析时,时常采用自顶向下分析 (Top-Down Parsing)。自顶向下分析是一种从语法树的根节点开始,逐步向下构建语法树的方法。其逻辑类似于对语法树进行 先序遍历 (preorder traversal),即根左右。
下面通过一道整体的例题来理解:
Question 1: for the
whilestatement, design the grammar rule
我们可以设计这样的while语句的语法:
while_statement:这是一个非终结符,代表while语句。WHILE:这是一个终结符,代表while关键字。(和):这是终结符,代表左右括号。expression:这是一个非终结符,代表while语句的条件表达式。statement:这是一个非终结符,代表while语句循环体内的语句。
while_statement --> WHILE ( expression ) statement大写字母开头的表示终结符(词法单元),小写字母开头的表示非终结符(语法变量)。标点符号可以直接作为终结符使用。
Question 2: draw the parse tree of the
whilestatement
根据这样的语法,我们可以设计出如下的parse tree:
(while-statement) / \(expression) (statement)这个树形结构表示:
- 根节点是
while-statement,代表整个while语句。 - 根节点的两个子节点分别对应
while语句的两个主要组成部分:(expression):代表条件表达式。(statement):代表循环体内的语句。
我们可以展开这样的语法树,例如,对于代码 while (x > 0) y = y - 1;,其对应的语法树可能如下:
(while-statement) / \(>) (=) / \ / \(x) (0) (y) (-) / \ (y) (1)Question 3: write the parse function of the
whilestatement
我们需要创建一个树结构的函数,一步步根据语法的顺序,编写parse function。
下面使用一个伪代码表示 while 语句的解析过程:
typedef enum {FALSE, TRUE} Bool;
Node * while_statement(Info * f, Bool * status){ // 树结构 Node *result = newNode("while"); // 创建一个新的 "while" 节点 Bool s; if(checkMove(WHILE)) // 检查当前词法单元是否是 WHILE,如果是则移动到下一个词法单元 if(checkMove(LPAR)) // 检查是否是左括号 // 解析条件表达式,并将结果作为 "while" 节点的第一个子节点 if((result->child[0] = expression(f, &s)) , s == TRUE) if(checkMove(RPAR)) // 检查是否是右括号 // 解析循环体语句,并将结果作为 "while" 节点的第二个子节点 if((result->child[1] = statement(f, &s)) , s == TRUE) { *status = TRUE; // 设置状态为 TRUE,表示解析成功 return result; // 返回创建的 "while" 节点 } printf("something wrong"); // 如果解析过程中出现错误,则打印错误信息 *status = FALSE; // 设置状态为 FALSE,表示解析失败 removeNode(result); // 移除创建的节点 return NULL; // 返回 NULL}- 创建节点:首先创建一个新的节点
result,并标记为 “while”,用于表示while语句的语法树节点。 - 检查
WHILE关键字:使用checkMove(WHILE)检查当前的词法单元是否是WHILE关键字。如果是,则将词法单元指针移动到下一个词法单元。 - 检查左括号
(:如果成功匹配WHILE,则继续使用checkMove(LPAR)检查是否是左括号(。 - 解析表达式:如果成功匹配左括号,则调用
expression(f, &s)函数解析while语句的条件表达式。expression函数会返回表示表达式语法树的节点,并更新状态s表示解析是否成功。如果表达式解析成功,则将其设置为result节点的第一个子节点 (result->child[0])。 - 检查右括号
):如果成功解析表达式,则使用checkMove(RPAR)检查是否是右括号)。 - 解析语句:如果成功匹配右括号,则调用
statement(f, &s)函数解析while语句的循环体。statement函数会返回表示语句语法树的节点,并更新状态s。如果语句解析成功,则将其设置为result节点的第二个子节点 (result->child[1])。 - 解析成功:如果所有步骤都成功,则将状态
*status设置为TRUE,并返回创建的result节点。 - 解析失败:如果在任何步骤中检查或解析失败,则打印错误信息,将状态
*status设置为FALSE,移除之前创建的result节点,并返回NULL。
除此之外,下面还提供了if、switch、if...else、 do...while和 for 语句设计语法规则、绘制语法树并编写解析函数的参考。
1. if 语句
-
语法规则:
if_statement --> IF ( expression ) statementIF:if关键字。(expression):条件表达式。statement:if条件成立时执行的语句。
-
语法树:
(if-statement)/ \(expression) (statement) -
解析函数:
Node * if_statement(Info * f, Bool * status){Node *result = newNode("if");Bool s;if(checkMove(IF)) // 关键字IFif(checkMove(LPAR)) // (if((result->child[0] = expression(f, &s)) , s == TRUE) // 表达式if(checkMove(RPAR)) // )if((result->child[1] = statement(f, &s)) , s == TRUE) { // 语句*status = TRUE;return result;}printf("if statement parsing error");*status = FALSE;removeNode(result);return NULL;}
2. switch 语句
-
语法规则:
switch_statement --> SWITCH ( expression ) { case_list default_case }case_list --> case_list CASE constant_expression : statement | ϵdefault_case --> DEFAULT : statement | ϵSWITCH:switch关键字。(expression):用于匹配的表达式。CASE:case关键字。constant_expression:常量表达式。DEFAULT:default关键字。{}:表示代码块。
-
语法树:
(switch-statement)/ | \(expression) (case-list)/ \... (default-case)/(statement) -
解析函数:
Node * switch_statement(Info * f, Bool * status){Node *result = newNode("switch");Bool s;if(checkMove(SWITCH))if(checkMove(LPAR))if((result->child[0] = expression(f, &s)) , s == TRUE)if(checkMove(RPAR))if(checkMove(LBRACE)) {result->child[1] = case_list(f, &s);if (s == TRUE) {result->child[2] = default_case(f, &s);if (s == TRUE) {if(checkMove(RBRACE)) {*status = TRUE;return result;}}}}printf("switch statement parsing error");*status = FALSE;removeNode(result);return NULL;}Node * case_list(Info * f, Bool * status) {Node *result = newNode("case_list");Bool s = TRUE;Node *current = result;while (checkAhead(CASE)) { // 假设 checkAhead 用于向前看而不移动指针Node *case_node = newNode("case");if (checkMove(CASE))if ((case_node->child[0] = constant_expression(f, &s)), s == TRUE)if (checkMove(COLON))if ((case_node->child[1] = statement(f, &s)), s == TRUE) {current->child = case_node; // 简化链表结构current = case_node;} else s = FALSE;else s = FALSE;else s = FALSE;else s = FALSE;if (!s) break;}*status = TRUE; // case_list 可以为空return result;}Node * default_case(Info * f, Bool * status) {if (checkAhead(DEFAULT)) {Node *result = newNode("default_case");Bool s;if (checkMove(DEFAULT))if (checkMove(COLON))if ((result->child = statement(f, &s)), s == TRUE) {*status = TRUE;return result;}printf("default case parsing error");*status = FALSE;removeNode(result);return NULL;} else {*status = TRUE; // default 可以不存在return NULL;}}
3. if...else 语句
-
语法规则:
if_else_statement --> IF ( expression ) statement ELSE statementELSE:else关键字。- 第一个
statement:if条件成立时执行的语句。 - 第二个
statement:if条件不成立时执行的语句。
-
语法树:
(if-else-statement)/ | \(expression) (statement) (else part) -
解析函数:
Node * if_else_statement(Info * f, Bool * status){Node *result = newNode("if_else");Bool s;if(checkMove(IF))if(checkMove(LPAR))if((result->child[0] = expression(f, &s)) , s == TRUE)if(checkMove(RPAR))if((result->child[1] = statement(f, &s)) , s == TRUE)if(checkMove(ELSE))if((result->child[2] = else_part(f, &s)) , s == TRUE) {*status = TRUE;return result;}printf("if...else statement parsing error");*status = FALSE;removeNode(result);return NULL;}
4. do...while 语句
-
语法规则:
do_while_statement --> DO statement WHILE ( expression ) ;DO:do关键字。statement:循环体内的语句。WHILE:while关键字。(expression):循环条件表达式。;:分号。
-
语法树:
(do-while-statement)/ \(statement) (expression) -
解析函数:
Node * do_while_statement(Info * f, Bool * status){Node *result = newNode("do_while");Bool s;if(checkMove(DO))if((result->child[0] = statement(f, &s)) , s == TRUE)if(checkMove(WHILE))if(checkMove(LPAR))if((result->child[1] = expression(f, &s)) , s == TRUE)if(checkMove(RPAR))if(checkMove(SEMICOLON)) {*status = TRUE;return result;}printf("do...while statement parsing error");*status = FALSE;removeNode(result);return NULL;}
for语句
-
语法规则:
for_statement --> FOR ( [expression_opt] ; [expression_opt] ; [expression_opt] ) statementexpression_opt --> expression | ϵFOR:for关键字。expression_opt:可选的表达式,用[]括起来表示可选。ϵ代表空产生式。- 第一个
expression_opt:初始化表达式。 - 第二个
expression_opt:循环条件表达式。 - 第三个
expression_opt:更新表达式。 statement:循环体内的语句。
-
语法树:
(for-statement)/ | | \(expression_opt) (expression_opt) (expression_opt) (statement) -
解析函数:
Node * for_statement(Info * f, Bool * status){Node *result = newNode("for");Bool s;if(checkMove(FOR))if(checkMove(LPAR)) {result->child[0] = expression_opt(f, &s); // 解析初始化表达式if (s == TRUE && checkMove(SEMICOLON)) {result->child[1] = expression_opt(f, &s); // 解析循环条件表达式if (s == TRUE && checkMove(SEMICOLON)) {result->child[2] = expression_opt(f, &s); // 解析更新表达式if (s == TRUE && checkMove(RPAR)) {result->child[3] = statement(f, &s); // 解析循环体语句if (s == TRUE) {*status = TRUE;return result;}}}}}printf("for statement parsing error");*status = FALSE;removeNode(result);return NULL;}Node * expression_opt(Info * f, Bool * status) {// 这里需要根据 First 集来判断是否存在 expression// 简化处理,假设存在 expression 的 First 集中的 token 就开始解析if (/* 当前 token 在 expression 的 First 集中 */ TRUE) {return expression(f, status);} else {*status = TRUE; // 允许为空return NULL;}}
总结一下我们如何绘画一个语法树:
从上开始画 (Top-Down):
- 起始于根节点:从代表文法起始符号的根节点开始。
- 根据产生式展开:根据应用的产生式规则,将非终结符节点展开为其右部的符号,并连接父子节点。
- 从左到右:通常按照产生式右部符号的顺序,从左到右添加子节点。
如我们之前的例子所示。
有一些情况下,左递归文法的语法树构建过程会从输入串的终结符开始,逐步向上归约,构建子树。例如:
additive-expression --> term | additive-expression addop term它是不断向左递归替换的,此时我们可以从终止符开始向上画:
term addop / \term term addop / \ addop term / \term term例如我们要画(5*6) + 7/8 - 6*3的语法树在这个语法中:
+ / \(5*6) 7/8 - / \ + 6*3 / \(5*6) 7/8而同理,如果是右递归文法,它不断向右替换:
additive-expression --> term | term addop additive-expression请注意,在语法树中:
- 一个非终结符节点的子节点数量直接对应于应用于该节点的产生式规则右部符号的数量
- 终结符是语法树的叶子节点,没有子节点
此外,我们再总结一下解析函数的编写方法:
-
创建节点:在函数开始时,创建一个表示当前非终结符的语法树节点。
例如:
Node *result = newNode("while"); -
匹配终结符:对于产生式右部的每个终结符,使用
checkMove或类似的函数检查当前输入的词法单元是否匹配。如果匹配,则移动到下一个词法单元;如果不匹配,则报告语法错误。 例如:在解析 while 语句时,需要匹配 WHILE 关键字和左右括号,我们使用顺序遍历每个需要解析的单元。if (checkMove(WHILE)) {if (checkMove(LPAR)) {... -
调用非终结符对应的函数:对于产生式右部的每个非终结符,调用相应的解析函数来解析该非终结符。被调用函数返回的语法树节点成为当前节点的子节点。
例如:
while语句的语法规则中包含expression和statement两个非终结符,需要调用相应的解析函数if((result->child[0] = expression(f, &s)) , s == TRUE) -
处理错误:在任何匹配或解析失败时,报告语法错误,并进行适当的错误处理(例如,同步到下一个可能正确的词法单元)。
-
返回节点:如果解析成功,则返回创建的语法树节点;如果失败,则返回
NULL或指示错误的值。 -
维护状态:使用状态变量来指示解析是否成功
Semantic Analyzer
语义分析器 (Semantic Analyzer) 的主要任务是检查程序是否符合编程语言的语义规则,这些规则无法通过上下文无关文法(CFG)完全描述。
- 输入 (Input):Semantic Analyzer 的输入是 来自 Parser 的语法树
- 输出 (Output):Semantic Analyzer 的输出是 带有语义信息的语法树和符号表。
- 错误 (Error):发现并报告语义错误,例如未声明的变量、类型不匹配等
- 算法 (Algorithm): Symbol Table / Hash Table 等
语义分析通常包括以下任务:
- 符号表管理:记录变量、函数等符号的作用域和类型信息。
- 类型检查:验证程序中所有实体的数据类型是否符合语言规则。
- 检查作用域要求:确保变量在使用前已经被声明,处理同名变量在不同作用域的遮蔽问题。
语义分析通常分为三个阶段进行:
- 初始化符号表:
- 为顶层作用域创建符号表。
- 记录全局变量和函数的声明。
- 前序遍历语法树:
- 构建符号表,检查声明和引用错误。
- 例如,检查变量是否已声明、函数参数是否匹配等。
- 后序遍历语法树:
- 进行类型检查,为表达式分配类型。
- 例如,检查赋值语句的左右类型是否一致、函数返回值类型是否正确等。
符号表(Symbol Table) 是一个链表指针数组,每一个元素记录的是一个链表的头地址。
arr[0] ---()---()---()arr[1] ---()---()---()arr[2] ---()---()---()链表中的每一个元素被称为Buckets Lists record,每个记录(或者说条目)都对应一个名字的声明.
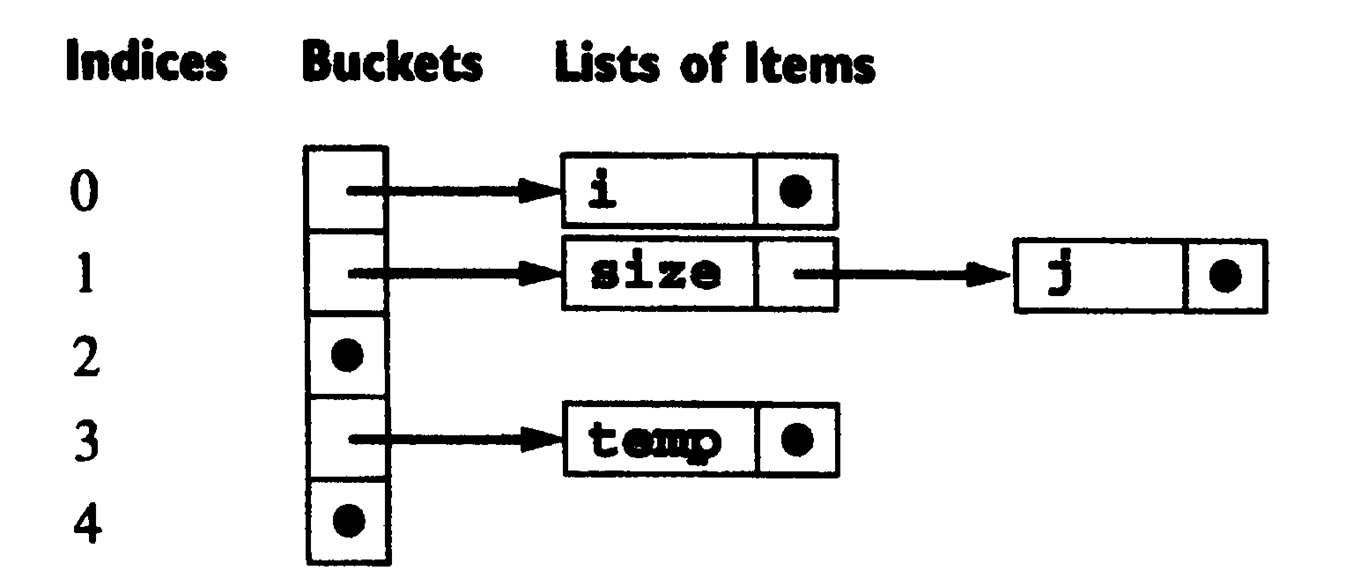
当遇到声明时,会将符号及其相关信息插入到符号表中。当遇到名字的引用时,会通过查找符号表来验证该名字是否已被声明.
哈希函数是与符号表联系在一起的, 哈希表实际上是一个由条目(称为桶,buckets)组成的数组,每个桶都有一个整数索引。哈希函数的作用是将搜索键(通常是一个字符串,例如变量名)转换成一个位于数组索引范围内的整数值(称为哈希值)
当两个不同的键被映射到相同的哈希值时,就会发生冲突。冲突时则将其加入到链表中。
哈希表的一种方法可以如下:
/*compute an integer based on a string , which is an array index.*/int hash(char * str){ int result = 0; char *t = str; while(*t != '\0'){ //result = (result + *t)*26 ; result = (result + *t)<<4 ; result = result % TABLE_SIZE; t++; } return result;}总的来说:符号表是记录了所有符号的声明信息,而哈希表则是桶的数组。
Code Generation
代码生成是编译器后端的一个关键阶段,它的任务是将中间表示(通常是抽象语法树或其变体)转换为目标机器的机器代码。TINY 机器是一个简单的虚拟机,它具有以下关键组件:
- 寄存器 (Registers): TINY 机器拥有若干通用寄存器,通常标记为
reg[0]到reg[7]。其中,有几个特殊的寄存器:- PC 寄存器(
reg[PC_R]):指向下一条要执行的指令。 - FP 寄存器(
reg[FP_R]):指向当前栈的起始位置。 - SP 寄存器(
reg[SP_R]):指向栈顶。 - AX 寄存器(
reg[AX_R]):用于存储函数返回值
- PC 寄存器(
- 指令内存 (Instruction Memory): 用于存储要执行的 TINY 机器指令。
- 数据内存 (Data Memory): 用于存储程序运行时的数据。
TINY 机器的指令可以分为两种类型:
- 寄存器操作指令 (RO Instructions): 操作数是寄存器。
HALT: 停止执行。IN r: 从标准输入读取一个整数值并存储到寄存器r中。OUT r: 将寄存器r的值输出到标准输出。ADD r, s, t: 将寄存器s和t的值相加,结果存储到寄存器r中。SUB r, s, t: 将寄存器s的值减去寄存器t的值,结果存储到寄存器r中。MUL r, s, t: 将寄存器s和t的值相乘,结果存储到寄存器r中。DIV r, s, t: 将寄存器s的值除以寄存器t的值,结果存储到寄存器r中。
- 内存操作指令 (RM Instructions): 操作数涉及寄存器和内存。
LD r, d(s): 从内存地址d + reg[s]加载值到寄存器r中。ST r, d(s): 将寄存器r的值存储到内存地址d + reg[s]中。LDA r, d(s): 将内存地址d + reg[s]加载到寄存器r中。JLT r, d(s): 如果寄存器r的值小于 0,则跳转到地址d + reg[s]。
Boot Strapping
Boot Strapping (自举) 在编译器中是 用一个简单的编译器来构建一个更复杂的编译器。这就像用一个小的工具来制造一个更大的、更强大的工具。
为什么不直接写一个复杂的编译器呢?因为最开始的时候,我们只有机器语言,也就是由 0 和 1 组成的指令。直接用机器语言编写一个复杂的编译器是非常困难的。所以,我们需要一个 Boot Strapping 的过程,来逐步构建我们的编译器。
自举的过程通常包含以下几个步骤,这些步骤可以用 “墓碑图” (Tombstone diagrams) 来表示:
-
程序(Program):内部标注程序的名称(
P)和编写语言(M)。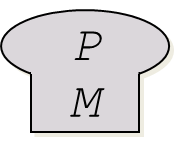
-
机器(Machine): 内部标注机器的名称(可选,
M)和运行语言(M)。
-
运行程序(Running Program):将程序框和机器框连接起来,表示程序在机器上运行。
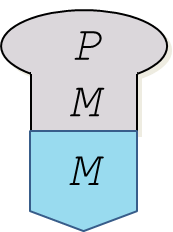
-
翻译器(Translator):表示输入语言(
S),输出语言(T)以及翻译器编写的语言(L)。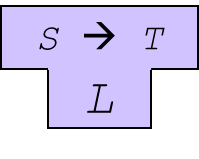
-
解释器(Interpreter):一个矩形框,表示源语言(
S)和解释语言和目标语言(L)。
Boot Strapping 通常分为以下几个步骤:
- 编写初始编译器(Compiler 1):
- 使用高级语言(如 C)编写一个简单的编译器,能够将源代码翻译为目标代码。
- 这个编译器的功能可能不够完善,但能够正确翻译代码。
- 编写简化编译器(Compiler 2):
- 使用低级语言(如汇编语言)编写一个简化版的编译器,专门用于编译 Compiler 1。
- 这个编译器的功能有限,但能够正确翻译 Compiler 1 的代码。
- 生成中间编译器(Compiler 3):
- 使用 Compiler 1 编译 Compiler 2,生成 Compiler 3。
- Compiler 3 的功能与 Compiler 1 相同,但生成的目标代码效率较低。
- 生成最终编译器(Compiler 4):
- 使用 Compiler 1 编译 Compiler 3,生成 Compiler 4。
- Compiler 4 的功能与 Compiler 1 相同,但生成的目标代码效率较高。
在之后的练习中会通过墓碑图详尽说明。
Exercise
Design DFA/NFA
根据一个语言描述去设计DFA/NFA以识别特定语言的问题,是我们最常见的问题之一。以下是通用的解决方案:
- 理解问题
- 明确语言的定义:例如,语言是否要求字符串中
a的数量为偶数,或者是否包含特定子串w。 - 确定输入符号:通常为
{a, b},但也可以是其他符号。
- 确定状态
- 状态表示:每个状态表示自动机在读取输入时的某种“记忆”。
- 状态数量:尽量使用最少的状态,以提高自动机的效率。
- 确定转移函数
- 转移规则:根据输入符号和当前状态,确定下一个状态。
- 处理特殊情况:例如,如何处理未定义的输入符号。
- 确定接受状态
- 接受条件:哪些状态表示字符串被接受。
- 拒绝条件:哪些状态表示字符串被拒绝。
常见的问题有:
1. 计数问题:偶数/奇数个 ‘a’ 和/或 偶数/奇数个 ‘b’
-
核心思想:状态表示奇偶性
最基本的情况是只考虑一个字符的奇偶性,例如,设计一个DFA识别包含偶数个 ‘a’ 的字符串。我们需要两个状态:一个表示当前已读入偶数个 ‘a’,另一个表示已读入奇数个 ‘a’。
当需要同时考虑 ‘a’ 和 ‘b’ 的奇偶性时,我们需要组合这些状态。例如,识别包含偶数个 ‘a’ 且 偶数个 ‘b’ 的字符串,我们需要四个状态,分别表示 (偶数 a, 偶数 b), (偶数 a, 奇数 b), (奇数 a, 偶数 b), (奇数 a, 奇数 b)。
-
状态转移
根据读入的字符,在表示不同奇偶性的状态之间转移。例如,在“偶数 a,偶数 b”状态下读入 ‘a’,则转移到“奇数 a,偶数 b”状态。
-
起始状态和接受状态
起始状态通常表示初始状态(例如,还未读入任何字符,‘a’ 和 ‘b’ 的计数都为零,即偶数)。
接受状态取决于具体的要求。例如,对于“偶数个 ‘a’”,所有 ‘a’ 计数为偶数的状态都是接受状态。
2. 包含子串问题:至少包含一个子串 w
-
核心思想:状态跟踪匹配进度
设计DFA的关键在于记住已经读入的、可能是目标子串前缀的部分。
对于子串 “ab”,我们需要以下状态:
- 初始状态:尚未匹配到任何部分。
- 状态1:已读入 ‘a’。
- 状态2:已读入 “ab”。
当读入的字符与子串的下一个字符匹配时,状态向前推进。
-
状态转移
- 如果当前状态表示已读入子串的前缀 P,并且下一个输入字符 c 使得 Pc 仍然是子串的前缀,则转移到表示 Pc 的状态。
- 如果输入字符不匹配,则需要转移到一个表示最长已匹配前缀的状态。例如,在匹配 “aaab” 时,如果当前在 “aa” 状态读入 ‘b’,则转移到 “a” 状态,因为 “ab” 是 “aaab” 的一个前缀。
-
起始状态和接受状态
起始状态是初始状态。接受状态是表示完整子串 w 的状态。一旦到达该状态,后续任何输入都可以保持在该状态,因为已经满足了“包含子串 w”的条件。
-
位置限制
- 开头:DFA的结构会强制从起始状态开始匹配子串。
- 结尾:在匹配到子串后,需要确保后续没有其他字符。这通常需要在匹配到子串的状态后,添加额外的状态来拒绝任何后续输入。
- 中间:允许子串前后存在其他字符,一旦匹配到子串,就可以进入接受状态。
3. 不包含子串问题:不包含子串 w
-
核心思想:状态跟踪“不匹配”的状态
这种问题可以转化为“在任何时候都不能形成子串 w”。
我们可以构建一个类似于“包含子串 w”的DFA,但其接受状态是除了表示完整子串 w 之外的所有状态。
-
状态和转移
状态和状态转移与“包含子串 w”的问题类似,用于跟踪可能形成 w 的前缀。
-
起始状态和接受状态
起始状态是初始状态。接受状态是所有不是表示完整子串 w 的状态。一旦到达表示完整子串 w 的状态,就应该进入一个非接受的“错误”状态,并且后续任何输入都停留在该状态。
下面是一个例子,
对于这样的一个问题,第一步先分析给出的条件:前缀为1,后缀为0,中间包含了110.
那么可以很快得出初始状态下对前缀的处理为:初始状态输入1进入q2,而输入0进入一个废弃状态q1. 当q2输入0的时候则打断了110的组合,此时重新计数,返回q0,输入1的话将继续转移到下一个状态。
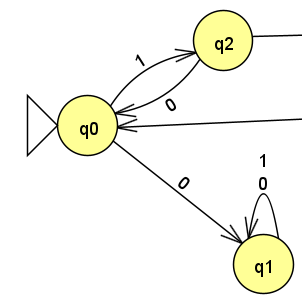
下一步,进一步构造中间项110,直到接受状态。
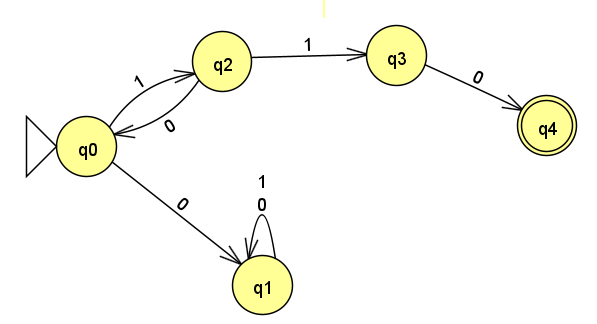
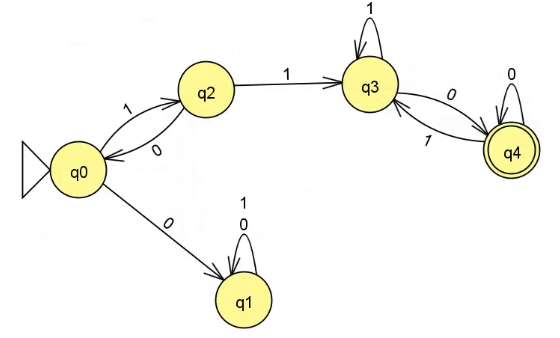
最后,补充其他状态的转移情况,保证所有状态的转移都有对应。
Describe DFA/NFA
如何用自然语言去描述所给的DFA/NFA的自动机转移图呢?核心在于理解自动机的结构和状态转移。我们可以采用如下步骤:
- 观察状态和转移:分析 DFA/NFA 的状态和转移函数,理解其行为。
- 确定接受状态:明确哪些状态是接受状态。可以找到5-10个可接受的答案,寻找规律。
- 总结模式:根据状态和转移,总结出被接受字符串的共同特征。一般来说可以从前缀,中间字符串,后缀来看。实在找不到可以描述具体的答案,使用:
like this .... or that ..... or that.....
下面是一个例子:
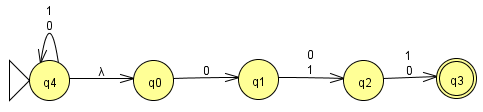
这是一个NFA,因为存在 λ 转移。起始状态是 q4,然后马上转移到q0,接受状态是 q3(双圈表示)。我们可以追踪从 q4 到 q3 的路径来找到被接受的字符串:
- q4 —λ—> q0 —0—> q1 —1—> q2 —0—> q3 => 010
- q4 —λ—> q0 —0—> q1 —0—> q2 —1—> q3 => 001
- q4 —0—> q4 —λ—> q0 —0—> q1 —1—> q2 —0—> q3 => 0010
- q4 —0—> q4 —λ—> q0 —0—> q1 —0—> q2 —1—> q3 => 0001
- q4 —1—> q4 —λ—> q0 —0—> q1 —1—> q2 —0—> q3 => 1010
- q4 —1—> q4 —λ—> q0 —0—> q1 —0—> q2 —1—> q3 => 1001
- q4 —0—> q4 —0—> q4 —λ—> q0 —0—> q1 —1—> q2 —0—> q3 => 00010
- q4 —0—> q4 —0—> q4 —λ—> q0 —0—> q1 —0—> q2 —1—> q3 => 00001
观察以上被接受的字符串,我们可以发现一些模式:
- 所有字符串都以 010 或 001 结尾。
- 在 010 或 001 之前可以有任意数量的 0 或 1(包括零个)。
根据以上分析,我们可以用自然语言描述该NFA接受的语言:该自动机接受所有由 '0' 和 '1' 组成的字符串,且这些字符串以子串 010 或 001 结尾。
NFA to DFA
NFA 和 DFA 在识别语言能力上是等价的,任何 NFA 识别的语言都可以用某个 DFA 来识别。由于 DFA 的确定性,它更容易被实现。将 NFA 转换为 DFA 的常用方法是 子集构造法 (Subset Construction)。
它的核心思想是:DFA 的每个状态对应 NFA 的一个状态集合。
具体步骤如下:
- 创建 DFA 的初始状态:DFA 的初始状态是 NFA 初始状态的 λ-闭包。λ-闭包指的是从某个状态出发,不读取任何输入符号(只通过λ-转移)能够到达的所有状态的集合。
- 生成 DFA 的状态和转移:
- 对于当前 DFA 的每个状态(一个 NFA 状态的集合),以及输入字母表中的每个符号,计算从这个 NFA 状态集合出发,经过该符号可以到达的所有 NFA 状态的集合,作为 DFA 的新状态。
- 如果新状态尚未存在于 DFA 中,则将其添加到 DFA 中。
- 确定 DFA 的接受状态:如果 DFA 的某个状态包含 NFA 的任何一个接受状态,则该 DFA 状态也是接受状态。
下面通过一个例子来解释这个过程。有个NFA的图和定义如下:
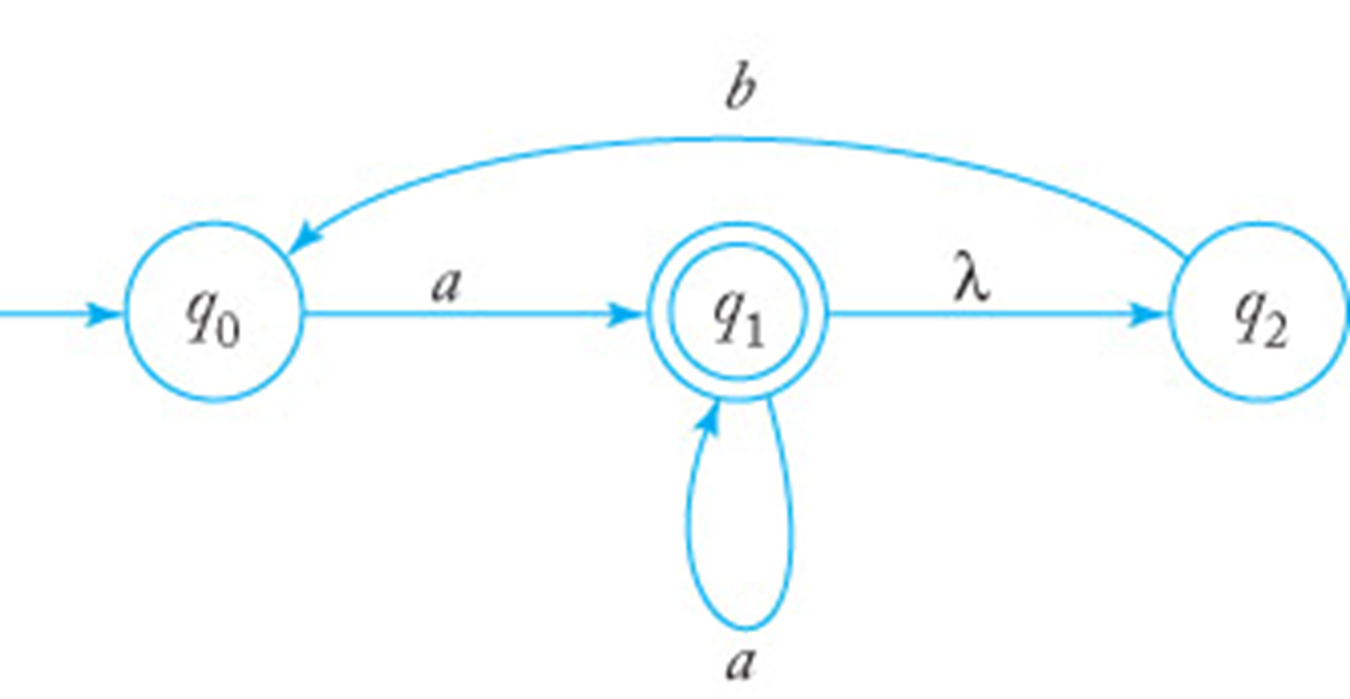
- 状态:
- 输入字母表:
- 初始状态:
- 接受状态:
- 转移函数:
-
-
-
DFA 的初始状态: NFA 的初始状态是 。 从 出发,没有 转移可以直接到达其他状态。所以 DFA 的初始状态是 。
-
构建 DFA 的状态和转移: 我们从 DFA 的初始状态开始,逐步构建 DFA 的其他状态和转移。对于 DFA 的每个已存在的状态(一个 NFA 状态的集合),以及输入字母表中的每个符号,我们计算从该状态出发,经过该符号转移后能够到达的 NFA 状态的集合,并将这个集合作为 DFA 的一个新状态。
-
从 DFA 状态 出发:读取输入符号 :。它能到达,随后可以通过 转移到达状态 。我们创建 DFA 的一个新状态 ,并添加从 到 的标有 的转移。读取输入符号 : 。我们创建 DFA 的一个新状态 ,并添加从 到 的标有 的转移。
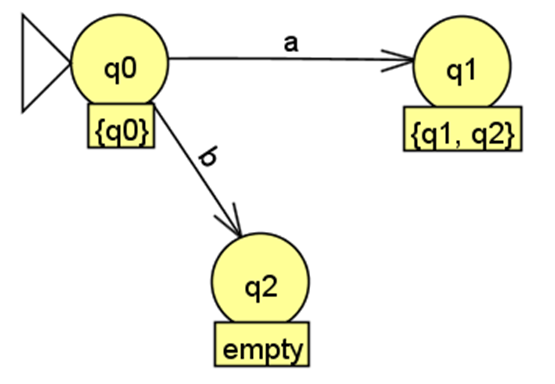
-
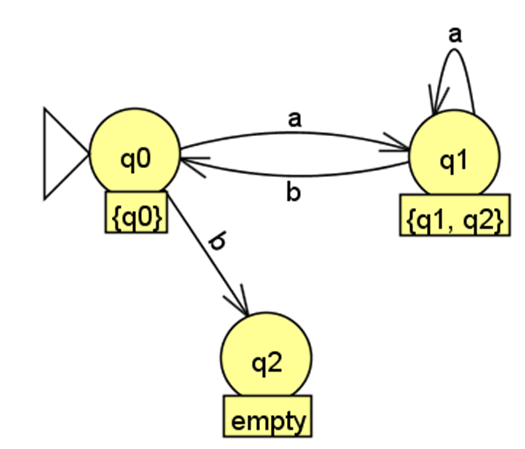
从 DFA 状态 出发:在NFA中,, . 读取输入符号 :。(即集合中每个状态分别的转移函数的交集)转移到已存在的 DFA 状态 。在NFA中,, 。读取输入符号 :。转移到已存在的 DFA 状态 。
-
从 DFA 状态 出发:读取输入符号 :。 转移到自身。读取输入符号 :。 转移到自身。
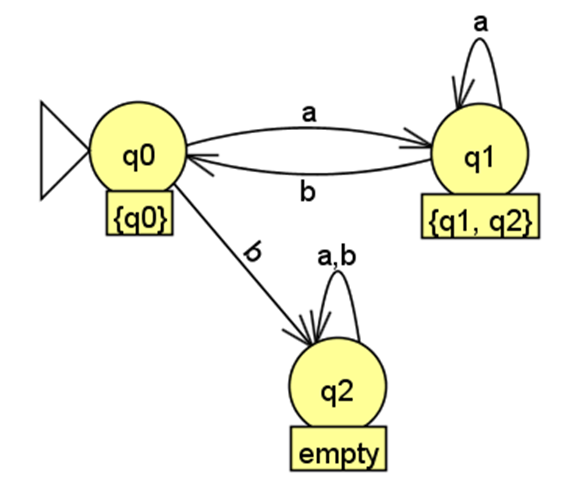
-
-
确定 DFA 的接受状态: NFA 的接受状态是 。DFA 的接受状态是所有包含 NFA 至少一个接受状态的 DFA 状态。因此,DFA 的接受状态是:
在这个转换过程中,我们首先确定了DFA 的初始状态:NFA 初始状态的 λ-闭包 (只通过λ-转移能够到达的所有状态的集合)。接下来从初始状态开始,一步步构建 DFA 的状态和转移。基本原则是上一状态集合的所有子状态在NFA中的最大转换结果(包含 转换)的并集。最后,确定 DFA 的接受状态:是所有包含 NFA 至少一个接受状态的 DFA 状态。
Write the regular expression
我们可以通过如下的步骤去分解语言到正则表达式:
-
理解语言的定义:检查语言是否要求字符串以特定子串开头或结尾,或者是否包含特定模式。确定输入符号,通常为
{0, 1}/{a, b}或其他符号。 -
分解语言:将语言分解为多个部分,开头部分、中间部分和结尾部分。分别设计正则表达式, 为每个部分设计正则表达式,然后将它们组合起来。
-
组合正则表达式:使用正则表达式运算符:
-
+:表示“或”。 -
*:表示“零次或多次”。 -
.:表示“连接”(可以省略)。 -
λ/ε:表示空字符串。
-
-
最后考虑到有没有前后重复覆盖的情况,特例的情况。例如前缀中已经包含了后缀的,需要在后面添加这个特例。
下面是一个例子:
第一步我们分解这个语言,将其分为开头,中间和结尾三个部分:
- 开头部分:字符串以
110或00或0开头。 - 中间部分:可以是任意数量的
0或1。 - 结尾部分:字符串以
0结尾。
接下来就是分别给他们设计正则表达式:
- 开头:
110或00或0可以表示为(110 + 00 + 0)。 - 中间: 任意数量的
0或1可以表示为(0 + 1)*。 - 结尾:以
0结尾可以表示为0。
将这几部分连接在一起,得到:(110 + 00 + 0)(0 + 1)*0
我们并没有考虑到如果开头的这几种情况直接接受了,所以补上一个特殊情况得到:(110 + 00 + 0)(0 + 1)*0 + (110 + 00 + 0)
当然,我们在考虑中间项和结尾的正则表达式时,也可以使用空字符串表示,这样可以得到:(110 + 00 + 0)(λ/ε + (0 + 1)*0)
Computation Tasks
编译器有几个重要阶段:词法分析器(Scanner),语法分析器(Parser),语义分析器(Semantic Analyzer)和代码生成器(Code Generator)。
1. 词法分析器 (Scanner)
-
输入 (Input): 词法分析器的输入是文本文件 (text file),也就是源代码文件。
-
输出 (Output): 词法分析器的输出是词法单元列表 (linked list of tokens)。每个词法单元代表源代码中的一个有意义的单元,例如关键字、标识符、运算符、常量等。
-
主要数据结构 (Main data structure): 词法分析器在内部可以使用确定有限自动机 (DFA) 来进行计算。DFA 可以有效地识别源代码中的词法单元。此外,为了检测括号是否匹配,可以使用栈 (stack) 这种数据结构。当遇到左括号(
[,{,()时,将其压入栈中;当遇到右括号时,从栈顶弹出元素并检查是否匹配。 -
可能出现的错误 (Errors that can be found): 词法分析器主要负责识别源代码中的非法字符或不符合词法规则的模式。一个例子是在 C 语言中使用了不允许的字符,例如
@xy。 另一个例子是括号不匹配,例如(]或{)。
2. 语法分析器 (Parser)
-
输入 (Input): 语法分析器的输入是词法单元列表 (token list),这是词法分析器的输出。
-
输出 (Output): 语法分析器的输出是语法分析树 (parse tree)。语法分析树以树状结构表示源代码的语法结构,它反映了词法单元之间的层次关系。
-
主要数据结构 (Main data structure): 语法分析树的节点 (node) 是其主要的数据结构。每个节点代表一个语法结构,例如表达式、语句等。节点的具体结构取决于所使用的语法分析方法。
-
可能出现的错误 (Errors that can be found): 语法分析器负责检查词法单元序列是否符合编程语言的语法规则。常见的错误包括语法错误,例如
while ( ) x >y; y = x / ;中缺少条件表达式或运算符。
3. 语义分析器 (Semantic Analyzer)
- 输入 (Input): 语义分析器的输入是语法分析树 (parse tree),这是语法分析器的输出。
- 输出 (Output): 语义分析器的输出是带有语义信息的语法分析树或者中间表示形式。 这通常包括类型信息、符号表信息等。
- 主要数据结构 (Main data structure): 符号表 (symbol table) 是语义分析器最重要的数据结构之一。符号表用于存储程序中使用的标识符的信息,例如变量名、函数名、类型、作用域等。符号表通常以哈希表 (hash table) 的形式实现,以便快速查找。
- 可能出现的错误 (Errors that can be found): 语义分析器负责检查程序的语义是否正确,例如类型不匹配、未声明的变量、函数调用参数不匹配等。
4. 代码生成器 (Code Generator)
- 输入 (Input): 代码生成器的输入是带有语义信息的语法分析树或者中间表示形式,这是语义分析器的输出。
- 输出 (Output): 代码生成器的输出是目标代码 (target code)。目标代码可以是汇编代码、机器代码或者其他中间语言。
- 主要数据结构 (Main data structure): 代码生成器可能需要维护一些数据结构来管理寄存器分配、内存分配等信息。
- 可能出现的错误 (Errors that can be found): 代码生成器可能遇到的错误包括无法分配寄存器、目标平台不支持的操作等。例如,对于一个简单的加法操作
x + y,代码生成器会生成相应的汇编指令,例如add r2, r2, r3。
常见的输出有:List of Tokens (Scanner), Parse Tree (Parser), Symbol Table (Semantic Analyzer),下面是一些例子用于表示他们。
对于一个if语句,如下:
if (x > y) { x = 1; x = x + y;}我们可以很快得到如下的语法树:
if_stmt / \ (x > y) cmpd_stmt=> if_stmt / \ > cmpd_stmt / \ | x y = <---> = / \ / \ x 1 x = / \ x y其中,我们把if的语句分成了左右两个部分,分别是判断的语句和复合的处理语句。接下来再对它们进行细分。在每一项中,采用中序遍历(左根右) 的形式写出这个树。其中,<--->展示兄弟姊妹关系。
而对于Symbol Table,它是一个链表数组,数组是一个哈希数组,链表中记录着每一个名字的定义。然后链表的节点中又有一个链表去记录该名字的其他信息,例如行数等,如下例子:
array of buckets[][][] bucketListRec[]---{}---{}---{x}---{}[] \() \() lineListRec. \()其中,这里的哈希数组可以嵌套,例如我们可以给一个作用域一个Symbol Table,作用域内的作用域嵌套Symbol Table。
Interpreter vs Compiler
还有一个常见的问题是:解释器(Interpreter)和编译器(Compiler) 的相同点和区别。
相同点 (Similarities)
- 都是翻译器 (Both are translators): 解释器和编译器本质上都是翻译器,它们都将源代码(通常是高级语言)转换为另一种形式。
- 都需要进行词法分析,语法分析,语义分析等步骤: 无论是解释器还是编译器,都需要对源代码进行词法分析,语法分析,语义分析等步骤,以理解源代码的结构和含义。
区别 (Differences)
| 特性 (Characteristic) | 编译器 (Compiler) | 解释器 (Interpreter) |
|---|---|---|
| 翻译方式 (Translation Method) | 将整个源代码翻译成目标代码(如机器码或字节码),这个过程通常在程序运行之前完成。 | 逐行或逐语句地翻译源代码并立即执行,不会生成独立的目标代码文件。 |
| 目标代码 (Target Code) | 生成独立的目标代码文件(如 .obj,.exe 文件)。 这个目标代码可以直接被计算机执行(或经过链接后执行)。 | 不生成独立的目标代码文件,而是在运行时直接执行翻译后的指令。 |
| 执行方式 (Execution) | 编译后的目标代码可以独立运行,无需编译器在场。程序执行速度相对较快。 | 需要解释器在场才能执行代码。每次执行都要重新解释,速度通常比编译型语言慢。 |
| 错误检测 (Error Detection) | 编译器通常会在编译时检测出大部分语法和语义错误,并报告错误。 | 解释器在运行时检测错误,如果某行代码出现错误,则会停止执行。 |
| 适用场景 (Use Cases) | 适用于需要高性能和独立运行的场景,例如操作系统、游戏、大型应用程序等。 | 适用于快速原型开发、脚本语言、动态语言等场景,例如 Web 开发、数据分析、自动化脚本等。 |
| 例子 (Examples) | C, C++, Java(编译成字节码,然后由 JVM 解释执行)等。 | BASIC, LISP, Python, JavaScript 等。 |
简单来说:
- 编译器将整个程序翻译成机器可以理解的目标代码,然后执行。
- 解释器逐行或逐语句翻译并执行代码。
Boot Strapping
我们的目标是产生一个效率高的编译器,如下表示:
Goal: (X:[all] --> M:[high] ) / M:[high]自举的过程通常包含以下几个步骤:
-
写一个简单的编译器
我们首先需要用高级语言 (X) 编写一个编译器 (1)。 这个编译器可以把一种高级语言 (X) 高效地翻译成机器语言 (M)。这个编译器 (1) 的描述可以表示为:
(1): (X:[all] --> M:[high] ) / X: (correct & high)X表示输入语言,M表示输出语言。X:[all]表示这个编译器可以处理所有用X语言编写的程序。M:[high]表示生成的机器代码的质量较高(效率较高)。/ X: (corrent & high)表示编译器 (1) 本身是用X语言编写的,且质量也较高。
这个编译器是用于生成与编译器相同的高级语言的翻译的。
-
用 X 语言编写一个更强大的编译器
接下来,我们使用机器语言去编写一个简单的编译器 (2)。 这个编译器 (2) 可以把编译器 (1)的代码翻译成机器语言 M。这个编译器 (2) 的描述可以表示为:
(2) (X:[only for (1)] --> M:[low] ) / M: (correct & low)X:[only for (1)]表示这个编译器只能处理特定的X语言程序,即编译器 (1) 的源代码。M:[low]表示生成的机器代码的质量较低(效率较低)。/ M: (correct & low)表示编译器 (2) 本身是用机器语言编写的,且效率和质量也较低。
这个编译器 (2) 的目标是能够编译步骤 1 中的编译器 (1) 的源代码。所以,即使编译器 (2) 本身功能不强,但只要能编译编译器 (1) 就足够了。
-
运行编译器 (2) 编译编译器 (1)
现在,我们使用编译器 (2) 去编译编译器 (1) 的代码。 这会生成一个新的编译器 (3),它的描述可以表示为:
(3) (X:[all] --> M:[high] ) /M:[low]- 这个编译器 (3) 的功能是去编译编译器 (1) 的代码,所以保持编译器 (1) 的输入输出,并保持编译器 (2) 的body。
M:[low]表示编译器 (3) 本身是用机器语言编写的,且质量较低。
编译器 (3) 是用机器码,因为此时是使用了编译器(2)编译的,所以编译编译器 (1) 的效率是低的。这是在低效地生成可直接运行的高效编译器 (1).
-
用编译器 (3) 编译编译器 (1)
运行编译器 (3),并将编译器 (1) 的源代码再次作为输入。这将生成最终的编译器 (4)
(4) (X:[all] --> M:[high] ) /M:[high]-
这个编译器 (4) 的功能和编译器 (1) 相同,即把
X语言翻译成M语言,并且可以处理所有用X语言编写的程序。 -
M:[high]表示编译器 (4) 本身是用机器语言编写的,且质量也较高。 编译器 (3) 编译了编译器 (1),生成了一个高效的编译器 (4),因为 (1) 在X下是高效的,直接运行 (4) 便是高效地编译原语言X。
通过以上步骤,我们成功地使用一个简单的编译器 “自举” 出一个更强大的编译器 (4) 去翻译这个 X。
Hashing
在编译器中的语义分析器Semantic Analyzer,我们使用哈希表作为Symbol Table,哈希函数将字符串转换成数字的下标进行存储,常见的哈希函数如下:
#define SIZE ... // 哈希表的大小int hash (char * key) { int val = 0; int i = 0; while (key[i] != '\0'){ val = ((val << 4) + key[i]) % SIZE; // 相当于将哈希值乘以 16, 然后加上当前字符的 ASCII 值, 最后取模 i ++; } return val;}Design Grammar for Language
如何设计一个尊重运算符优先级和结合性的语法呢?
设计方法遵循:
- 将高优先级的运算符放在语法规则的较低层级。
- 运算符结合性决定了相同优先级的运算符的计算顺序。
例如:对于一个支持加法、减法、乘法和除法的语法。
expr -> expr addop term | term // 加法和减法,优先级较低。term -> term mulop factor | factor //乘法和除法,优先级较高。factor -> NUMBER | ( expr ) // 处理数字和括号表达式。addop -> + | -mulop -> * | /例如:3 + 5 * 2
+ / \ 3 * / \ 5 2乘法节点 * 位于加法节点 + 的下方,表示乘法先计算。
还有一个例子是一个支持幂运算的语法,幂运算是右结合的。
expr -> term addop expr | termterm -> factor mulop term | factorfactor -> power | NUMBER | ( expr )power -> NUMBER powop power | NUMBER // 处理幂运算,通过右递归实现右结合性。powop -> ^对于2 ^ 3 ^ 2,幂运算节点 ^ 是右结合的,因此 3 ^ 2 先计算,再计算 2 ^ (3 ^ 2)。
^ / \ 2 ^ / \ 3 2此外还有逻辑与、逻辑或这样的类似语法,逻辑与优先级高于逻辑或。
Write Parse Functions
给定一个语句,我们需要写出自顶向下的Parse Function 去生成这样的Parse Tree。
-
创建节点:在函数开始时,创建一个表示当前非终结符的语法树节点。
例如:
Node *result = newNode("while"); -
匹配终结符:对于产生式右部的每个终结符,使用
checkMove或类似的函数检查当前输入的词法单元是否匹配。如果匹配,则移动到下一个词法单元;如果不匹配,则报告语法错误。 例如:在解析 while 语句时,需要匹配 WHILE 关键字和左右括号,我们使用顺序遍历每个需要解析的单元。if (checkMove(WHILE)) {if (checkMove(LPAR)) {... -
调用非终结符对应的函数:对于产生式右部的每个非终结符,调用相应的解析函数来解析该非终结符。被调用函数返回的语法树节点成为当前节点的子节点。
例如:
while语句的语法规则中包含expression和statement两个非终结符,需要调用相应的解析函数if((result->child[0] = expression(f, &s)) , s == TRUE) -
处理错误:在任何匹配或解析失败时,报告语法错误,并进行适当的错误处理(例如,同步到下一个可能正确的词法单元)。
-
返回节点:如果解析成功,则返回创建的语法树节点;如果失败,则返回
NULL或指示错误的值。 -
维护状态:使用状态变量来指示解析是否成功
例子在Parser处。
Building a Symbol Table
符号表通常被组织成一个由桶 (buckets) 组成的数组,每个桶可以链接一个记录列表 (BucketListRec)。 为了处理作用域 (scope),每个符号表可能会有一个指向其父作用域符号表的链接 (parent)。 这种结构可以有效地支持符号的查找和管理,特别是对于存在嵌套作用域的语言。
构建符号表通常在语义分析阶段进行,并且通常使用对抽象语法树 (AST) 的先序遍历 (pre-order traversal) (根左右,因为先声明后使用)。以下是构建符号表的主要步骤:
- 创建顶层作用域的符号表: 在开始遍历语法树之前,首先为全局作用域创建一个符号表,并将其设置为当前符号表。
- 先序遍历语法树: 从语法树的根节点开始进行先序遍历。对于遍历到的每个节点,执行以下操作:
- 遇到声明: 如果当前节点表示一个声明(例如,变量声明、函数声明),则检查该符号是否已经在当前作用域中声明过。
- 如果已经声明过,则报告重复声明错误。
- 如果没有声明过,则创建一个新的符号表条目(
BucketListRec),并将符号的相关信息(例如,符号名、类型、作用域等)存储在该条目中。然后将该条目插入到当前符号表中对应的桶中。 同时,将该符号表条目的地址关联到语法树节点。
- 进入新的作用域: 如果当前节点引入一个新的作用域(例如,函数声明、复合语句),则创建一个新的符号表,并将当前符号表的
parent指针指向旧的符号表,然后将新的符号表设置为当前符号表。 - 离开作用域: 当完成对一个作用域内所有节点的处理后(在先序遍历的相应返回点),将当前符号表恢复为父符号表。
- 遇到声明: 如果当前节点表示一个声明(例如,变量声明、函数声明),则检查该符号是否已经在当前作用域中声明过。
下面是一个检查是否声明的例子:
BucketListRec *lookup(const char *name, SymbTab *tb) { int v = hash(name); BucketListRec *p = searchInBucket(name, tb->array[v]); // 在指定的桶中查找符号 while (p == NULL && tb != NULL) { // 没找到 tb = tb->parent; // 查找父符号表 p = searchInBucket(name, tb->array[hash(name)]); } return p;}Type Checking
类型检查是编译器语义分析阶段的一个重要组成部分。它的主要目标是验证程序中的操作是否符合语言的类型规则,从而确保程序在运行时不会出现类型错误。
类型检查通常在构建符号表之后进行,并且通常使用对抽象语法树 (AST) 的后序遍历 (post-order traversal) (左右根,因为先检查子类型)
- 后序遍历语法树: 从语法树的叶子节点开始进行后序遍历。对于遍历到的每个节点,执行以下操作:
- 基本类型: 如果当前节点表示一个常量或标识符,则根据其字面值或符号表中的信息确定其类型。
- 表达式: 如果当前节点表示一个表达式,则根据其子节点的类型和运算符的类型规则来推断当前表达式的类型。
- 例如,对于一个二元运算表达式
E1 op E2,首先递归地检查E1和E2的类型。然后,根据运算符op的定义,检查E1和E2的类型是否与op兼容。 如果兼容,则确定整个表达式的类型;否则,报告类型错误。
- 例如,对于一个二元运算表达式
- 语句: 如果当前节点表示一个语句,则检查语句中涉及的表达式的类型是否符合语句的语义规则。
- 例如,对于赋值语句
variable = expression,需要检查expression的类型是否与variable的类型兼容2。 - 对于函数调用,需要检查实际参数的类型和数量是否与函数声明的形式参数匹配。
- 例如,对于赋值语句
- 类型等价性: 在类型检查过程中,经常需要判断两个类型是否相同。类型等价性的判断可以有多种方式,例如名称等价 (name equivalence) 和 结构等价 (structural equivalence)。
- 错误报告: 如果在类型检查过程中发现任何违反类型规则的情况,编译器将报告类型错误。
void typeChecking (Node *np){ if(np == NULL) return; for each child c of np typeChecking(c); // 先处理子节点 typeChecking(np);}Recursive Functions
递归是一种解决问题的方法,其核心思想是将一个大问题分解成与原问题相似但规模更小的子问题来解决1。在编程中,递归表现为函数调用自身.
我们以计算阶乘为例来说明递归:
int factorial(int n) { if (n == 0 || n == 1) { return 1; } else { return n * factorial(n - 1); }}尾递归是一种特殊的递归形式。如果一个函数中递归调用是其执行的最后一个操作,也就是说在递归调用之后没有其他的运算操作了,那么这个递归调用就是尾递归。上面这个递归不是尾递归。如果使用尾递归:
int factorial_tail(int n, int accumulator) { if (n == 0) { return accumulator; } else { return factorial_tail(n - 1, n * accumulator); }}尾递归的优势在于某些编译器可以对其进行尾调用优化 (Tail Call Optimization)。对于普通的递归,每次函数调用都需要在栈上创建一个新的栈 (frame)来保存局部变量和返回地址, 当递归深度很大时,可能会导致栈溢出.
而对于尾递归,由于递归调用是最后的操作,编译器可以将当前的函数调用直接替换为对下一个递归调用的跳转,而无需创建新的栈 (frame)。 无论递归深度多大,都只会占用一个栈帧。
Generate Assembly Code
为 TINY 机器生成代码通常涉及以下步骤4:
- 处理变量声明: 为局部变量和全局变量分配内存空间4。局部变量通常分配在栈帧上。
- 处理表达式: 将算术表达式、逻辑表达式等转换为一系列 TINY 机器指令,使用寄存器进行临时存储和计算4。
- 处理控制流语句:
if语句: 生成比较指令和条件跳转指令 (JLT等) 来实现条件执行。while语句: 生成循环开始的标签、循环体代码以及条件跳转指令来实现循环控制。
- 处理函数调用:
- 调用序列 (call sequence): 在调用函数之前,需要将参数压入栈中,保存返回地址,并跳转到被调用函数的入口地址。
- 启动序列 (start sequence): 在函数入口处,需要保存旧的帧指针 (FP),更新帧指针,并为局部变量分配空间。
- 结束序列 (end sequence): 在函数返回之前,需要将返回值存储到指定寄存器,恢复栈指针 (SP) 和帧指针 (FP),并跳转回调用者的返回地址4。
- 处理函数返回: 生成指令将返回值放到指定位置,并执行返回操作。
以下 C 函数计算从 0 到 n 的和:
int sum(int n) { int result = 0; while (n >= 0) { result = result + n; n = n - 1; } return result;}以下是针对这个 C 函数生成的 TINY 机器代码:
; 函数调用前的准备工作ST FP_R, 0(SP_R) ; 保存旧 FPLDA SP_R, 4(SP_R) ; 更新 SPLDA FP_R, -4(SP_R) ; 更新 FP
; 初始化局部变量 resultLD 0, 0(0) ; 将 0 加载到 reg[0]ST 0, 0(SP_R) ; 将 0 压入栈LDA SP_R, 4(SP_R) ; 更新 SP
; while 循环LOOP:LD 0, -8(FP_R) ; 加载 n 到 reg[0]LD 1, 4(FP_R) ; 加载 result 到 reg[1]LDC 2, 1(0) ; 加载常量 1 到 reg[2]JLT 0, END_LOOP ; 如果 n < 0,跳转到 END_LOOP
; 循环体ADD 1, 1, 0 ; result = result + nSUB 0, 0, 2 ; n = n - 1ST 1, 4(FP_R) ; 更新 resultST 0, -8(FP_R) ; 更新 nJMP LOOP ; 跳回 LOOP
; 循环结束END_LOOP:LD AX_R, 4(FP_R) ; 将 result 加载到 AX_RLD FP_R, 0(FP_R) ; 恢复 FPLD PC_R, -4(SP_R) ; 恢复 PC- 启动序列: 保存旧的帧指针,设置新的帧指针,并为局部变量
result在栈上分配空间。 - 循环代码: 使用
JLT指令实现条件跳转,使用LD、ADD、SUB指令实现循环体中的计算。 - 结束序列: 将返回值加载到寄存器,恢复栈指针和帧指针,并跳转回调用者。
总结一下:
-
将当前 FP 压入栈,以便函数返回时能恢复上下文。将 FP 指向新栈帧的起始位置。
ST FP_R, 0(SP_R) ; 保存旧 FPLDA SP_R, 4(SP_R) ; 更新栈指针 SPLDA FP_R, -4(SP_R) ; 更新 FP -
计算参数并压入栈: 将函数参数的值计算出来,并压入栈中。
LD 0, 0(0) ; 将参数值加载到 reg[0]ST 0, 0(SP_R) ; 将参数值压入栈LDA SP_R, 4(SP_R) ; 更新栈指针 SP
