

文章目录
前言
本章总结了估计算法运行时间的几种重要方法 - Substitution method (代入法), Recursion-tree method (递归树法) and Master method (主方法)。
此外,本章还以经典的排序算法 - 插入排序、归并排序、快速排序为例,应用上述的运行时间估计方法,分析其性能。
本章基于 “Introduce to Algorithm 4th” (《算法导论》第四版) 的 Chapter 3 - Chapter 7。笔记内容仅为个人见解,加入了一些可能不正式甚至不正确的个人见解,请勿过分解读,若存在异议,欢迎与我交流。
NOTE课程资料:
TIP本章及 “算法设计与分析” 专题中,所提到的 均表示为 以2为底 的对数,即 。
本章基于 【算法设计与分析】分治法 和 【算法设计与分析】快速排序与排序分析 进行重写和改进,并拓展了一些示例。
可以通过下面的连接快速跳转到示例:
下面是正文部分。
分治法 / Divide-and-Conquer
当一个问题足够大,且可以分解为若干个和当前问题形式一致的子问题时,我们可以使用递归的方法去求解它。我们通常使用如下三步去求解这样的递归问题 (recursive case):
- 分解 (Divide): 将原问题分解为若干子问题,形式与原问题一致,但规模更小。
- 解决 (Conquer): 递归求解子问题。
- 合并 (Combine): 将子问题的解合并为原问题的解。
我们可以用一系列函数符号来表示递归的通式,于是我们得到了递归式的定义:
Definition - RecurrenceA recurrence is an equation that describes a function in terms of its value on other, typically smaller, arguments.
递归式 (recurrence) 是一个通过函数在较小的参数上的取值来描述一个函数的等式。
通过递归式的定义,我们可以使用数学方法去描述分治算法运行时间。
Definition - Algorithmic Recurrences对于一个算法,它的递归式 对于任意足够大的阈值常量 满足如下两个性质:
- 对于所有 , .
- 对于所有 , 每条递归路径都在有限次的递归调用后,终止于某个已定义的基本情况 (1)。
于是,估计分治算法的运行时间转换成了解递归式的边界。教科书中提供了四种方法去解递归式:
- 代入法 / Substitution method: 使用 数学归纳法 去猜测递归式的边界,并通过推导去证明。
- 递归树法 / Recursion-tree method: 将递归式转化为递归树,计算不同层次结点递归的代价去计算递归式的边界。
- 主方法 / Master method: 通过主方法,将递归式中的参数替换为实际参数的值,并求解。
- Akra-Bazzi方法: 通过微积分的方法处理更为通用且复杂的递归式。该方法是主方法的一般形式,在本章中不会过多介绍。
代入法 / Substitution method
代入法 (Substitution method) 是使用数学归纳法去猜测递归式边界,并通过推导去证明。它的基本思路是:
- 使用常数符号去猜测递归式 。
- 使用数学归纳法求出解中的常数,并证明解的正确。
无渐进符号递归式
我们通过如下一个例子来展示代入法的过程:
我们把 代入到递归式 中,得到 。
因为递归式很多情况下与对数函数有紧密关系,我们可以猜测 .
应用数学归纳法:
- 当 时,.
- 当 时,假设 成立,则 可以表示为:
证明成功。
带有渐进符号的递归式
然而,猜测成功是代入法非常关键的一步,如果我们要解这样如下的递归式:
你也许会无从猜测它的形式,因为它带有 。于是我们有另一种猜测的方法就是先证明递归式的边界,然后不断缩小不确定的范围。
对于上述递归式,我们可以 用 代替渐进符号 (因为 是最基础的 的形式, 是一个常数)。
当我们求解该递归式的上界的时候,即求解:.
我们可以继续运用代入法,只是从等式变成了不等式,猜测 , 为一个正的常数。
和之前一样,对它进行数学归纳法证明:
- 当 时,,是个常数,符合 特征。
- 当 时,假设 成立,则 可以表示为:
那么我们可以说,当 时,,即 的上界可以写为 。
同理我们还可以证明其下界,用 表示,猜测 ,得到 。
于是我们可以得到 。
需要减去低阶项的递归式
你也许会发现,有时已经正确猜测出渐进边界,但是无法通过数学归纳法去证明,例如:
.
我们可以猜测它的上界是 。
像之前一样应用数学归纳法, 尝试证明对于某个恰当的参数 , 能解出 :
- 当 时,,是个常数,符合 特征。
- 当 时,假设 成立,则 可以表示为:
此时我们会发现,好像不存在什么参数的取值能使不等式配平为 ,就差一个常数项 。
因此,我们可以尝试利用待定系数法的思想,减去一个低阶项。我们的新猜测为:, 为一个正的常数,用来代替 。
再次尝试数学归纳法:
- 当 时,,是个常数,符合 特征。
- 当 时,假设 成立,则 可以表示为:
那我们就可以说,当 大于 中的一个常数时, 成立,即 。
常见错误
我们证明的时候可能会出现一些常见的问题,例如:,猜测
- 直接带入渐进符号:. 因为此时 所隐藏的系数不断变化,无法确定 所隐藏的系数一定大于 ,表达式不一定成立 。
- 不替换渐进符号:. 因为我们 并非证明出与归纳假设严格一致的形式 ,我们必须要显式证明出 。
递归树法 / Recursion-tree method
使用代入法正确猜测递归式的边界可能比较困难,但是递归树方法 (Recursion-tree method) 却可以解决这个问题。对于递归式求解问题,我们大多数都可以使用递归树方法计算做出猜测,最后使用代入法去验证。
在递归树中,每个结点表示一个单一子问题的代价(需要时间),子问题对应某次递归函数的调用。我们将树中每层中的代价求和,得到每层代价,然后将所有层的代价求和,得到所有层次递归调用的总代价。
递归树方法 (Recursion-tree method) 的基本思路是:
- 构建递归树: 将递归式转换成递归树。
- 计算递归树中代价:计算递归树中每层的代价、树的高度。
- 代价求和:将每层的代价求和,得到所有层代价的总和,即为递归函数的总运行时间。
我们通过一个例子来演示递归树法的过程:
.
我们用 表示递归式中的 , 为一个正的常数。我们可以使用 去构建递归树。
- 构建递归树:根节点中的 表示递归调用顶层的代价,根的三个子树表示规模为 的子问题所产生的代价。
因为我们递归有3个,故从 处可以分成三个分支:

又可以通过 得到,。故每个 又可以有三个分支:

同理我们可以继续分 ,直到最后抵达不可递归的条件,此时递归树为:

- 递归树中代价的计算:
观察递归树,我们可以计算每层 (用深度来表示以匹配指数, 根结点的深度为 0) 的代价:
- 第
1层的代价: - 第
2层的代价: - 第
3层的代价:
可以推广到第i层的代价:
这样的规律可以一直推广到第 h - 1 层,h 为递归树的总深度。而最后一层的代价则可以通过 最后一层的节点数量 来计算。
接下来我们可以通过递归树中节点的规模来计算递归树的深度 。
观察递归树可以知道,每个子结点规模为父结点的 ,那么可以推算子节点的规模:
- 第
1层的子结点规模为 , - 第
2层的子结点规模为 - 第
3层的子结点规模为
可以推广到第i层的子结点规模:. 在最后一层,子节点不需要继续递归了,此时规模为 .
于是,在最后一层拥有的子节点规模:
我们得到递归树的深度 。
有了深度的表达式后,可以得出第0层到第h - 1层的代价表达式。要计算总代价,我们还需要最后一层的节点数量才能计算最后一层的代价。
观察递归树每层的节点数量,可以发现:
- 第
0层的节点数量: - 第
1层的节点数量: - 第
2层的节点数量: - 第
3层的节点数量:
在第 i 层,节点数量为 。那么最后一层的节点数量为 。
所以最后一层的代价为:,于是我们可以计算总代价。
- 代价求和:
我们可以发现,在第0层到第h - 1层,代价是一个等比数列:
- 第
0层的代价: - 第
1层的代价: - 第
2层的代价: - 第
3层的代价: - 第
i层的代价: - 第
h - 1层的代价:
而最后一层代价根据换底公式:
总代价为:
到这一步,我们已经成功使用参数去表示这个递归式。接下来的解需要使用微积分的知识,使用一个无穷范围以消除指数。

我们在实际情况中,可能还会遇到递归树节点参差不齐的情况,例如:
.
这种情况下的递归树子节点的代价不一样,因为其节点的规模一个为父节点的 , 一个是父节点的 。我们按照之前的步骤,可以画出如下的递归树:

我们可以分别计算最浅节点和最深节点的深度:
- 节点规模为 的节点的深度 :
- 节点规模为 的节点的深度 :
因为 ,故规模为 的节点的深度更深,图会往右下展开。
在计算每层代价的时候,我们可以发现,它应该是一个分段的函数:
- 当深度 时,代价为 .
- 当深度 时,代价 .
但是我们还是没法确定每层代价的表达式,只能估计一个模糊的边界。于是,我们假设两个在深度为 和 的满二叉树去估计该递归式的下界和上界。
-
当一颗满二叉树的深度为 时,最后一层节点全是 。它是下界的理想情况。
它最后一层的节点数量为 ,此时最后一层的代价为:
于是该满二叉树的总代价为:
-
当一颗满二叉树的深度为 时,最后一层节点数量为 ,此时最后一层的代价为:
于是该满二叉树的总代价为:
所以综合起来,我们可以猜测递归式的解为:
因为是一个粗略的边界,我们需要使用代入进行验证。即证明:, 是个正的常数。用 代替 ,上界为:
同理,可以验证其下界,最后得到递归式解为:
主方法 / Master method
主方法主要来自于递归树法的总结,适用于求解下面格式的递归式:,.
称为 驱动函数(driving function),它是一个渐进非负函数。它是基础情况下的代价。
这个通式我们可以得到以下信息:
- 子问题数量:
- 子问题规模:
- 递归树的深度:
- 递归树深度第
i层的结点个数: - 递归树最后一层的结点个数:
若最后一层结点都是 ,则递归树最后一层的代价为:
而其他层结点的代价为:
那么最终的代价可以表示为:
对于这样的递归式,它的边界由 和 中 的 指数大 的那个决定。于是我们可以进行分类讨论,即主方法的定义:
DefinitionCase 1: () 若存在一个常数 使得 ,则递归式的解为 。这种情况下代价主要来源于 叶子节点。
Case 2: () 若存在一个常数 使得 ,则递归式的解为 。这种情况下每一层的代价基本相等为 ,而其高度可以表示为 。
Case 3: () 若存在一个常数 使得 ,且 在 足够大时满足条件 时,递归式的解为 。这种情况与情况一正好相反,代价主要来源于 根节点。
下面三个例题分别是对应了三种不同情况下的主方法的应用:
分析可知:, 。很明显,,可以使用主方法中的情况1,得到
分析可知:, 。此时在增长率上,,它们增长率相当,适用于情况2,得到 。
分析可知:, 。很明显,,且此时满足 ,此时 。可以使用主方法中的情况3,得到 。
但是主方法并不能覆盖所有的递归式,它会出现空隙无法使用。
- 当 与 两个函数无法比较时。
- 当 时,情况一和情况二之间会有一个间隙, 多项式的增长速率不大于 的多项式的增长速率。
- 当 时,情况二和情况三之间会有一个间隙, 多项式的增长速率不小于 的多项式的增长速率。
解决这类递归式可以尝试使用其他方法,或Akra-Bazzi 递归式,这里不在正文处涉及。
Exercises in Divide-and-Conquer
下面我们通过一些练习,去加深对解递归式的三种方法的理解。
证明: 的解为
因为题目要求我们证明的是 ,故需要分上下界进行讨论。
- 对于上界:
我们可以设存在常数 和 , 对于所有 ,都有 .
假设对于所有的 , 成立,所以
代入原递归式得到:
为了使这个不等式在 , 足够大时成立,这个二次函数的开口需要向下,即:
因此在 时,
- 对于下界:这一部分与上界基本一致。
设存在常数 和 , 对于所有 ,都有 .
假设对于所有的 , 成立,所以
代入原递归式得到:
为了使这个不等式在 , 足够大时成立,这个二次函数的开口需要向上或为一次函数,即:
所以当满足 时,
综上,
对于递归式 ,使用递归树法,给出解的渐进边界。
将该递归式转化为递归树,如下图:
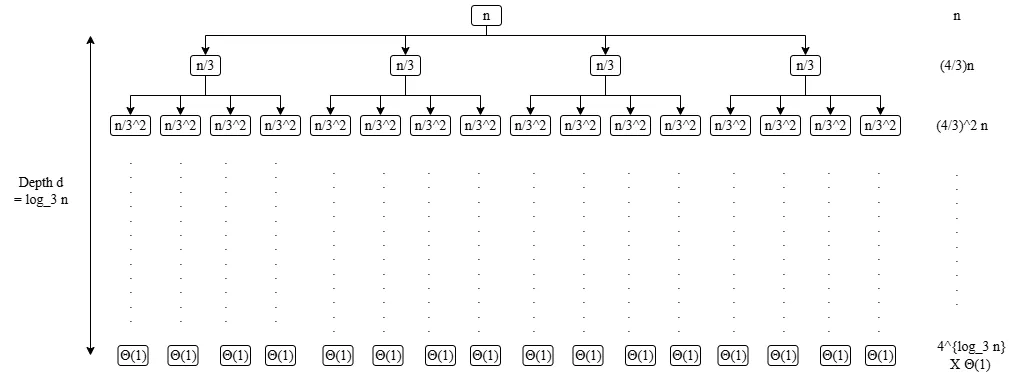
我们可以通过这个图计算出:
- 递归树的深度为:
- 递归树中第
i层的结点数: - 最后一层的代价为:
观察到代价是一个等比数列,所以我们整理可以得到总代价:
因为 ,所以
对于递归式 ,使用递归树法,给出解的渐进上界。
将该递归式转化为递归树,如下图:
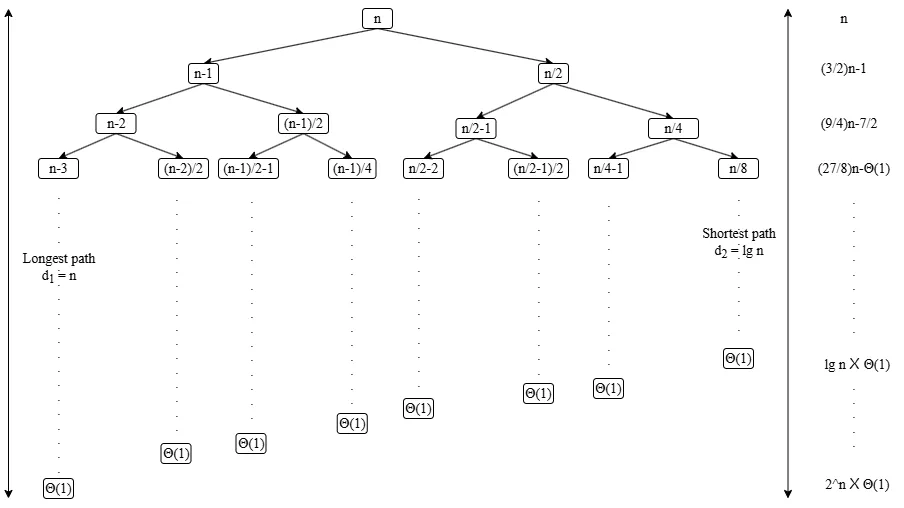
这个递归图比较奇怪,左侧减的没有右侧加的到底快,我们只能估计它的边界。
本题需要我们求它的上界,即取最长的路径作为树的深度进行计算。可以得到:
- 递归树的深度 (最深的路径边数) 为:
- 递归树中
d_1层的结点数:
观察到代价中n的系数是一个等比数列,后面跟着的是一个常数。我们可以忽略这个常数,得到总代价:
观察到代价由 和 中大的那个决定,因为 , 在 足够大时, 。所以
对于递归式 ,使用主方法求出渐进边界。
我们对比分水岭函数 和 驱动函数 的大小:
可以发现 ,说明递归树中每一层的代价都差不多。存在一个 , 使得 。
可以应用主方法的Case 2,得到
Master Method - Case 2Case 2: () 若存在一个常数 使得 ,则递归式的解为 。这种情况下每一层的代价基本相等为 ,而其高度可以表示为 。
对于递归式 ,使用主方法求出渐进边界。
我们对比分水岭函数 和 驱动函数 的大小:
可以发现两个函数之间相差了一个 ,与Case 2相似:存在一个 , 使
所以
对于递归式 ,使用主方法求出渐进边界。
我们对比分水岭函数 和 驱动函数 的大小:
因为 ,与Case 3相似。
进一步检测: ,存在一个常数 使得正则条件成立。
所以
Master Method - Case 3Case 3: () 若存在一个常数 使得 ,且 在 足够大时满足条件 时,递归式的解为 。这种情况与情况一正好相反,代价主要来源于 根节点。
对于递归式 ,使用主方法求出渐进边界。
我们对比分水岭函数 和 驱动函数 的大小:
明显:,与Case 1相似。
存在一个常数 ,使
所以
Master Method - Case 1Case 1: () 若存在一个常数 使得 ,则递归式的解为 。这种情况下代价主要来源于 叶子节点。
Summary
总结一下本节内容:本节主要介绍了三种解递归式的方法 - 代入法、递归树法和主方法。
好的,以下是《算法导论》(第4版)第4章中三种求解递归式方法的总结:
- 代入法 (Substitution Method): 本质上是一种 数学归纳法。可以用来证明任何递归式的解,最大的难点在于需要 提前猜测 出解的正确形式。
解法步骤:
- 猜测 (Guess): 凭借经验或使用递归树法,猜测解的渐近形式,例如 。
- 归纳假设 (Assume): 假设猜测对于所有小于 的 成立,即 (对于 界)。
- 证明 (Prove): 将归纳假设代入原递归式,通过数学推导证明 也成立。
- 求解常数与边界: 在推导过程中,需要找到一个合适的常数 和 ,使得不等式对于所有 成立,并确保解对边界条件也有效。
- 配平: 有时为了使归纳成立,你需要从猜测中减去一个低阶项,例如猜测 而不是 。
- 递归树法 (Recursion-Tree Method): 它非常直观,将递归式的代价在树的各个层级上进行可视化展开。适用于分析分治算法的递归式,特别是 形式。
解法步骤:
- 构建树: 画出递归树。根节点代表 的代价,它有 个子节点,每个子节点代表规模为 的子问题,代价为 ,依此类推。
- 计算层代价: 计算树的第 层的总代价(通常是 )。
- 计算树深度 (高度): 确定树的深度 (通常是 )。
- 计算叶子代价: 确定叶子节点的总数(通常是 )以及它们的总代价(通常是 )。
- 求和: 将所有层(从根到叶子之前的所有内部节点)的代价与叶子层的总代价相加。
- 分析总和: 分析这个总和的渐近界,从而得出 的猜测。
- 主方法 (Master Method): 本质上是递归树法中三种常见情况(代价由叶子主导、由根主导、或均匀分布)的数学归纳总结。仅 适用于 形式的递归式,其中 , 是渐近正函数。
解法步骤:
- 确定参数: 找出 , , 和 。
- 计算关键函数: 计算 。
- 比较 和 :
- Case 1 (叶子主导): 如果 对于某个 成立(即 在多项式意义上大于 ),则 。
- Case 2 (代价均衡): 如果 对于某个 成立(即 和 渐近相等,或只差一个 因子),则 。
- (最常见的子情况 :若 ,则 )。
- Case 3 (根代价主导): 如果 对于某个 成立(即 在多项式意义上大于 ),并且 满足 正则条件 (regularity condition)(即 对于某个 和足够大的 成立),则 。
- 注意: 如果 和 的关系落入上述三种情况的“间隙”中(例如 比 大,但不是多项式意义上的大),则主方法失效,必须退回使用递归树法或代入法。
经典排序算法
在已经学习了分治算法中递归式的三种解法,但只是在理论上讨论,本节将回顾几种常见的排序算法 - 插入排序、归并排序、快速排序和快速选择排序,并适当应用之前所学的递归式解法,给出其性能分析。
插入排序 / Insertion sort
插入排序是最基础的排序算法,其时间复杂度为 。下面是插入排序的伪代码:
INSERTION-SORT(A, n) for i = 2 to n key = A[i] j = i - 1 while j > 0 and A[j] > key A[j + 1] = A[j] j = j - 1 A[j + 1] = key很明显的能看到,插入排序有两个循环体,一个用于比较,一个用于交换。在最坏的情况下,
最好情况则是当待排序序列为正序状态,则遍历完整个序列,当插入元素时,只比较一次就够了,所以此时复杂度为 。
基础的插入排序没有使用递归算法,我们可以用递归的方法代替循环体:为了排序 A[1,n],我们递归地排序A[1,n-1],然后把A[n]插入已排序的数组A[1,n-1]。
每一次递归中,我们都需要插入元素到有序数组中,这个过程需要一个循环。我们用递归代替外层循环,递归每次规模为 ,于是我们就可以得到下面的伪代码:
INSERTION-SORT(A, n) if n < 2 return INSERTION-SORT(A, n-1) temp = A[n] i = n - 1; while i > 0 if A[i] < temp break A[i + 1] = A[i] i = i - 1 A[i + 1] = temp我们可以用这样的递归式表示它的运行时间:
我们分析它非常简单,对它画递归树,是一条直线:
除了最后一层外是一个等差数列,有 项,求和得
插入排序的优化
在子数组已经排序的情况下,我们可以用 二分查找(binary search)找到要插入的区间,使得插入排序的效率提升。
如果序列A已排好序,就可以将该序列的中点与v进行比较。根据比较的结果,原序列中有一半就可以不用再做进一步的考虑了。二分查找算法重复这个过程,每次都将序列剩余部分的规模减半。
用循环二分找到区间的伪代码为:
BINARY-SEARCH(A, left, right, x) if left > right return NIL mid = ⌊(left + right) / 2⌋ if A[mid] == x return mid else if A[mid] > x return BINARY-SEARCH(A, left, mid - 1, x) else return BINARY-SEARCH(A, mid + 1, right, x)二分算法中每一次都尽可能的分成 一个 n/2 规模的子问题 (因为二分查找中另一半不需要查找,所以规模缩小为 而不是 )。可以得到如下的递归式:
。根据Master method case 2,, 则此时 。
我们仅仅只是优化了查找时间,我们插入的步骤还涉及到其他元素的向后移动,这个过程也是 的,导致无法将时间复杂度降低至 ,插入排序在二分查找下仍然是 的算法。
归并排序 / Merge sort
归并排序是分治算法的典型应用,它的时间复杂度为 。它的伪代码:
MERGE-SORT(A, p, r) if p ≥ r return q = ⌊((p + r) / 2)⌋ MERGE-SORT(A, p, q) MERGE-SORT(A, q + 1, r) MERGE(A, p, q, r)它的原理是:假如初始序列含有 n 个记录,则可以看成是 n 个有序的子序列,每个子序列的长度为 1。然后两两归并,得到 n/2 个长度为2或1的有序子序列;再两两归并,……,如此重复,直到得到一个长度为 n 的有序序列为止。
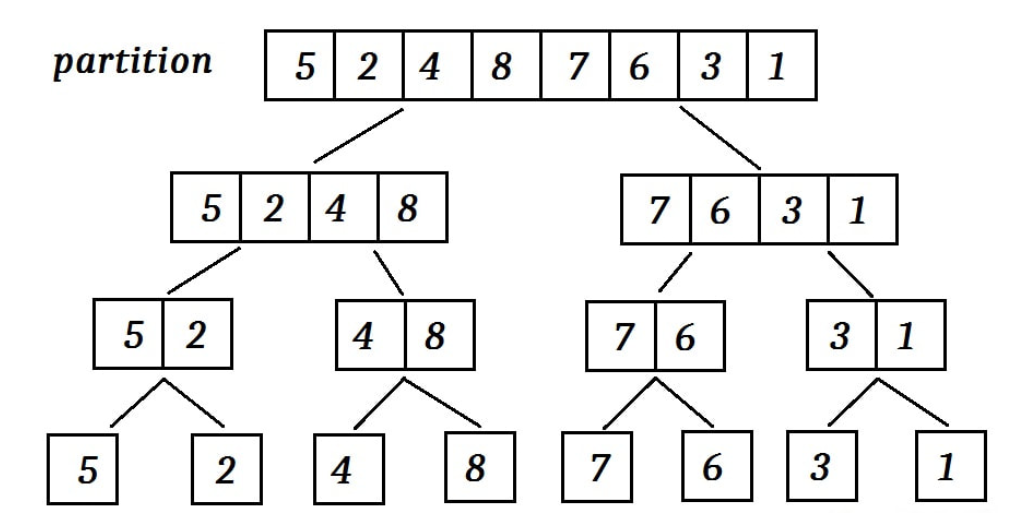
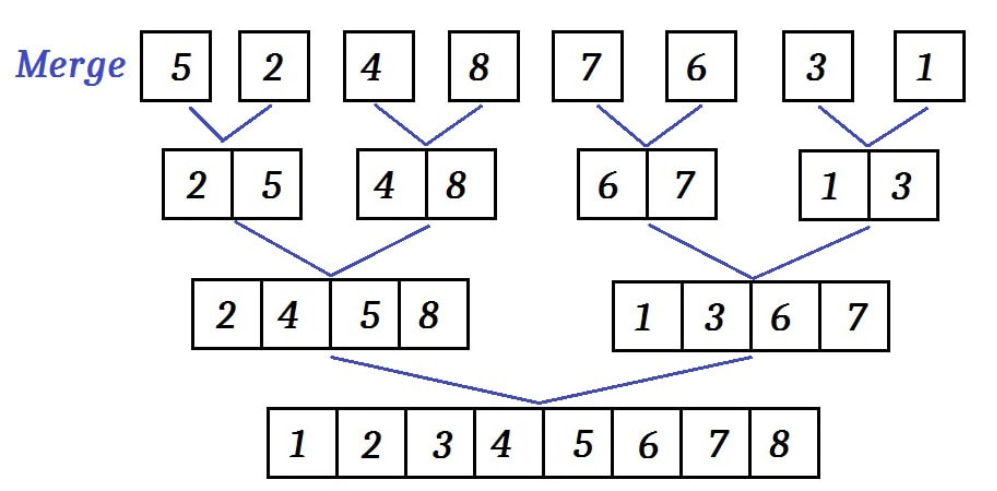
分析这个算法,若分的序列规模足够小,即 时,本身就是有序的,此时 ;
一般情况下,每次递归大致都是对半分,然后对两个一般再分,此时可以看做分为了两个规模为 的子问题()。递归最后还需要计算合并的时间,我们来看合并部分的代码:
MERGE(A, p, q, r) nL = q - p + 1 //左半部分长度 nR = r - q //右半部分长度 let L[0 : nL - 1] and R[0 : nR - 1] be new arrays for i = 0 to nL - 1 //单独把左半部分放入一个数组 L[i] = A[p + i] for j = 0 to nR - 1 //单独把右半部分放入一个数组 R[j] = A[q + j + 1] i = 0 j = 0 k = p //记录原来A数组的索引 while i < nL and j < nR //逐位比较 if L[i] ≤ R[j] //如果左半部分这一位小于右半部分这一位 A[k] = L[i] //则把左半部分这一位放回原数组中 i = i + 1 else A[k] = R[j] //否则放右半部分那一位 j = j + 1 k = k + 1 while i < nL //如果j先到了nR,即左半部分有剩余,右半部分放完了 A[k] = L[i] //把左半部分剩余的接过去 i = i + 1 k = k + 1 while j < nR //如果i先到了nL,即右半部分有剩余,左半部分放完了 A[k] = R[j] //把右半部分剩余的接过去 j = j + 1 k = k + 1观察其合并的过程,可以知道,合并是一个逐位比较的过程,其中通过索引判断是否放完。很明显,这是个 的算法。
故对于归并排序:
分析这个算法,我们可以直接使用Master method case 2,,则它的时间复杂度为
或者使用递归树法:
令:
画一个递归树
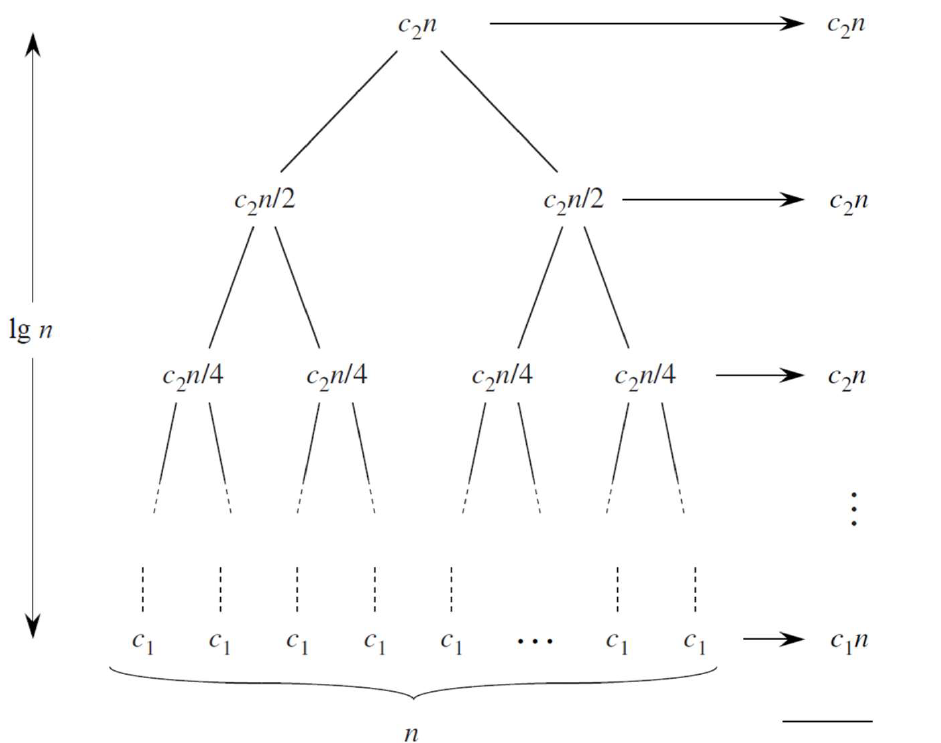
(在该图中,用 表示 )
我们可以从递归树中得到如下信息:
- 递归树深度:
- 递归树在第
i层的结点数: - 递归树在第
d层的结点数:
对于每一层,代价之和都是 ,而在最后一层则为 ,于是总代价为:
所以,在 时,有
同理可以证出:当 时,
故最后,归并排序的时间复杂度为 。
快速排序 / Quicksort
快速排序采用分治思想,一般分为三个步骤:
- 分解(Divide):子数组
A[p...r]根据 pivot(主元)A[q]进行分解,小于pivot的元素放到数组A[p:q-1]中, 大于pivot的元素放在A[q+1:r]中。 - 解决(Conquer):通过递归调用快速排序实现对
A[p:q-1]和A[q+1:r]的排序。 - 合并(Combine):因为子数组都是原值排序,此时
A[p:r]有序。
于是下面就是简单的快速排序的伪代码:
QUICKSORT(A, p, r) if p < r q = PARTITION(A, p, r) QUICKSORT(A, p, q - 1) QUICKSORT(A, q + 1, r)这个排序中我们只做了分解这件事,此时p是起始索引,r为结束索引,q是每个划分中的pivot。接下来再对子数组进行快速排序。
接下来,就是最关键的分组:
PARTITION(A, p, r) x = A[r] //我们默认选取最后一位为pivot i = p - 1 //i为此时lower side的最高位索引,初始化为数组0位 for j = p to r - 1 //p到r-1的元素进行分组 if A[j] ≤ x //若当前元素比pivot小 i = i + 1 //引索移动 exchange A[i] with A[j] //交换位置,即把元素放到A[p:i]里面去 exchange A[i + 1] with A[r] //循环结束,把pivot放到中间去 return i + 1 // new index of pivot我们一步步来看这个分组部分的代码,例如数组{2,8,7,1,3,5,6,4}的第一次分组:
-
确定初始化
i,j,r位置,i代表的是lower side的最高位索引,此时还没有则为0;j此时是位置1,r在最后。我们用浅色表示还没处理的部分。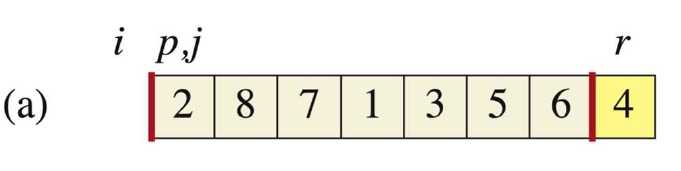
-
当
j=1时,此时A[j]=2 < A[r],则移动i(i++到1的位置),并且让A[i]与A[j]交换,此时i=j=1,则不动。操作完后j++。我们用橙色表示比r小的部分。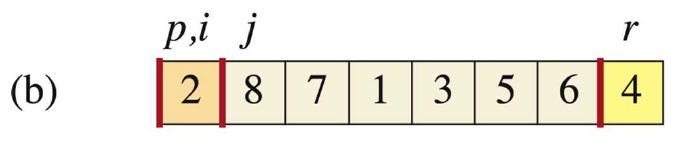
-
当
j=2时,此时A[j]=8 > A[r],此时i不动,j++。我们用蓝色表示比r大的部分。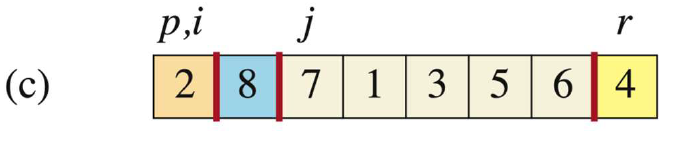
-
当
j=3时,此时A[j]=7 > A[r],此时i不动,j++。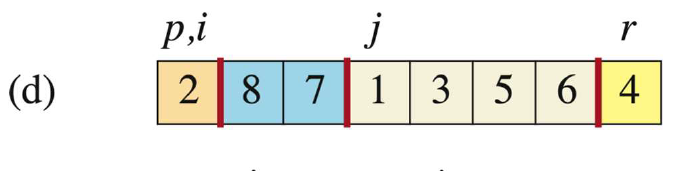
-
当
j=4时,此时A[j]=1 < A[r],则移动i(i++到2的位置),并且让A[i]与A[j]交换,即A[2]与A[4]交换(2与8交换)。操作完后j++。
-
当
j=5时,此时A[j]=3 < A[r],则移动i(i++到3的位置),并且让A[i]与A[j]交换,即A[3]与A[5]交换(3与7交换)。操作完后j++。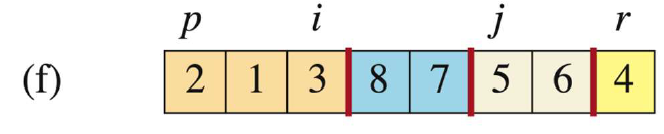
-
当
j=6时,此时A[j]=5 > A[r],此时i不动,j++。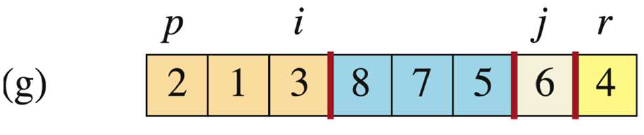
-
当
j=7时,此时A[j]=6 > A[r],此时i不动,j++。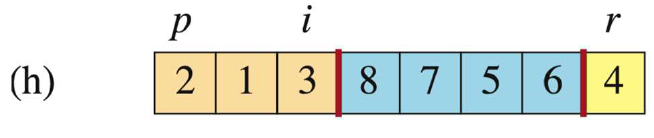
-
j=8 > p-1=7,跳出循环。把i+1位置(3+1 = 4,这是大于pivot的子数组的首元素地址)上的元素与pivot交换。(这样交换能保证pivot左边比pivot小,pivot右边比pivot大)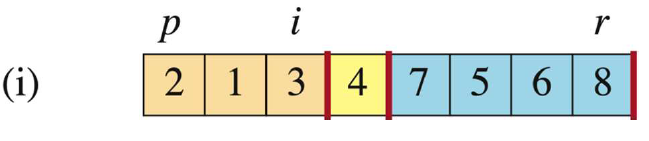
PARTITION 的过程中只有一个循环,很容易知道它的时间复杂度为 。
快速排序的性能分析
最坏情况出现在每次划分都极度不平衡时,即:
- 一侧子数组有 n-1 个元素
- 另一侧子数组有 0 个元素
例如:数组已经 完全有序(升序或降序)、数组所有 元素相同 或每次 pivot 都是 当前子数组的最大或最小值 时出现最坏情况。
最后一层数组大小为空,则为T(0) = 0,则时间复杂度可以写为:
根据代入法,很容易得出它的最坏情况为 。下面是证明:
猜测 ,,则
, 。
所以,当 时,
同理可以代入下界,有 .
所以,当 时,
此时最坏情况为 。
而快速排序最好的情况是在 最平衡的划分,即:
- 两侧子数组大小相等(或相差1)
- pivot 正好是中位数
两个子问题都不大于n/2,均可看成对半划分,则
根据Master method,,应用Case 2,得到此时最好的情况为 。
此外,到一般的情况情况下,快速排序的平均情况的运行时间更接近于最好情况的运行时间,而不是最坏情况的运行时间之间。
在平均情况下,好的划分和坏的划分是随机分布的,假设好的划分是最好情况划分,坏的情况是最坏情况划分,当好坏划分交替出现时,一个坏的划分和一个好的划分等价于一个好的划分,所以,快速排序的平均情况的运行时间很可能是 ,只是隐藏的常数因子比最好情况的隐藏的常数因子略大。
随机快速排序
与始终采用 A[r] 作为主元的方法不同,随机快速排序是从子数组 A[p..r] 中 随机选择一个元素作为主元。我们称其为随机抽样(random sampling)。
为达到这一目的,首先将 A[r](最后一位)与从 A[p..r] 中随机选出的一个元素 交换 。通过对序列 A[p..r] 的随机抽样,我们可以保证主元元素 x=A[r] 是等概率地从子数组的 r-p+1 个元素中选取的。
我们修改一下我们的快速排序即可:
PARTITION(A, p, r) x = A[r] i = p - 1 for j = p to r - 1 if A[j] ≤ x i = i + 1 exchange A[i] with A[j] exchange A[i + 1] with A[r] return i + 1
RANDOMIZED-PARTITION(A, p, r) i = RANDOM(p, r) exchange A[r] with A[i] return PARTITION(A, p, r)
RANDOMIZED-QUICKSORT(A, p, r) if p < r q = RANDOMIZED-PARTITION(A, p, r) RANDOMIZED-PARTITIONQUICKSORT(A, p, q - 1) RANDOMIZED-PARTITIONQUICKSORT(A, q + 1, r)RANDOMIZED-PARTITION 将任意常数比例的元素划分到一个子数组中。则算法的递归树的深度为 ,并且每一层上的工作量都是 。即使在最不平衡的划分情况下,会增加一些新的层次,但总的运行时间仍然保持是 。
最坏情况下,RANDOMIZED-PARTITION 被调用 ,解得 。这说明随机快速排序 不会 使得快速排序的最坏情况运行时间更优。
最好情况下,与快速排序相同,RANDOMIZED-PARTITION 被调用 ,解得 。
最好情况和最坏情况RANDOMIZED-PARTITION被调用次数都是 ,这并非巧合,因为数组中每个元素都可能被选为pivot。
快速选择算法 / Quick Select
基于随机快速排序,有一种期望为线性时间 ( ) 的 选择算法 - RANDOMIZED-SELECT。
RANDOMIZED-SELECT(A,p,r,i) 将找到并返回数组 A[p..r] 中第 i 小的元素。并不需要排序所有的元素,而是找到第 i 小的元素。
它的思路也很简单:我们知道快速排序算法中经过 PARTITION 划分得到 A[p..q-1] 和 A[q+1..r] 两个子数组,以及主元 A[q] 的位置。接下来再递归地去处理 A[p..q-1] 和 A[q+1..r] 中的元素,并找到它们的主元。
划分结束后的主元位置将不会被改变,因为 A[p..q-1] 中都是比 A[q] 小的元素,A[q+1..r] 中都是比 A[q] 大的元素。
于是,我们就可以在这里找到第 i 小的元素,而不需要完全处理完划分。
所以这个选择算法又称为 快速选择算法。下面是它的伪代码:
PARTITION(A, p, r) x = A[r] i = p - 1 for j = p to r - 1 if A[j] ≤ x i = i + 1 exchange A[i] with A[j] exchange A[i + 1] with A[r] return i + 1
RANDOMIZED-PARTITION(A, p, r) i = RANDOM(p, r) exchange A[r] with A[i] return PARTITION(A, p, r)
RANDOMIZED-SELECT(A, p, r, i) if p == r return A[p] q = RANDOMIZED-PARTITION(A, p, r) k = q - p + 1 if i == k return A[q] // the pivot value is the answer elseif i < k return RANDOMIZED-SELECT(A, p, q - 1, i) else return RANDOMIZED-SELECT(A, q + 1, r, i - k)接下来通过一个例子去展示它的运行过程:
假设
A = [6, 19, 4, 12, 14, 9, 15, 7, 8, 11, 3, 13, 2, 5, 10](索引从1开始),需要找到最小的第5个数。
初始状态下,调用:RANDOMIZED-SELECT(A, 1, 15, 5) 并且递归调用 RANDOMIZED-PARTITION 选中的主元为 14,并将它与 A[15] 交换位置。
- 第一次
RANDOMIZED-PARTITION调用PARTITION,得到如下的状态:
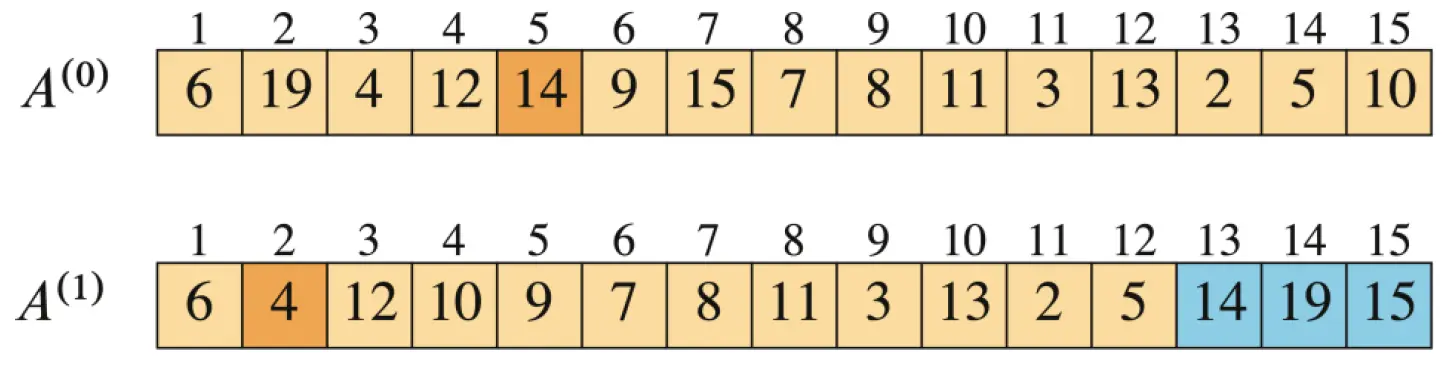
其中:浅色部分为当前轮次中参与 PARTITION 的数组元素,加深的元素表示 RANDOMIZED-PARTITION 选中的下一次 PARTITION 的主元。蓝色部分的元素表示不参与下一次 PARTITION 的元素,因为需要选择的 i 不在蓝色的范围内。
q = 13, 因此,下次将处理 A[1,12],继续找第 5 个数。
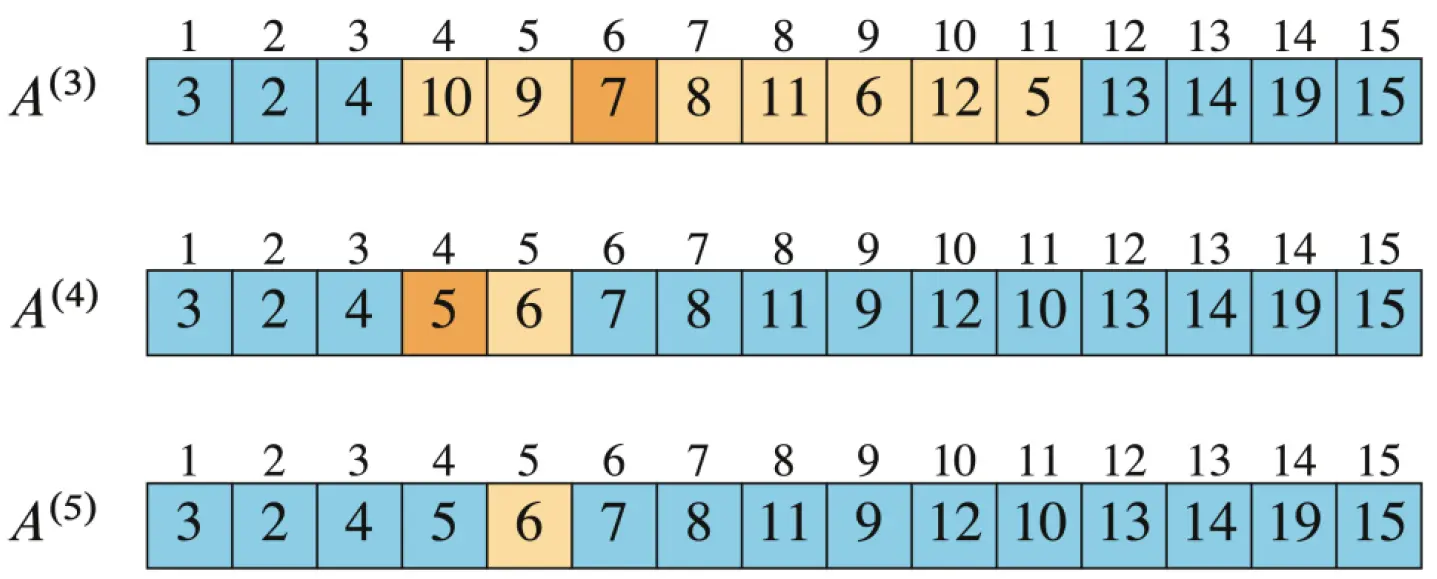
- 第二次
RANDOMIZED-PARTITION交换主元后调用PARTITION,得到如下情况:

q = 3,接下来处理 A[4,12],继续找第 5 - 3 = 2 个数。
- 接下来的情况同理,直到剩余的元素已经全部处理完毕,返回第
5个数。
接下来我们分析这个算法。如果每次划分枢轴都很不巧地选择了剩余元素中的最大值就会出现 最坏情况,此时划分序列恰为输入序列的 降序排序。
此时运行时间和快速排序的最坏情况一样,递归式为
RANDOMIZED-SELECT 在平均情况下的期望时间为 ,此处不进行证明。
Exercises in Sort Methods
有一种排序算法叫
Stooge-Sort,以喜剧团队“三个臭皮匠”的名字命名。(a). 请给出
STOOGE-SORT最坏情况运行时间的递归式及其解。 (b). 将STOOGE-SORT的最坏情况运行时间与插入排序、归并排序和快速排序进行比较,并给出结论。
这一题给出了一个排序算法的伪代码,需要我们分析代码得到递归式,并应用解递归式的方法来求解最坏情况运行时间。
观察伪代码可以发现,这个算法是递归的,并且每次递归调用都会产生三个新的递归调用。此外,一次调用中的运行时间代价为 。
根据我们的经验,最坏的情况一般发生在已经有序的时候。我们代入一些数据来看看递归的规模如何,例如 A = [1,2,3,4,5,6,7,8,9,10] (以1为起始索引) STOOGE-SORT(A, 1, 10)
- 若
A[1] > A[10]则交换A[1]和A[10],这里无事发生。 - 若
i + 1 >= 10则返回,这里是检测是否结束递归。 k <- ⌊(10-1+1)/3⌋ = 3取了三分位数。- 递归调用
STOOGE-SORT(A, 1, 7),这里将递归排序三分之二的值。 - 递归调用
STOOGE-SORT(A, 4, 10),这里将递归排序三分之二的值。 - 递归调用
STOOGE-SORT(A, 1, 7),这里将递归排序三分之二的值。
那么我们可以得出结论,每次递归调用的规模是父递归调用的 。我们的递归式为:
解这样的递归式我们可以使用主方法 Case 1:分水岭函数为 ,驱动函数 .
显然,
此时存在 ,使得 。
题目还要求我们对比该算法与插入排序、归并排序和快速排序的最坏情况运行时间:
- 插入排序最坏情况运行时间:
- 归并排序最坏情况运行时间:
- 快速排序最坏情况运行时间:
因为 ,所以 Stooge-Sort 的最坏情况运行时间比插入排序、归并排序和快速排序要长。
如果在归并排序中对小数组 (长度为
k) 采用插入排序,找到在最坏情况下合并子表的运行时间表达式,并且找到如何采用合适的参数k使得修改后的归并排序运行时间与原本的归并排序运行时间相同。
虽然插入排序的最坏情况运行时间 比归并排序的最坏情况 运行时间差,但插入排序在数据量很小时在许多机器上运行的更快()
所以我们可以用插入排序修改归并排序的递归树。使其不要到只有一个元素再进行合并,而是到一个设定的数组长度时,最小的子数组(归并段)执行插入排序,设最小子数组(归并段)长度为 k ,分成 n/k 个子数组(归并段)。
插入排序对它最快 解决,最慢的情况 解决
对于归并排序:
它的递归树:
根据设定,我们把原数组分成 n/k 个子数组时停止划分,此时递归树在深度 h 层时,规模变成 :
递归树每一层合并时间为 ,则深度 h 层的合并一共耗费时间:
则此时把它们时间合并起来,可以得到归并排序下使用插入排序的时间。若以最坏的情况来看:
要维持或优于标准的归并排序,我们需要 。此时,显然需要:,即 。
所以 的最大取值为 。
Mendel 教授提议通过取消对
i和k是否相等的检查来简化RANDOMIZED-SELECT。简化后的程序称为SIMPLER-RANDOMIZED-SELECT。证明
SIMPLER-RANDOMIZED-SELECT算法在最坏情况下永远不会终止 (死循环)。
我们分析这个代码可以得到:如果在第一次调用 RANDOMIZED-PARTITION 时得到 q = r,则说明数组里全是比 A[q] 小的数,此时取到了最大值,是最坏的情况。
k = q - p + 1 = r,此时进入下个 SIMPLER-RANDOMIZED-SELECT 递归时数组的区间没有任何改变。在最坏的情况下会一直选到最大值,重复这一过程,相当于进行无限递归,程序死循环。
后记
本章重新回顾了算法导论中的算法性能分析部分的主要方法,并对比分析了几个重要排序算法的运行时间。
笔记内容仅为个人见解,若存在异议,欢迎与我交流。
