

前言
进入算法设计与分析的学习,首先就需要了解怎么分析一个算法,之后就是如何设计这样的一个算法。本章基于《Introduction to Algorithms》4th(《算法导论》第四版)中第二章与第三章的内容集合而成,部分位置描述比较粗略,详情请见原书。
分析与设计基础
这一节中,我们使用Insertion_Sort(插入排序)举例,进行伪代码(pseudocode)与算法分析的学习,再通过Merge_Sort(归并排序)进行算法设计的学习。
算法分析
算法分析是预测算法所需要的资源,我们并不采用写代码运行进行测试插入排序算法的耗时的方法评价算法性能,而是直接对算法本身进行分析。
算法评估的标准:根据算法本身的运行时间(即算法的时间复杂度)来评估。
接下来是对插入排序进行分析,我们设第i行每次执行需要时间为,输入排序的数量为。

第一行for循环与第5行while循环最终都会多执行一次判断跳出条件,故它们时间多1. 我们逐条分析了他们的需要的时间后,把它们相加就是最后的算法运行时间。
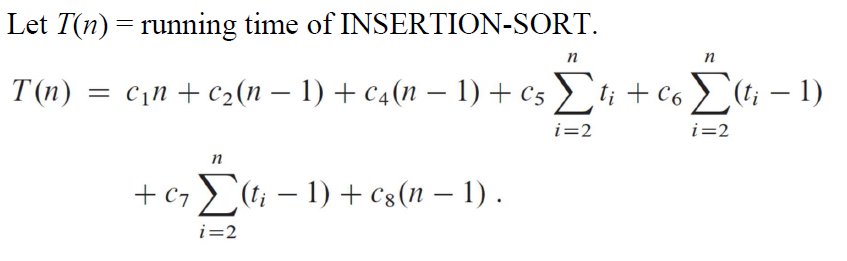
在最好的情况下,求和得到的应该是一个线性函数(一次函数),形如。此时只执行次,、不执行,故:

而最差的情况也很容易想象,就是完全倒序时的排序。此时求和为一个二次函数,形如。
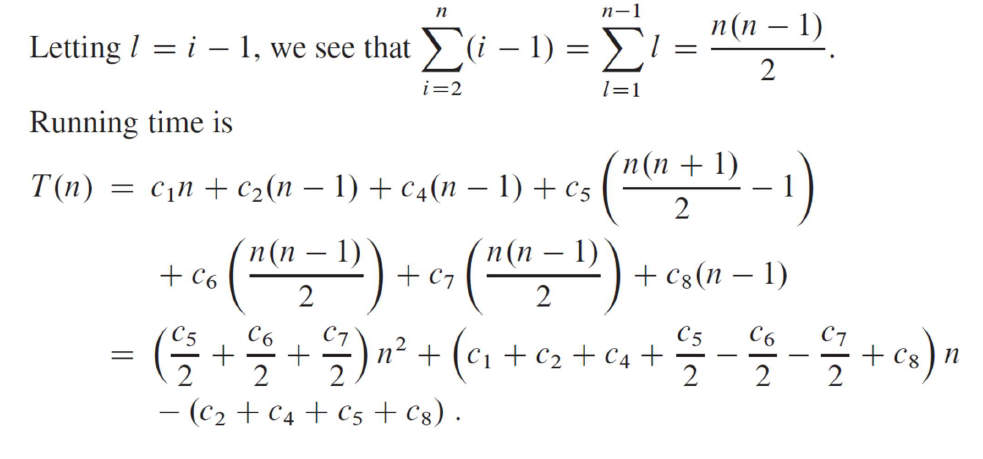
对于算法的分析,我们往往集中于只求最坏的情况运行时间,它给定了算法运行的上界。在很多情况下,平均情况与最坏情况大致一样差,且更难计算。
我们还通常使用一些抽象的方法来表示运行时间的增长率或增长量级。这个将在之后的部分说明。
算法设计
对于设计一个算法,方法有很多。其中本节用分治法进行设计说明,更多分治法内容将在下一章中提及。
许多有用的算法在结构上是递归的,为了解决一个给定的问题,算法一次或多次递归地说用其自身以解决紧密相关的若干子问题。这些算法典型地遵循分治法的思想:将原问题分解为几个规模较小但类似于原问题的子问题,递归地求解这些子问题,然后再合并这些子问题的解来建立原问题的解。
分治法分为三步:
- 分解(Divide):分治法中的分,将原问题分解为若干子问题。
- 解决(Conquer):分治法中的治,求出子问题的解。
- 合并(Combine):将子问题的解合并为原问题的解。
归并排序的具体实现思想我们在之前的数据结构已经学过过了,具体可见:
https://hoyue.fun/data_structure_7.html#Merge_Sort
其伪代码实现部分:
MERGE(A, p, q, r) nL = q - p + 1 nR = r - 1 let L[0 : nL - 1] and R[0 : nR - 1] be new arrays for i = 0 to nL - 1 L[i] = A[p + i] for j = 0 to nR - 1 R[j] = A[q + j + 1] i = 0 j = 0 k = p while i < nL and j < nR if L[i] \le R[j] A[k] = L[i] i = i + 1 else A[k] = R[j] j = j + 1 k = k + 1 while i < nL A[k] = L[i] i = i + 1 k = k + 1 while j < nR A[k] = R[j] j = j + 1 k = k + 1
MERGE-SORT(A, p, r) if p ≥ r return q = ⌊((p + r) / 2)⌋ MERGE-SORT(A, p, q) MERGE-SORT(A, q + 1, r) MERGE(A, p, q, r)对于归并排序的分析,即分治法的分析,我们一般使用递归树(recursion tree),这个将在下一章中着重介绍。
函数的增长
分析算法时描述运行时间除了之前所说的一步步计算外,当输入规模足够大,使得只有运行时间的增长量级有关时,我们要研究算法的渐近效率。也就是说,我们关心当输入规模无限增加时,在极限中,算法的运行时间如何随着输入规模的变大而增加(增长率)。
我们描述运行时间一般使用如下几种渐进符号:(big O),(big Omega),(big Theta),(little o),(little Omega)。
O-notation
O-notation用于描述函数的渐近上界(asymptotic upper bound)。如果存在正常数和,使得当时,,则记为f(N)=O(g(N))。O(g(N))是一个集合,包含了所有最大上界为g(N)的函数。
此时的函数,如图:
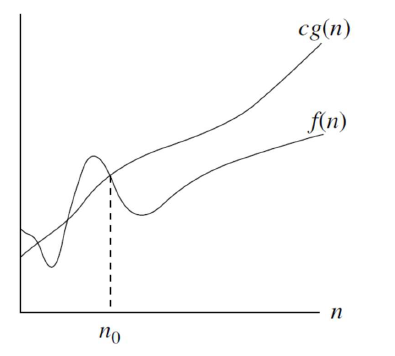
例如对于下面函数,均属于的集合。
Ω-notation
Ω-notation用于描述函数的渐近下界(asymptotic lower bound)。如果存在正常数和使得当时,,则记为。也是一个集合,包含了所有最小下界为的函数。
此时的函数,如图:
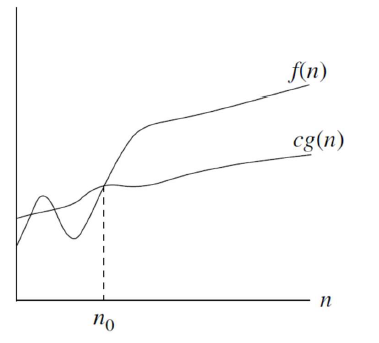
例如对于下面函数,均属于的集合。
Θ-notation
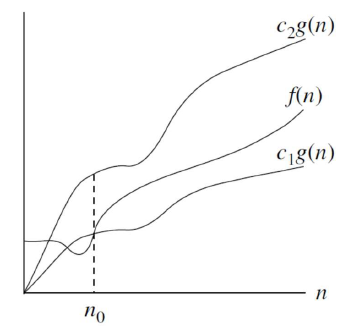
Θ-notation用于描述函数的渐近紧确界(asymptotic tight bound)。如果存在正常数、和使得当时,,则记为。根据夹逼定理(Sandwich Theorem),此时。 也是一个集合,包含了所有满足 的 函数。
因此可以得到推论,当 且 时,。于是当是常数时,此时,我们经常用表示一个常量或者某个变量的常量函数。
此时的函数,如图:
o-notation & ω-notation
由O记号提供的渐近上界不一定是完全渐近紧确的,我们使用o记号来表示一个非渐近紧确的上界。如果存在正常数和,使得当时,,则记为。
同理,我们使用ω记号来表示一个非渐近紧确的下界。如果存在正常数c和n0使得当时,,则记为 。
渐进符号的使用
- 我们在使用上述渐进符号的时候,符号内只包含了变量的最高次项,不包括常数与非最高次项。例如函数,用渐进符号表示可以为。
- 在等式和不等式中可以使用渐进符号。一般来说,当渐近记号出现在某个公式中时,我们将其解释为代表某个我们不关注名称的匿名函数。按这种方式使用渐近记号可以帮助消除一个等式中无关紧要的细节与混乱。例如:。 其中是集合 中的一部分。
- 当(不)等式左右两边都存在渐进符号时,表示:无论怎样选择等号左边的匿名函数,总有一种办法来选择等号右边的匿名函数使等式成立。例如:,此时无论选择任意函数,均满足。
后记
本章包括了《Introduction to Algorithms》4th中2~3章的内容,主要介绍了如何进行算法分析与设计和如何描述运行时间。
