

文章目录
前言
过去二十年,通用处理器能依靠登纳德缩放定律和摩尔定律同步提升频率与晶体管数量,可以获得性能的增长。
在大语言模型 (LLMs) 不断演进的今天,模型发展得很快,但算力经常成为其瓶颈。性能到底受什么限制,数据为什么会成为瓶颈,算力、带宽与数据复用之间又如何相互制约,计算单元是否真正被利用,以及整个系统的瓶颈到底出现在单个算子内部,还是出现在 CPU、GPU、NPU 之间的数据移动过程中?
为了回答这些问题,本篇笔记将专注于 现代的计算机体系结构 (Modern Computer Architecture)。首先从最基础的单位换算、FLOPs、Byte traffic 和 计算强度 (Arithmetic Intensity) 开始,建立分析 AI 算子的数学语言;随后进入 Roofline 模型,学习如何通过峰值性能、内存带宽和拐点判断一个工作负载 workload 是 算力受限型 (compute-bound) 还是 内存受限型 (memory-bound)。接着,比较 CPU、GPU 和 NPU 的体系结构差异,理解为什么同一个算子在不同硬件上可能出现完全不同的性能瓶颈。
在此基础上,进一步讨论常见的 AI 算子的建模与分析,学习 NPU 的数据流机制,理解 NPU 为什么适合密集型的 GEMM、FFN 和卷积类计算。后半部分重点转向当前 AI 架构中的典型优化技术以及分层的 Roofline 模型。
最后,从单个算子分析上升到异构系统系统。通过发现异构系统中 Amdahl’s Law 和传输延时等的约束,对整个系统级别建模分析。
快速回顾题目导航:
- Q1: Foundations — The Roofline Formula
- Q2: Arithmetic Intensity — Matrix Multiplication
- Q3: CPU vs. GPU Roofline Profiles
- Q4: GPU Attention Bottleneck
- Q5: NPU Dataflow — Weight Stationary
- Q6: Optimization Techniques on the Roofline
- Q7: Hierarchical Roofline & Caching
- Q8: Recommendation System & Extreme Memory Bound
- Q9: Heterogeneous System & Amdahl’s Law — Bottleneck Shift
- Q10: Design & Exploration — Hybrid Transformer on Heterogeneous SoC
单位、数量级与性能计算语言
为了量化任何模型的计算性能,我们需要了解三种计量语言:
- 计算量 (compute work):到底要做多少次运算?
- 数据量 (data volume):到底要搬运多少 Byte 的数据?
- 时间/速度 (bandwidth):在一定的时间内,这些运算或数据搬运能完成多少?
计算量
衡量计算量有三种比较常见的计量指标 (metrics):FLOPs / OPs / TOPs。
FLOPs (Floating-Point Operations) 表示 浮点运算 的次数,它可以用来衡量模型的复杂度。例如有两个浮点数 和 进行运算, 表示一次乘法操作,计算量为 1 FLOP;如果执行 ,则包含一次乘法和一次加法,共计 2 FLOPs。
在神经网络中,最常见的公式就是加权计算 ,用于表示权重乘输入,再加偏置项。我们将这样的运算称为 MAC (Multiply-Accumulate,乘加运算)。在一些硬件设计中,将 MAC 融合到了一个运算单元里,看作一条指令 MAC。根据我们之前的分析:。在深度学习模型中,我们通常通过统计卷积层或全连接层中 所有乘法和加法的总次数 (MACs) 来评估模型的计算复杂度。
除了浮点运算外,在 整数或定点数运算 场景下,我们通常使用 OPs (Operations, 操作数) 来衡量。OPs 可以泛指任何计算动作。
在描述 AI 芯片的峰值性能或计算速度时,FLOPS (Floating Point Operations Per Second, 每秒浮点运算次数) 表示每秒能完成多少浮点数计算和 TOPS (Tera Operations Per Second) 代表 每秒能完成多少万亿次浮点数操作。
一个处理单元的峰值计算量或者说是 峰值性能 (peak performance) 是在理想状态下,所有计算单元进行计算的理论最高速度。但实际情况下受限于架构、数据等,实际性能往往低于峰值性能。
我们一般使用 利用率 (Utilization) 来表示在运算中实际体现出的性能:.
例如一块芯片 ,. 我们可以计算出 ,这意味着这块芯片理论上很强,但实际只用了 1/4 的能力。
数据量
一个程序不能只是在计算,它还需要不断地搬运数据。数据量 (Data Volume) 表示运算中处理的数据的大小。
数据的基本原子是 比特 (Bit),代表一个 0 或 1。但我们几乎从来不用 bit 谈论数据的大小,在计算机程序中,数据通常以二进制的 字节 (Byte) 作为基本度量单位。。所以我们要衡量一次操作中的数据量时,可以计算:总数据量 = 元素数量 × 每元素 Byte。
在深度学习中常用的 单精度浮点数 (FP32) 1 个元素占用 4 Bytes,而 1 个 半精度浮点数 (FP16) 或 BF16 则占用 2 Bytes。对于大模型推理中常见的量化数据,如 INT8 或 INT4,其占用的空间会进一步缩小到 1 Byte 或 0.5 Bytes。准确估算数据量是理解内存带宽瓶颈和显存占用的关键,这直接决定了模型能否在特定的硬件架构上高效运行。
数据量中最常见的就是数量级的变化:
我们在性能计算中,经常会使用 进行近似计算,需要前后保持一致即可。
例如,我们衡量一个矩阵的数据量时:,可以先计算元素个数:。如果是在 FP16 的表示下,一个元素表示 2 Bytes,那么这个矩阵的数据量就是:.
速度与时间
在明确了计算量和数据量后,我们需要关注执行效率。带宽 (Bandwidth) 描述了 单位时间内从存储器搬运数据的能力,通常以 GB/s 或 TB/s 为单位。
程序从内存中搬运数据的时间可以计算为:,例如要搬 的数据,带宽是 ,那么只需要 即可完成。
带宽相当于表示一个 “传送带的速度”,峰值性能相当于餐厅后厨做菜的速度。如果厨师非常快,但传送带太慢,那么厨师只能等食材,这也影响到了整体的性能。
此外,还有一个指标 吞吐量 (Throughput) 衡量了 单位时间内实际完成的计算任务总量。例如 每秒请求数 (QPS),每秒生成的 Token 数 (tokens/s),还有之前提到的 TOPS 和 GB/s,它们都是吞吐量。
与吞吐量对应的另一个核心指标是 延迟 (Latency),它代表完成 单次任务所需的总时间。在实际应用中,高吞吐量意味着系统在宏观上处理任务的效率更高,而低延迟则意味着微观上响应更快。例如在 AI 推理场景下,我们通常结合 每秒生成的 Token 数和首字延迟来全面评估一个系统的性能表现。
计算强度
计算强度(Arithmetic Intensity) 是指程序中 每字节访存所对应的计算操作次数,即 每搬运 1 Byte 数据,所能进行的运算次数。 通常以 FLOPs/Byte 为单位。
它衡量了算法对计算资源与内存带宽的需求比例:高计算强度意味着算法在处理数据时进行了 大量的运算,而低计算强度则意味着频繁的 数据搬运成为了主要的开销。
接下来我们通过一个例子来串联计算量、数据量、带宽以及计算强度。
假设在 FP16 下有一个矩阵乘法运算,, , , ,请计算该矩阵乘法整体的计算量、数据量和计算强度。
我们首先计算 FLOPs,对于矩阵乘法中,每个 的元素 = 一行 和一列 做点积,每个点积长度是:(这是与 , 矩阵中的相同项数决定的,即 的行去乘 的列,所以是 )。每一项有一个 Mac,即 1 次乘法和 1 次加法操作,共 2 FLOPs。
一共有 个项,所以计算量:.
接下来我们算数据量: 的元素有 , 的元素有 . 那么总元素有:。在 FP16 中,一个元素表示 2 Bytes,所以总数据量:.
最后我们来算计算强度,它直接等于总计算量除总数据量:. 这表示每搬 1 Byte 数据,大约能做 236 次运算。
Roofline 模型
Roofline 基础概念
回到我们的核心问题上:一个程序跑不快,到底是算力不够,还是数据跟不上?
Roofline 模型 (屋脊模型) 是一个用于评估程序在特定硬件架构上 性能表现 的直观模型。它通过将硬件的理论峰值计算能力和内存带宽限制绘制在同一张图中,帮助我们 识别程序的性能瓶颈。Roofline 模型的核心是:程序最终速度由峰值计算量 (屋顶) 和数据搬运能力 (斜坡) 中更低的那个决定。
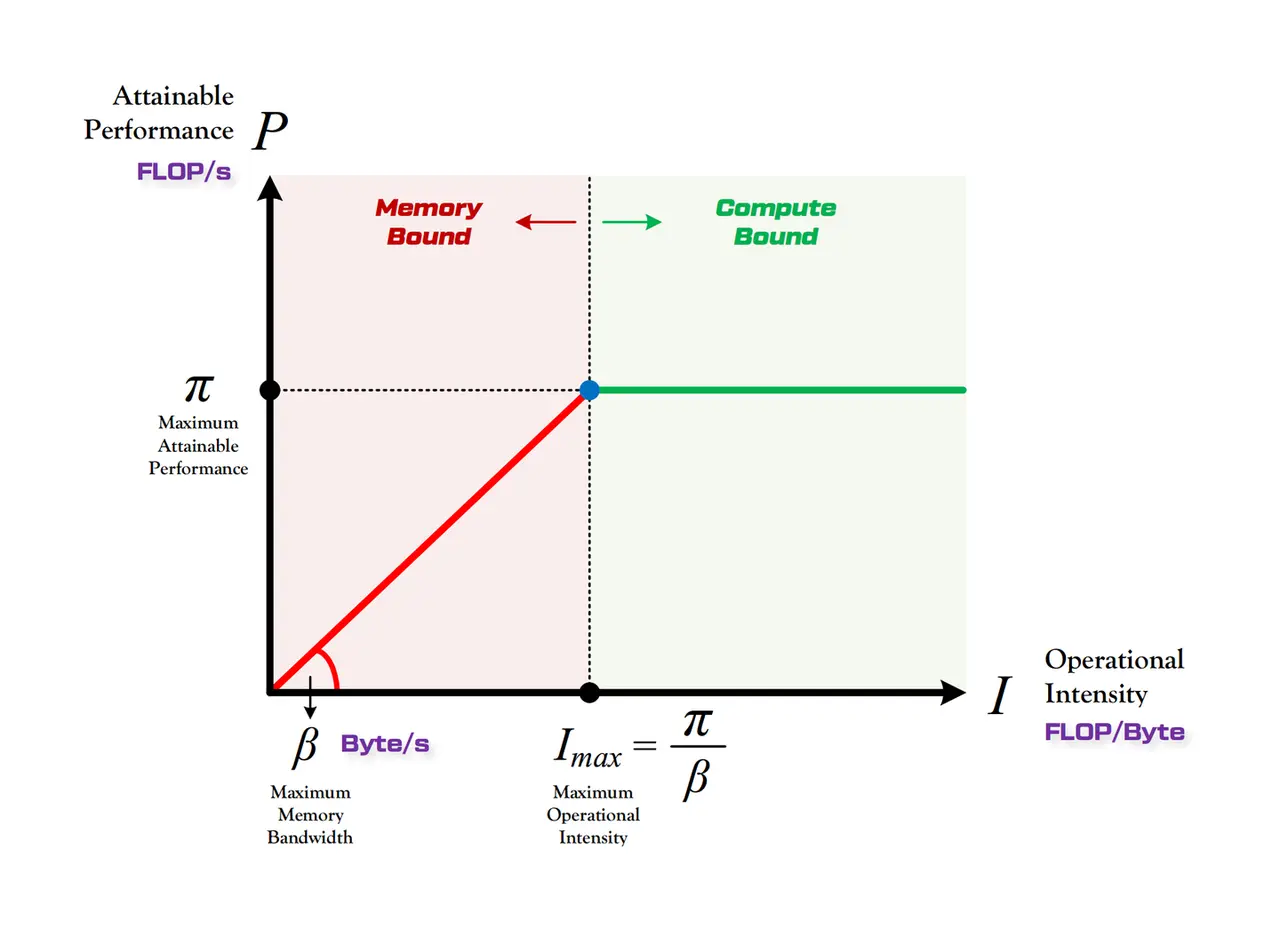
它的公式是:,其中:
| 符号 | 含义 | 单位 |
|---|---|---|
| Peak Performance,算力峰值,表示硬件峰值计算能力 | FLOPS (FLOP/s) 或 TOPS | |
| Memory Bandwidth,内存带宽,表示数据传输的速度 | Byte/s, GB/s, TB/s | |
| Arithmetic Intensity,算术强度,表示单位数据量下的运算次数 | FLOPs/Byte 或 OPs/Byte | |
| Attainable Performance,实际可达到的性能上限 | FLOPS(FLOP/s) 或 TOPS |
如上图,X 轴表示 算术强度 ,它代表了你的程序有多复杂。 越大,表示计算越复杂。Y 轴表示系统最终能提供的 实际性能 。它代表了程序实际跑得有多快。 往大,性能越高。
我们可以发现,Roofline 模型将性能划分乘两个平面。
- 当你的程序 很 低(在 X 轴的左侧)时,例如 ,你拿一点数据只做简单的计算,马上又要去拿新数据。此时,硬件的 算力是闲置的,决定你有多快的是 内存带宽 。.
- 当你的程序 很 高(在 X 轴的右侧)时,例如 ,你拿到一点数据就能算很久。此时,数据送得再快也没用,因为 计算单元 已经满负荷运转了。增加内存带宽不会带来任何加速。.
想象一下屋脊的样子,倾斜的墙壁和平坦的屋顶会在某一点相交,这个点就是 Ridge Point(拐点)。它代表了 硬件的算力和内存带宽达到了完美的平衡。这个拐点就是图中的 .
- 如果程序的算术强度 :工作负载处于斜坡区,Memory Bound(内存受限) 。
- 如果程序的算术强度 :工作负载处于平屋顶区,Compute Bound(算力受限) 。
下面是一个应用屋脊模型分析的例子:
假设某处理器的峰值算力 ,内存带宽 。一个在该处理器上跑的程序的计算强度为 ,判断程序的受限类型,并计算其实际性能与利用率。
在这个处理器上,我们计算其拐点:,这说明在这个处理器上,你的程序平均每读取 1 个 Byte 的数据,必须执行至少 250 次浮点运算,才能不浪费它强大的算力。
接下来我们判断程序的情况:因为 (),它卡在了左侧的斜坡上。所以,这个程序遇到的瓶颈是 Memory Bound(内存受限)。
继续应用屋脊模型公式,可以得到当前程序的实际性能:,然后再根据峰值算力计算其利用率 ,说明其只发挥了处理器 80% 的水平。
Memory Bound 不代表性能很差。我们刚才计算的利用率也达到了 80%, 只是说明如果你想继续优化它,优先方向不是增加计算单元,而是尝试提高带宽。
CPU / GPU / NPU 架构画像
你也许听过,有些运算通过 CPU 跑比较快,一些运算通过 GPU 跑更快等,同一个 AI 算子,为什么放在 CPU、GPU、NPU 上会得到完全不同的性能结果?这一章将分析 CPU / GPU / NPU 架构画像。
我们来看看这三类芯片在 Roofline 模型下的真实画像情况。
首先是 CPU (Central Processing Unit, 核心处理器),它是对计算机的所有硬件资源(如存储器、输入输出单元)进行控制调配、执行通用运算的核心硬件单元。分析它的硬件画像可以得到:
- 峰值算力 Peak: 约 TFLOPS,对比其他处理器较低.
- 内存带宽 Memory(在 DDR 5 多通道的情况下): 越 GB/s,对比其他处理器中等.
- 计算其 算术强度 (Arithmetic Intensity) 拐点: 约为 FLOP/Byte, 对比其他处理器较低.
CPU 的特点是:
- 具有复杂的缓存结构(L1/L2/L3 Cache):一般缓存都比较小,但其访问速度极快,CPU 能够利用局部性原理,将频繁访问的数据和指令保留在离核心最近的地方,从而显著降低延迟。但是,一旦工作集超出缓存容量,性能会因容量失效急剧下降。这意味着,CPU 适合 数据局部性好的任务,不适合动辄扫描 GB 级无规律数据的场景。
- CPU 拥有复杂的乱序执行 (Out-of-order Execution) 和分支预测 (Branch Prediction),能很好地容忍不规则的内存访问,在指针追踪、稀疏访存、频繁分支等不规则模式下,CPU 的性能衰减远小于 GPU 等设备。所以 CPU 适合 控制复杂、不规则、难以完全并行的任务。
对于一些简单标量和向量的任务,例如 C[i] = A[i] + B[i] * scalar; 它们没有多次利用数据,所以触发缓存的概率较低,所以这些运算在 CPU 上基本上都是 内存限制型 (Memory Bound)。而对于矩阵乘法这种重复利用元素进行运算的计算,因为 CPU 的峰值算力 太低, 通常也很低,它们一般是被 计算能力限制了 (compute-bound)。
接着就是 GPU (Graphics Processing Unit, 图形处理器),它最初是为了加速图形渲染而设计的,但由于其强大的 并行计算能力,现已广泛应用于深度学习、科学计算等领域。与擅长处理复杂逻辑控制的 CPU 不同,GPU 拥有成百上千个简单核心,能够同时处理数以千计的计算线程。这种吞吐量导向的设计,使其在处理大规模数据密集型任务时展现出远超传统处理器的性能优势。同样我们分析其硬件特征:
- 峰值算力 Peak:很高, 约为 TFLOPS.
- 内存带宽 Memory:很高, 约为 TB/s.
- 计算强度的拐点 :很高,约为 FLOPs/Byte.
GPU 的根本思路是 “用数量换时间” ——通过线程并发(SIMT 模型),并配备 超高内存带宽,让访存延迟显著降低。
HBM (High Bandwidth Memory) 是 GPU 的主存,相当于 CPU 的内存条(RAM)。它的容量很大,带宽极高,但物理上离计算核心较远,延迟高。与 CPU 设计类似的,GPU 在核心和 HBM 之间有一个共享缓存 (可编程的 L1 缓存) 和一个 L2 缓存。比 CPU 更高效的是,程序员可以通过代码 显式去管理 L1 缓存,决定放什么数据进去、什么时候搬入搬出。
虽然 GPU 的理论算力和带宽惊人,但实际应用中因为 分支发散 (Divergence) (遇到条件分支且执行不同路径时 GPU 会串行执行每条路径) 和 共享内存冲突,能达到的效率 常常远低于峰值 .
因此 GPU 适合各分成多个线程做一样的事、数据排列整齐、访问连续、任务数量巨大、分支很少的任务,例如 大型矩阵运算,CNN 训练,Transformer FFN 等。例如 CNN 训练时因为批次大、算术强度高,训练通常处于 算力限制 (Compute Bound) 区域。但是例如标准的 Transformer 注意力机制(Attention)由于会产生 的中间矩阵,往往会掉入 内存限制 (Memory Bound) 的斜坡区域。
到了最后的 NPU (Neural Processing Unit, 神经网络处理单元),它是一种专门设计用于加速人工智能和深度学习任务的硬件加速器,旨在高效执行神经网络计算任务。简单来说就是:为 AI 算子定制 的专用自动化生产线。它的画像如下:
- 峰值算力 Peak:极高, 约为 TOPS.
- 内存带宽 Memory:很高, 约为 GB/s - TB/s.
- 计算强度的拐点 :很高,约为 OPs/Byte.
NPU 采用了 数据流 (Dataflow) 架构,依赖完美匹配的 SRAM。关于 NPU 的具体介绍将在后续的章节展开。
对比三种常见处理器,它们的画像如下:
| 架构类型 | 峰值算力 | 内存带宽 | 计算强度拐点 | 适合/不适合的任务 |
|---|---|---|---|---|
| CPU | 低 约 1–5 TFLOPS (FP32, AVX-512) | 低 约 200 GB/s (多通道 DDR5) | 极低 约 5–25 FLOPs/Byte | ✅ 适合:处理复杂的控制流、分支预测,以及 不规则的内存访问模式 ;高度优化的密集型算子(如 BLAS3 GEMM)能达到算力峰值。 ❌ 不适合:大多数标量/向量混合代码,它们极易陷入 Memory Bound 区域 。 |
| GPU | 高 约 100–1000 TFLOPS (Tensor Core) | 极高 约 1–5 TB/s (HBM2e/HBM3) | 中等 约 50–300 FLOPs/Byte | ✅ 适合:海量并发任务,如 CNN 训练(大批次、高算术强度,通常处于 Compute Bound)。 ❌ 不适合:标准 Transformer 注意力机制(产生大量中间矩阵)、小批次推理(Small-batch inference)和词表嵌入查找(Embedding lookups),这些任务非常容易掉入 Memory Bound 的斜坡区域 。 |
| NPU / AI加速器 | 极高 约 100–2000 TOPS (INT8/FP16 脉动阵列) | 中/高 约 100 GB/s – 1 TB/s (取决于是否有HBM) | 高 / 极高 约 100–2000 OPs/Byte (跨度极大) | ✅ 适合:能够 完全放进片上 SRAM 的分块(Tiling)计算,此时有效带宽可达 TB/s 级别,能充分释放算力峰值。具有极高的能效比。 ❌ 不适合:大模型注意力机制中 超过 SRAM 容量的矩阵(会严重 Memory Bound);小算子或深度可分离卷积(由于阵列利用率低,实际算力远低于峰值)。 |
下面是一个任务跑在不同处理器上的对比分析:
假设我们有一个计算工作量 (workload) 的计算强度为 FLOPs/Byte,三种处理器的性能如下:
- CPU: TFLOPS, GB/s
- GPU: TFLOPS, TB/s
- NPU: TOPS, GB/s
分析该计算在不同处理器上是算力受限还是内存受限。
根据给出的三种处理器的性能数据,我们可以计算其计算强度的拐点 :
- CPU: FLOPs/Byte.
- GPU: FLOPs/Byte.
- NPU: OPs/Byte.
对比发现:
- CPU:,因此该 workload 在 CPU 是计算受限 (compute-bound)。
- GPU:,因此该 workload 在 GPU 也是计算受限 (compute-bound)。
- NPU:,因此该 workload 在 NPU 是内存受限 (memory-bound)。
Roofline 回顾分析
到现在为止,我们已经了解了 Roofline 模型、算术强度(Arithmetic Intensity, AI)以及不同处理器架构的核心差异。接下来通过三道题目来巩固这些部分。
Q1: Foundations — The Roofline Formula.
- (a). 分析 Roofline 的核心公式及其符号。
- (b). 推导其拐点,并解释其意义。
- (c). 如果一个处理器有峰值算力 TFLOPS 和内存带宽 GB/s,计算其拐点。如有一个工作负载 FLOPs/Byte,它的实际性能和利用率有多少?
这是非常基础的概念和公式分析:
- (a). Roofline 的核心公式用来计算 工作负载 (Workload) 的 实际/可达性能 (Attainable Performance, ) :
- :峰值计算性能 (Peak Performance),即硬件理论上的最大计算能力,单位通常是 FLOP/s 或 TOPS。
- :内存带宽 (Memory Bandwidth),即硬件搬运数据的最快速度,单位是 Byte/s 或 GB/s。
- :算术强度 (Arithmetic Intensity),即程序每搬运 1 Byte 数据能执行多少次计算,单位是 FLOPs/Byte。
- (b). 拐点 (Ridge Point, ) :令公式中的两个边界条件相等,即 ,即可推导出拐点公式:,这个拐点表示了 处理器的计算与访存能力达到完美平衡时的算术强度界限。
- 当 时:工作负载处于斜线区域,属于内存受限 (Memory Bound) 。此时性能瓶颈在于数据搬运太慢,性能由公式 决定。在这种情况下,即使增加更多的计算单元(提高 )也无济于事,因为计算单元都在闲置等待数据。
- 当 时:工作负载处于水平线区域,属于计算受限 (Compute Bound) 。此时性能已经触及处理器的理论天花板(),再增加内存带宽也不会带来任何性能提升。
- (c). 对于给出的处理器,计算其拐点: FLOPs/Byte. 因为当前工作负载的 ,满足 ,所以它是内存受限 (Memory Bound) 的。此时的实际性能:,利用率 (Utilization) = 。注意:单位必须能对上。
Q2: Arithmetic Intensity — Matrix Multiplication
对于一个矩阵乘法:, ,,,,在 FP16 (1 个元素 2 bytes) 下,求:
- (a). 这个矩阵乘法整体的计算量。
- (b). 这个矩阵乘法整体的数据量(Naïve HBM traffic,即 HBM 中的数据访存量,在没有任何数据重用下,矩阵 A、B、C 各需要从 HBM 读或写一次)。
- (c). 这个矩阵乘法整体的计算强度。
- (d). 如果使用 分块技术 (Tiling) 让数据保存在 L1 缓存中,使得 HBM 的实际数据传输量减少 50 倍,此时的计算强度是多少,解释分层 Roofline 的意义。
对于 矩阵乘法 (GEMM) 运算,我们需要注意的是一个 MAC 操作包含 1 次乘和 1 次加,共 2 FLOPs。
- (a). 矩阵维度为 。矩阵乘法的总浮点操作数公式为 。FLOPs = FLOPs 。
- (b). A, B 矩阵都需要从 HBM 读一次,C 需要写到 HBM 一次,在 FP16 下,A 的数据量为 MB。同理可以得到 B 和 C 的数据量都是 MB。所以总数据量:Bytes = MB。
- (c). 根据 (a) 和 (b) 的计算结构,我们可以计算其计算强度 FLOPs/Byte。表示每从 HBM 搬 1 Byte 数据,矩阵乘法可以做约 341 次运算。
- (d). 如果通过分块技术使得 HBM 的访存量减小至其 1/50,那么其 HBM 的有效访存数据量为 ,代入计算新的计算强度: FLOPs/Byte。分块 并没有减少数学计算量 FLOPs,而是让 A/B/C 所需的数据在 L1 中被复用,减少 HBM 的数据量。 因为在硬件的设计中,L1 缓存一般会比 HBM 访问快很多。有效带宽取决于数据实际存放在哪一层存储层级。分块技术使得数据操作主要发生在 L1 层,这不仅让程序享受到了极高的 L1 带宽,也大幅降低了该层的 ,使得计算强度大幅向右侧移动 ( 减小, 大幅增大),突破了原有 HBM 带宽的限制。
Q3: CPU vs. GPU Roofline Profiles
给定 Roofline 模型中,CPU: = 4 TFLOPS, = 200 GB/s,GPU: = 312 TFLOPS, = 2 TB/s.
- (a). 比较 Roofline 框架下,CPU 和 GPU 的核心区别,并解释它们如何影响瓶颈区域。
- (b). 给定 FLOPs/Byte,分别判断在 CPU 和 GPU 上是 Memory Bound 还是 Compute Bound。
这一部分很考验我们在 Roofline 模型下对 CPU 和 GPU 的认识,根据我们上述给出的条件,可以总结出如下两条核心区别:
- 带宽与拐点差异:CPU 的内存带宽较低(200 GB/s),导致其拐点很低(通常在 FLOPs/Byte)。相反,GPU 拥有极高的带宽(1-5 TB/s),因此其拐点要高出一个数量级( FLOPs/Byte)。这就导致了:许多在 CPU 上属于计算受限 (compute-bound) 的程序 (workload),到了 GPU 上会变成内存受限 (memory-bound)。
- 缓存层次与并行度差异:CPU 拥有深度且由硬件自动管理的缓存层级(L1/L2/L3),并采用乱序执行 (OoO),非常适合处理 不规则的数据访问和指令级并行 (ILP) 。而 GPU 依赖海量的线程级并行 (SIMT) 以及由程序员手动管理的共享内存 (Shared Memory),它极其擅长处理 规则的、内存合并 (Coalesced) 的 数据并行 任务。
对于 (b) 部分:CPU 的拐点 FLOPs/Byte,GPU 的拐点 FLOPs/Byte. 对于一个 workload 的计算强度 FLOPs/Byte:
- 在 CPU 上,它是计算受限 (Compute Bound) 的,此时 TFLOPS;
- 在 GPU 上,它是内存受限 (Memory Bound) 的。此时 TFLOPS.
常见 AI 算子建模
在实际的 AI 算子中,我们如何应用上述学到的 Roofline 模型分析它们运算的瓶颈呢?这一章将深入常见的 AI 算子的过程,对其计算量和数据量进行建模,并计算其计算强度以分析瓶颈所在。
矩阵乘法
通用矩阵乘法 (General Matrix Multiply, GEMM) 是数学计算和高性能计算中最核心的基础操作之一,其数学形式为:。其中 ,,, 和 都是标量。假设在 下,。
对于乘积结果的一个元素 ,它的值是 的第 行和 的第 列做点积:. 每一项都包含一次 MAC 操作,即 1 次乘法和 1 次加法,共计 2 FLOPs。每一个 要做 次 MAC 操作, 一共有 个元素,所以计算量为:
如果没有缓存优化,你需要 把 、 从 HBM 读进来一次,把 写回去一次。如果数据类型是 FP16,那么每个元素 2 Bytes。所以数据量也很显然如下:
我们可以根据上述计算,得到其计算强度 ,注意单位的转换:
因为 的一行会和 的很多列相乘,同理, 的一列会和 的很多行相乘,所以同一份数据可以参与很多次计算。同一个元素会被复用,所以计算得到的计算强度 通常高。
在计算中,我们假设数据量是没有任何优化的,都从 HBM 直接读/写,此时速度会受 HBM 数据读写的影响。如果通过 分块 (tiling) 等一些方式将一部分的元素复用留在 L1 缓存中,则会大大减少其直接读写 HBM 的次数,从而减小数据量的计算,再而提高计算强度。分块 (tiling) 减少的是 从 HBM 搬数据的次数,而不是计算量。如之前的例子 Q2.
卷积
卷积 (Convolution) 是现代深度学习硬件加速器中的核心算子,其本质是 带了滑动窗口的矩阵乘法,具有大量的 MAC 运算。
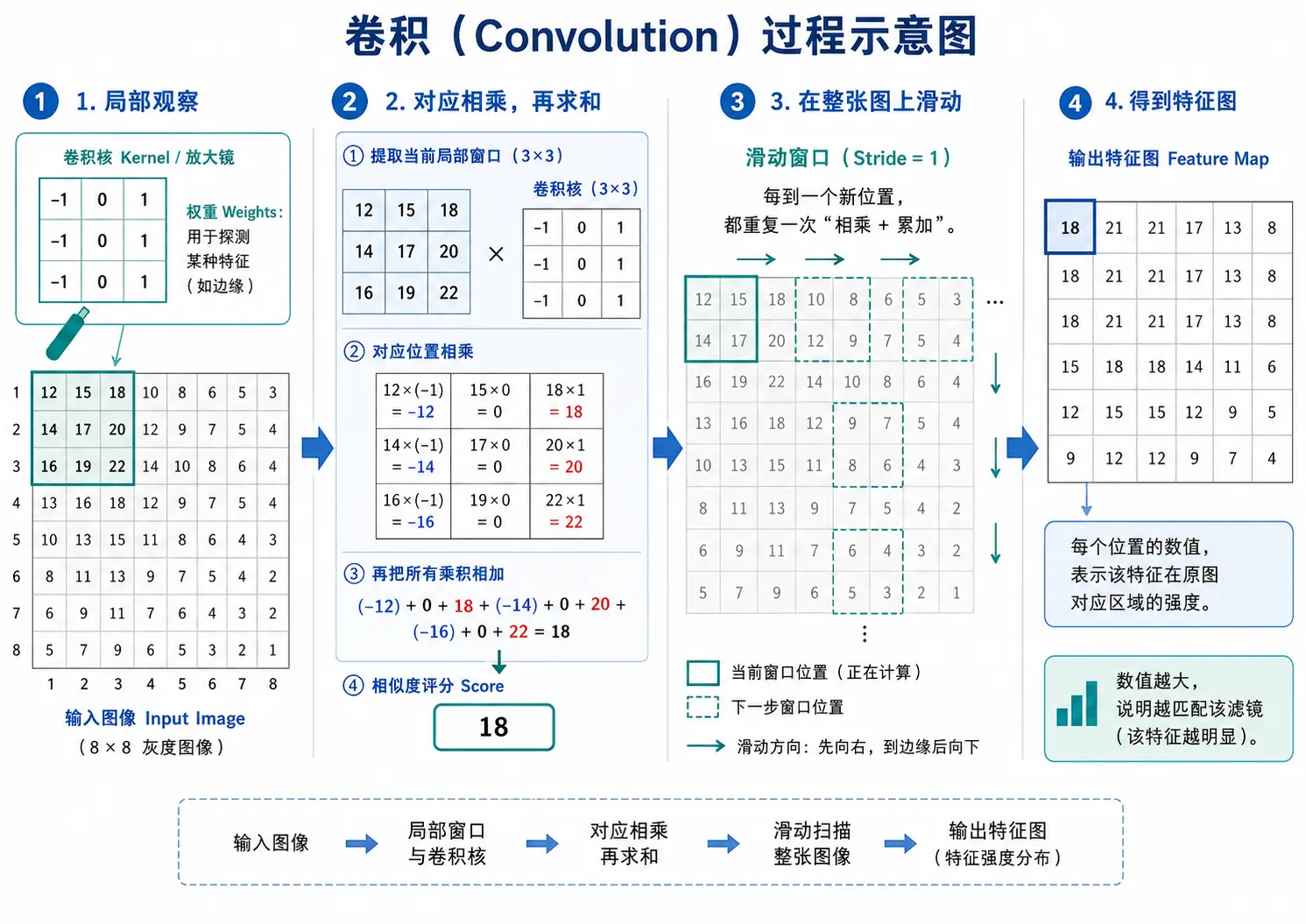
以计算机图像为例,如果有一张很大的图像,计算机一次性看不完全部的区域。卷积就是用一个小的 放大镜 (卷积核, Convolution Kernel) 去给这张图片做局部检查,并提取出一些信息。
这个放大镜,就是 卷积核 (Kernel),它可能很小,比如 3×3 或 5×5。放大镜内部是一个带有特定花纹的“滤镜”(数字),称为卷积核的 权重 (Weight)。一个“滤镜”专门负责探测一种特定图案,即这组权重定义了我们要寻找的特定模式(如垂直边缘或特定纹理)。
接下来,将这个放大镜覆盖在图像的左上角开始扫描。透过放大镜窗口下原图的格子,就是当前这片区域的像素值。接下来,将窗口内的权重数字与它下方覆盖的图像像素值一一对应,对应的数字相乘,然后把所有的乘积全部相加,得到一个唯一的总和。这个总和反映了当前区域与放大镜的“滤镜”的相似度评分。这相当于是在算这片被放大的区域和我的“滤镜”有多像。
接着,按照预设的距离(例如 1 个像素),将放大镜窗口在图像上从左到右、从上到下依次滑动。每滑动到一个新位置,就重复一次 对应位置乘再累加 的计算,并将得到的分数填入一张新纸的对应位置。当窗口扫完整张图,我们就得到了一张全新的数字矩阵,称为 输出特征图 (Feature Map)。这张图上的每个点,都代表了原始图像在对应位置出现该特征的强度:数字越大,特征越吻合。
如图是灰度图像上卷积的过程展示:
现实中的彩色图像具有 RGB 三个通道,我们可以把它想象成一块 3 层加厚的面包。每一层代表一个颜色通道(红、绿、蓝),它们在空间上是完全对齐的。
为了处理这种厚度,我们的卷积核(放大镜)也不再是薄薄的窗口,而是一个具有 相同深度 的 立体积木块,它的厚度与图像的层数一致。
当这个立体积木块扣在图像上时,它会 同时覆盖 红、绿、蓝三个通道的局部区域。在积木块内部,每一层的权重与对应通道的像素逐格相乘后相加。最后,把 所有通道、所有格子的乘积全部加在一起,最终只得到 一个 总分,表示与特定特征的相似度。
每扫描完一次整张图,依然只得到一张薄薄的窗口(一个通道的特征图),因为我们将所有通道得到的值相加了,只剩下了一层。如果我们想提取多种特征(如红色边缘,蓝色斑点等),我们会同时使用多个不同的立体积木。
每个积木块都会产生一张自己的特征图,我们将这些图按顺序叠放,就形成了一个 拥有新厚度的三维积木(输出特征图)。这个新积木的厚度,就等于我们使用的 卷积核个数。
如下图是彩色图中卷积的过程:

回到我们的计算量和数据量的计算上,我们该如何量化这一过程呢?
假设在灰度图像中,卷积核的大小为 , 它在一张大图片(高度 ,宽度 )上滑动。
在对应的彩色图像中,这张图片有 个输入通道,所以一个卷积核的大小为 . 设卷积核的输出通道 (卷积核的个数) 为 ,输出的一张特征图大小为 . 所以最后输出的卷积张量大小为 .
当我们衡量其计算量的时候,就是在计算卷积过程中涉及的 MAC 运算的次数。在一个通道上的卷积中,需要把 的卷积核和输入图上对应的一小块相乘再相加。对于特征图上的每一个点,如果有 个输入通道,此时需要计算 次 MAC 运算。
由于输出的特征图共有 个像素,那么整体的计算量就可以表示为如下:
对于数据量,我们先衡量卷积核的参数量:一个卷积核包含 个权重参数,所有的卷积核就有 个权重。通常还会附带一个 偏置 (bias) 量,所以总参数量 .
我们知道最后输出的特征张量大小为 ,所以输出的数据量就有 .
最后再加上初始输入的图片的数据量,卷积过程中的数据量有:
Self-Attention
Self-Attention (自注意力机制) 是一个 复合算子,由几个矩阵乘法和特殊的内存操作组成。
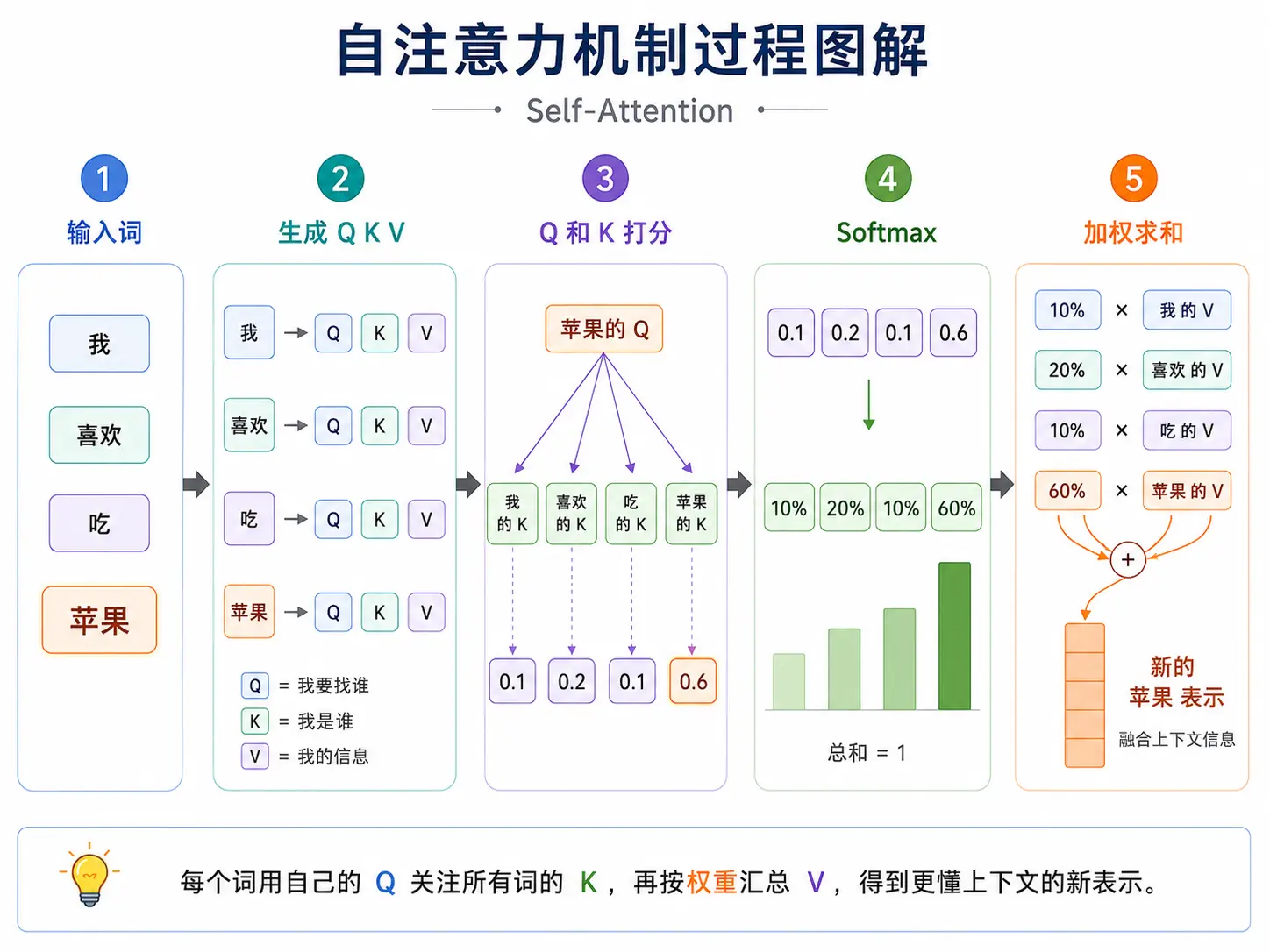
计算机是如何像人类一样,通过上下文理解一个词的真实含义的?这就是“自注意力机制”的用武之地。比如在“我喜欢吃苹果”中,“苹果”是一种水果;但在“苹果发布了新款手机”中,它是一个公司。为了区分,计算机让句子里的词不再是彼此独立的孤岛,而是坐在一起“开会”。
在开会前,每个词都会通过线性变换,为自己生成三个分身:
- Query ():“我要找谁” - 代表该词想要 寻找的上下文信息(某种线索)。
- Key ():“我是谁” - 代表该词能提供的 特征标签,供别人匹配。
- Value ():“我包含的具体内容” - 代表该词 本身携带的实质信息。 只是我的特征,而 则是我真正的内容。
会议开始后,每个词都会发起一场“全场扫描”:
- 打分(匹配):每个词都使用自己的 去与全场所有的词(包含自己)的 逐一进行比对,通过计算两者的相关性(),计算出相似度。语义关联越紧密的词,分数越高。
- 分配权重(归一化):为了看清重点,计算机会对分数进行归一化处理,转化成 百分比()。
- 信息提取(加权求和):根据这个百分比,该词去提取对应单词的具体内容 。
最后,把提取到的所有 信息按比例加在一起,就生成了一个 全新的、具备上下文语义的特征向量。
之所以称为自注意力机制,是因为 , , 全都源于句子内部的词。它让一句话里的每个词,都根据与所有词的亲密关系( 相似度分数),去收集大家的信息(),最终把 自己 变成一个更懂上下文的词。
下图展示了自注意力机制的过程:
假设 ,我们不难发现,其注意力分数 是一个 的矩阵乘一个 的矩阵, 最后生成一个 的矩阵 。这一步的计算量是:.
接下来在最后的特征融合时,,归一化的计算量不大,它输出的大小和 保持一致为 ,而 又是一个 的矩阵,这个矩阵乘法的计算量是:.
所以自注意力机制的总计算量为:.
在计算数据量的时候,如果每一个矩阵都只读/写一次 HBM,那么这个过程中涉及:读 ,写 和 .
元素个数上:,。在 FP16 下,.
Transformer FFN
如果说自注意力机制是让大家坐在一起“开会” 并交换彼此的信息;那么 FFN (Feed-Forward Network,前馈神经网络) 就是会议结束后的“独立思考时间”。每个词在换取了上下文信息后,都需要回到自己的私人房间,把吸收到的信息消化掉。
FFN 最重要的特点是每个词 共享一套思考的权重参数,并且思考过程是 完全独立 的,互不干扰。
每个词进入思考室后,都会经历三个标准步骤:
- 发散思维(维度扩张):词向量会先进行一次“头脑风暴”,将原本的维度(如 512 维)拓展到更高维度(如 2048 维)。这让词语有更宽广的空间去探索接收到的信息之间可能存在的各种复杂联系。
- 筛选灵感(非线性激活):通过一个“开关”(如 ReLU 或 GELU 激活函数),计算机会丢弃掉那些杂乱、无用的负面信息,只保留那些真正能解释语境的“灵感点”。这就是 非线性变换,它让模型具备了处理复杂逻辑的能力。
- 总结(维度压缩):最后,思考室会将刚才筛选出的精华信息重新浓缩,还原回原来的维度。此时的词向量,已经从当初那个“只知道别人说了什么”的原始状态,变成了一个“对自己和环境有了深刻理解”的深度分身。
如果只有注意力机制,模型就像一群只会互相传话却不爱动脑的人,只能做简单的加权平均。而 FFN 赋予了模型 非线性推理 的能力。Self-Attention 负责抓取不同词之间的关联,FNN 则负责提炼特征。两者交替进行,才让 Transformer 既能把握上下文,又能产生强大的表示能力。
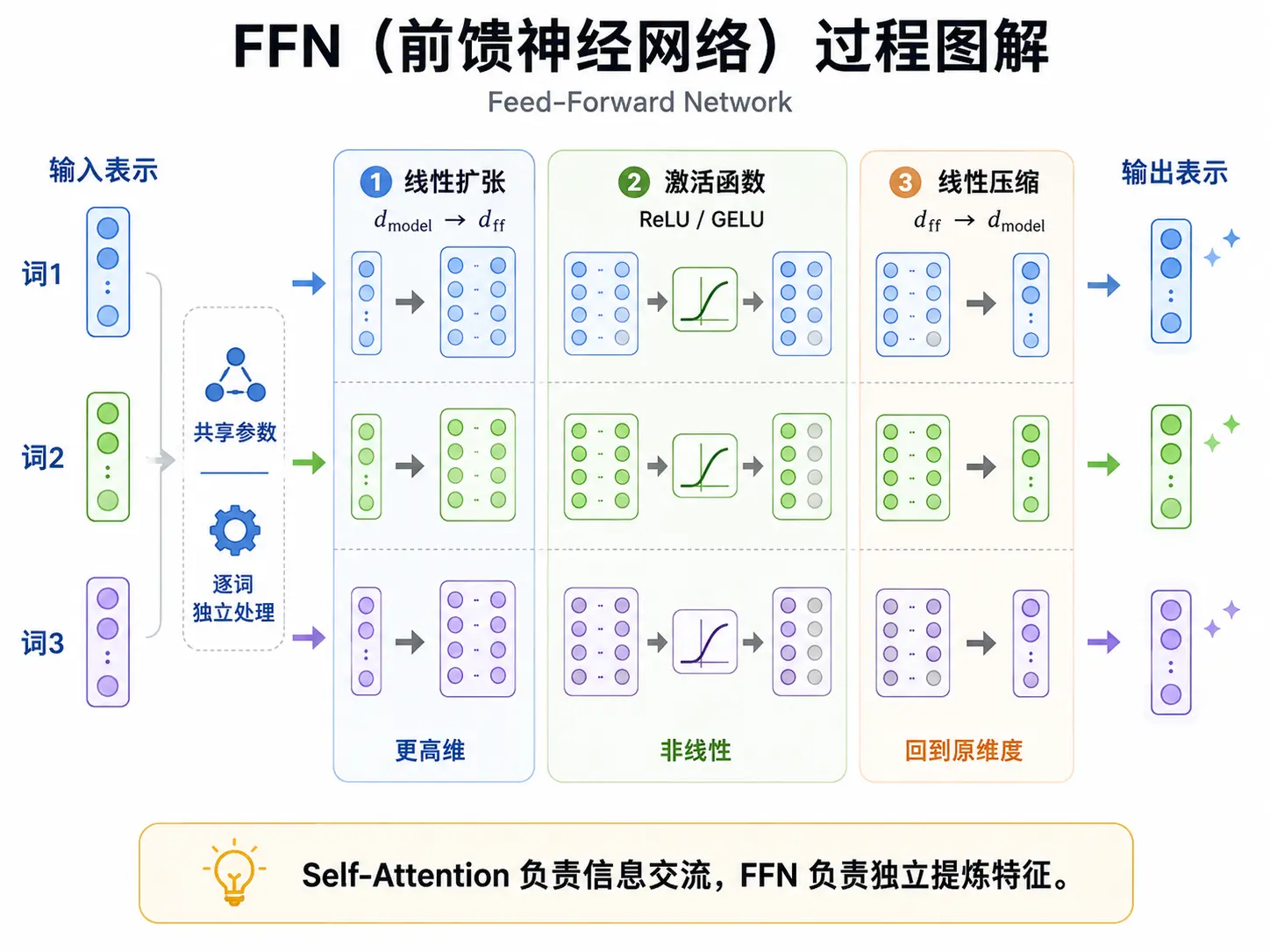
假设序列长度为 ,它表示一段话输入进 Transformer 的长度。 用于表示批次大小 (Batch Size),表示从 HBM 运送的权重可以被 连续用来计算 的句子的数量。
在维度扩张的阶段,先把输入进来的、维度为 的词向量,乘以一个巨大的权重矩阵,通常这个放大的倍数是 4 倍,也就是变成 。
这是一个经验公式,具体情况请根据实际给出确定:。
因为放大倍数和使用的函数不同,可能会导致数据量的不同,一般会具体给出。
嵌入查找
嵌入查找 (Embedding Lookup) 是一个非常简单的算子,它就是一个纯粹的 搬运。想象一下,你手里有一串书号(单词的 索引 ID),你的任务是去一个巨大的图书馆(内存中的 词表)里,根据书号把对应的书(高维向量)一本一本地搬出来。
在计算机眼里,这个过程的效率分布极不均匀:
- 计算量 (FLOPs):几乎没有。并不需要对书里的内容做加减乘除,你只是在做寻找和复制(Gather)。
- 数据量 (Bytes):非常大。你需要从内存中拉取极其庞大的词表数据到处理器中。由于词表通常很大,搬运的速度完全取决于内存带宽。
其计算强度大约为 FLOPs/Byte。这意味着:为了每 1 次计算,计算机必须先搬运 10 个字节的数据。在性能图谱上,这是一个典型的 带宽受限 (memory-bound) 算子。即便你的显卡算力再强,如果显存带宽不够快,嵌入查找就会成为整个系统的瓶颈。
AI 算子总结与回顾
下表总结了这些常见的 AI 算子的计算量特征和数据量特征。
| 算子名称 | 计算量特征 (FLOPs) | 数据量特征 (Bytes) | 算术强度倾向 (I) | 典型瓶颈区域 |
|---|---|---|---|---|
| GEMM (通用矩阵乘法) | 高:。 | 中 / 低。高度依赖 Tiling(分块)技术。如果不分块,访存极高;如果利用 L1/SRAM 缓存,访存大幅降低。 | 高 | 计算瓶颈 (Compute Bound)。 |
| Attention (自注意力) | 较高。。 | 极高。 | 中 / 低 | 内存瓶颈 (Memory Bound)。 |
| Conv (卷积) | 高:。 | 中。 | 高 | 计算瓶颈 (Compute Bound)。 |
| FFN (前馈神经网络) | 极高: 通过增大 Batch Size () 可将算力推向极致。 | 中。 | 极高 | 计算瓶颈 (Compute Bound)。 |
| Embedding Lookup (嵌入查找) | 极低。几乎没有真正的乘加运算,约 FLOP/Byte。 | 极高。需要从庞大的显存(HBM)中进行随机、离散的读取。 | 极低 | 内存瓶颈 (Memory Bound)。 |
接下来我们通过一些实践来可一下具体使用:
Q4: GPU Attention Bottleneck
假设一个 GPU 的峰值算力 TFLOPS,其 HBM 内存带宽为 TB/s。在 FP16 下,有一个标准的自注意力机制运算:, 。
- (a). 计算 和 的计算量(忽略归一化函数的消耗)。
- (b). 假设每一个张量都读/写一次 HBM,计算 的 HBM 总流量。
- (c). 计算其算术强度、实际性能及其利用率,并判断其瓶颈。
对于自注意力机制的题目,我们要明确其矩阵乘法的次数: 是 的,每个元素 次; 是 的,每个元素 次。
- (a). 两个矩阵乘法的计算量都是: FLOPs MFLOPs.
- (b). 都是 的矩阵,而 是 的,所以总流量为: MB.
- (c). 总计算量为 MFLOPs,所以 FLOPs/Byte。GPU 的拐点可以很容易计算: FLOPs/Byte。很明显,,所以在 GPU 上标准的自注意力机制计算是 内存受限型 (memory-bound)。 接下来,继续计算实际性能得到: TFLOPS,在 GPU 上其利用率为:.
NPU 数据流
在之前的学习中,我们知道了 AI 算子中最常见的操作就是乘后加,即 MAC。每一次 MAC 可以定义为:。
- :输入的激活特征。
- :模型参数。
- :部分和,表示中间累加结果。
现在问题是,如果每次 MAC 都从 HBM/DRAM 里重新读取或写入 activation、weight、partial sum,计算单元会一直等数据,NPU 的高 TOPS 就浪费了,此时是内存受限 (memory-bound)。
因此 NPU 优化的原则就是:尽量减少 DRAM/HBM 的访存。
既然去仓库 (HBM) 太慢,我们就需要在离得更近的 L1 缓存 (SRAM) 或更近的 计算单元寄存器 (RF) 多放点东西。
脉动阵列
脉动阵列 (Systolic Array) 是一种典型的并行计算架构,其核心思想是让数据在处理单元(PE)阵列中像血液一样按节奏流动并被多次复用。
数据处理的 计算单元 (PE,Processing Element),在处理每一个 MAC 时,它会做:拿一个激活特征与一个对应的权重相乘,并加到部分和上:。
在 NPU 中,很多个 PE 被排成一个二维网格,这样的网格就是脉动阵列。它们之间通过一个“有节奏”的传送带相连,数据有节奏地流过 PE 阵列,每个 PE 计算后把数据传给邻居,从而减少全局内存的读写。
它就像是个流水线工厂,将复杂的计算任务拆解为多个连续的阶段,使数据在各个处理单元间有节奏地流动,最后输出成品。如下图展示了脉动阵列的核心思想和流程。注意:图中的输入激活和权重的传递并不代表实际情况,接下来我们会在数据流中讨论。
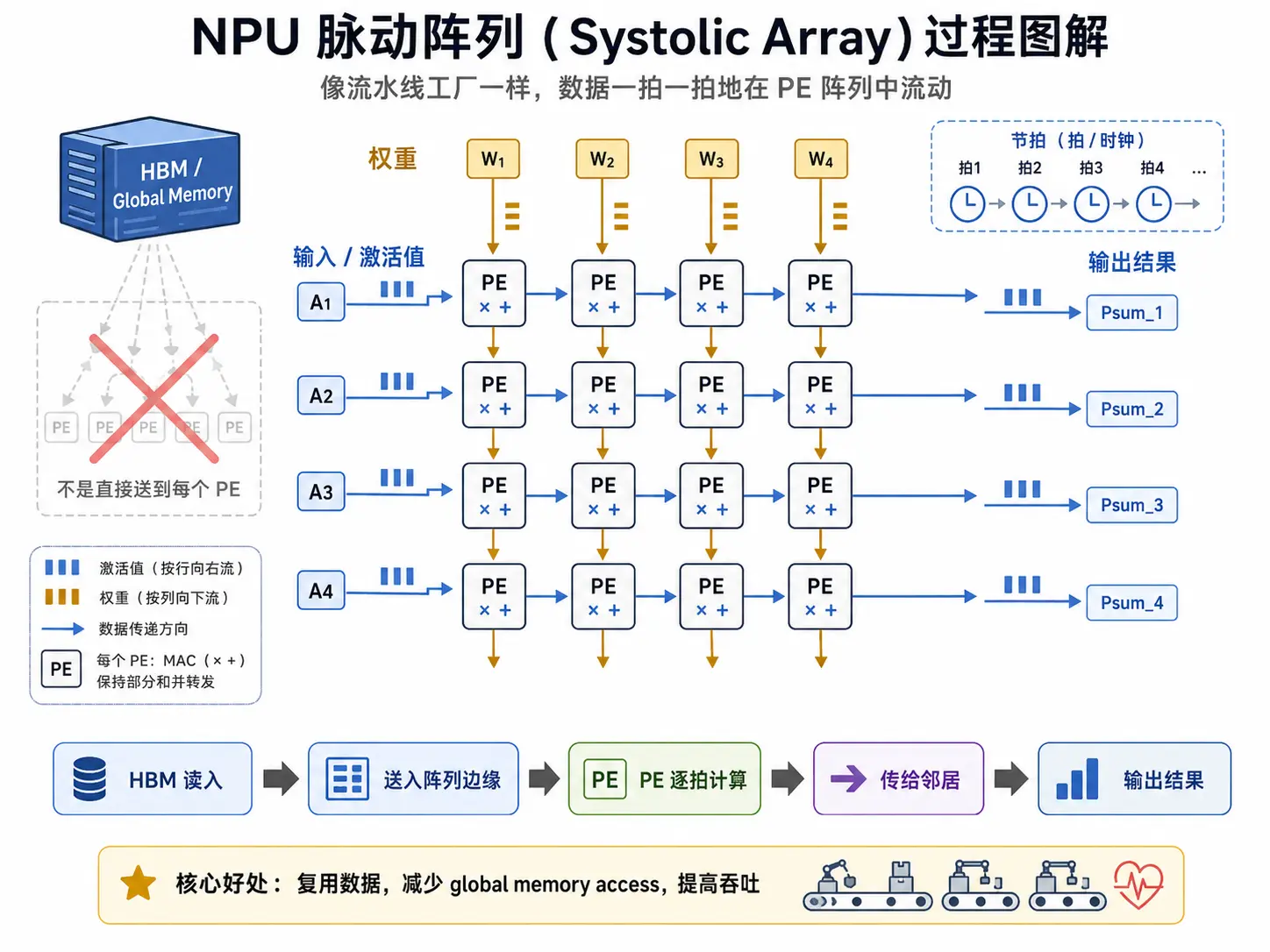
数据流
了解了脉动阵列结构后,数据流 (Dataflow) 就很好理解了。数据流就是一个”排班表”,它通过 驻留 (Stationary) 策略,决定哪些部分留在 PE 中复用,哪些需要在脉动阵列中随着流水线一步步传输。对于我们一次 MAC 需要的三类数据:, 和 ,我们有三种典型选择:
| Dataflow | 留住谁 | 流动谁 | 具体操作 |
|---|---|---|---|
| 权重复用 (Weight Stationary, WS) | weights | activations / partial sums | 权重固定,输入流过来 |
| 输出驻留 (Output Stationary, OS) | partial sums | weights / activations | 中间结果固定,慢慢累加 |
| 行驻留 (Row Stationary, RS) | 尽量保留卷积行相关数据 | 复杂调度 | 同时利用多种复用 |
不同的数据流策略直接影响了硬件的能效比和访存带宽需求。通过在 PE 内部缓存特定的数据,我们可以最大限度地减少昂贵的片外存储访问 (HBM)。接下来,我们将分析最常见的 权重复用(Weight Stationary)策略。
权重复用
权重复用 (Weight Stationary, WS) 是最常用的策略,它的逻辑很简单:在计算过程中,把 权重 尽量固定在计算单元 PE 附近,不要反复从 HBM 读取。在很多 AI 层里,尤其是 卷积、线性层 (Linear layer)、FFN (前馈神经网络),中,特别是当 Batch Size (B) 较大时,同一组权重需要与无数个输入数据相乘。通过 WS,我们 只需从 HBM 加载一次权重,就能完成成千上万次计算,极大地降低了能耗。
以典型的脉动阵列为例,WS 的执行过程如同一个精密编排的流水线:
- 预载权重(Weight Loading):在计算开始前,先把权重矩阵灌入 PE 阵列。每个 PE 内部的寄存器都会锁死一个或一组 ,在这一轮批处理完成前,它们保持静止。
- 激活值水平流入(Activation Flow): 从阵列的左侧逐行流入。它像流水一样掠过每一个 PE。每经过一个 PE,数据就与该 PE 保存的固定的 做一次乘法。
- 部分和竖直累加(Partial Sum Accumulation):每个 PE 乘出的结果不会立即存走,而是与从上方传来的中间结果 进行累加,然后传给下方的 PE。这种竖直方向的接力,完成了矩阵乘法中的加法环节。
- 终值写回(Output Write-back):当累加流到达阵列的最底部时,它已经包含了整列计算的完整结果。此时,这个最终的 才会穿过漫长的路径,写回到 SRAM 或远端的 HBM 中。
如图展示 WS 的全过程。
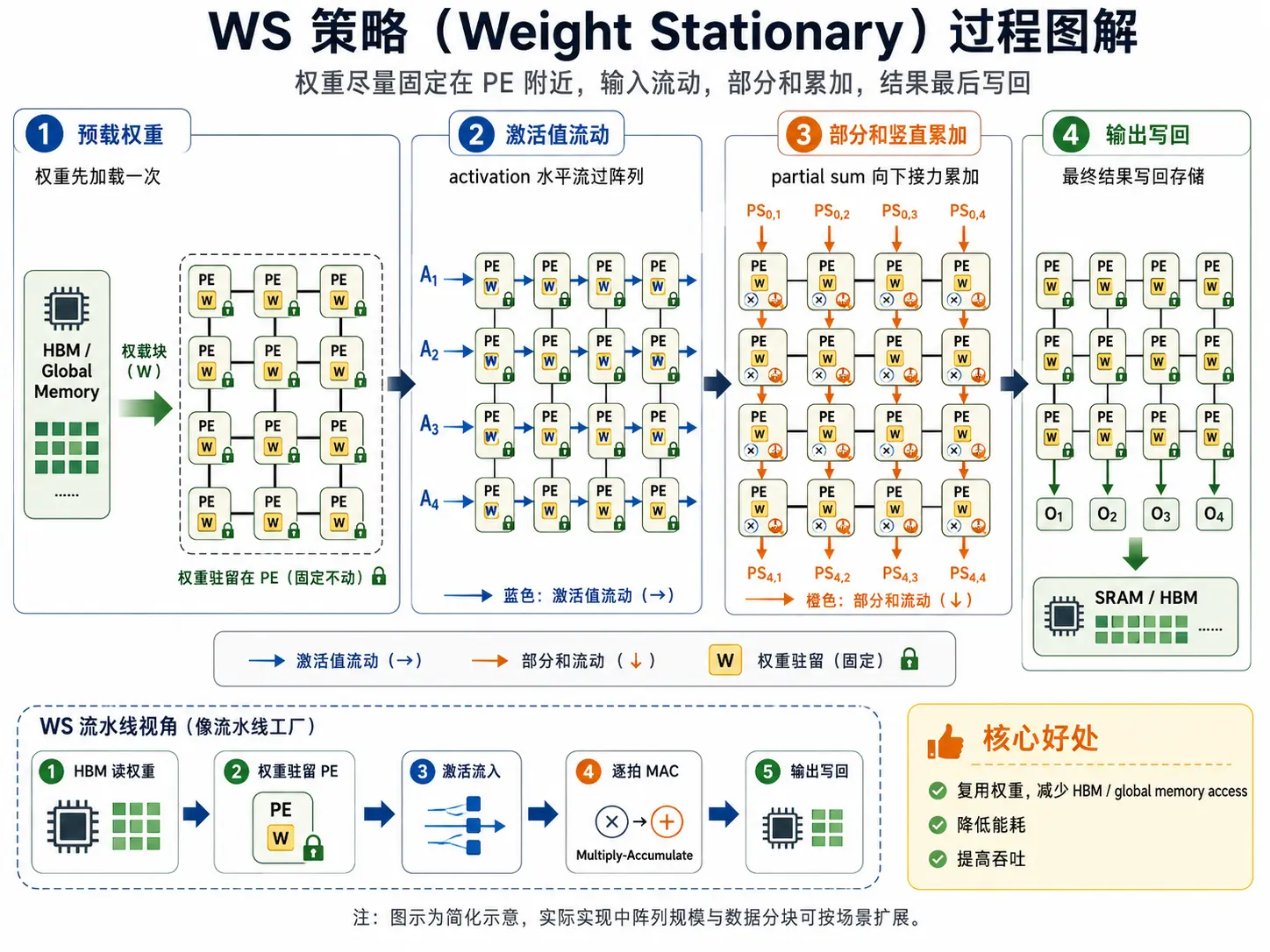
回到 Roofline 模型中,WS 策略能显著提高计算强度。。
WS 不减少计算量,而是减小了数据读取量。原来的 每次都从 HBM 读取,读取数量很大,计算单元几乎都在等待数据的传递。现在 被放到 SRAM/RF 中重复使用,HBM 的数据流量就显著下降了,自然计算强度就提升了。此时拐点 会 向右移动,让计算更容易达到 计算受限 (compute-bound)。
输出驻留
输出驻留 (Output Stationary, OS) 与 WS 不同,它的核心是让输出的 中间累加结果 留在 PE 里不动,其他数据流过来,不断把结果加上去。它的流程更像是一个工人在自己的工位上做一个半成品:材料一批一批送来,每来一批加工一次,直到最后成品再送走。
在矩阵乘法或卷积中,一个输出元素不是一次乘法就算完的,而是很多次乘加累积出来的。
假如有 ,如果一个输出元素:,OS 的做法是让一个 PE 负责这一个输出元素,它的累加值 就一直留在里面, 和 的数据不断流过来,每来一对 ,,就乘一下并且累加到累加值上,直到累加完成才向内存写回该数据。
OS 同样可以减少 HBM 的数据读写,以提高计算强度 。
对比 WS 和 OS,可以发现它们适用场景的不同。简单来说:
- WS 解决的是 权重 被反复读取 的问题;
- OS 解决的是 累加值 被反复读写 的问题。
| 对比 | WS | OS |
|---|---|---|
| Stationary 的数据 | Weight | Output partial sum |
| 流动的数据 | Activations / partial sums | Weights / activations |
| 主要减少 | weight HBM traffic | partial sum 反复读写 |
| 直觉 | 权重像固定工具,输入流过来 | 半成品固定,材料流过来 |
| 适合场景 | 权重复用强的 Conv / FFN, 批次很大 | 输出累加链很长的 GEMM / Conv,批次很小 |
NPU 优化回顾
NPU 采用了脉动阵列结构,为不同的场景应用不同的数据流,减少了可复用数据重复读写 HBM 导致的数据量增大的问题,从而提高了计算强度。接下来我们通过一道题目来回顾这个过程。
Q5: NPU Dataflow — Weight Stationary
假设一个 NPU 的峰值性能 TOPS,HBM 带宽为 GB/s。在 FP16 下,有一个卷积层 (Conv) 的输入数据流为 MB,权重为 MB,输出为 MB。其计算量为 。
- (a). 计算朴素情况(Naïve,没有 WS 策略)下的计算强度,并判断其瓶颈。
- (b). 如果 NPU 使用了权重复用 (WS) 策略的数据流,权重在芯片上的 SRAM 上复用了 100 倍,重新计算 HBM 的流量及其计算强度。
- (c). 重新分析瓶颈所在,并解释为什么数据流的选择这么重要。
- (a). 在朴素情况下,类似其他处理器,其数据量为 MB。此时可以得到计算强度 OPs/Byte。当然,我们还要计算这个 NPU 的计算强度拐点 OPs/Byte。很明显,,此时是 计算受限型 (Compute Bound)。当然因为它离拐点比较近,其受算力受限的程度不算很大。
- (b). 如果 NPU 采用了 WS 策略,根据题目,权重因为复用,使其减小了 100 倍, MB,所以此时的数据量变化为 MB,此时的计算强度为 OPs/Byte。对比 和 可以发现,,此时这个卷积运算变成更加稳定的 计算受限 Compute Bound。
- (c). 因为 NPU 的 HBM 带宽有限,如果不采用 WS 数据流策略,卷积运算将更靠近峰值点 。在运算中,实现不一定总能满载,任何实现上产生的低效,例如步长访问、数组利用率不足等,都可能使它小于峰值点。WS 策略相当于提供了更多的冗余 (safe margin),数据流让计算锁死在峰值算力的概率更高了。
基于 Roofline 的架构优化方案
我们使用 Roofline 模型可以量化模型的性能是受限于算力还是内存,而所有基于 Roofline 模型的优化技术本质上只会改四件事:
| 改变对象 | 意义 | 代表技术 |
|---|---|---|
| 提高有效计算峰值 | Structured Sparsity | |
| 提高有效带宽 | Quantization / Compression | |
| 提高 Arithmetic Intensity | Flash Attention / Fusion | |
| 利用率 | 提高实际执行效率 | Batching / Kernel optimization |
这一章主要介绍四种常见的优化技术:结构化稀疏 (Structured Sparsity),量化 (Quantization),Flash Attention 以及批处理 (Batching).
结构化稀疏
在 AI 模型中,很多权重其实是 。传统的 GPU 碰到 ,依然会傻傻地算一遍。而 结构化稀疏 (Structured Sparsity) 的核心思想是:在结构化的权重中,既然乘以 0 没意义,那就跳过这些乘法。
非结构化的稀疏 (Unstructured sparsity) 指的是权重中,0 可能随机出现在矩阵各个位置。在这种情况下,硬件很难去预测哪些地方是 0, 从而引入不小的复杂度。
而结构化的稀疏 (Structured sparsity) 中,0 都是按固定规则出现,因为模式固定,硬件可以很容易跳过这些乘法。
在 NPU 中引入了 2:4 稀疏化技术 (2:4 structured sparsity):在权重中,每 4 个数字中固定有 2 个是 ,硬件可以直接跳过这 2 个 不算,例如 [w1, 0, w3, 0] 或 [0, w2, 0, w4]。
通过 2:4 稀疏化技术,在同样的时间内,硬件能完成的 有意义运算 变多了。虽然理论上 算力翻倍,但实际调度有损耗 ,有效峰值算力 。算力变大,意味着 Roofline 的 平坦屋顶向上抬高了。同时,拐点 () 会向右移动 。如果你本来是 Compute Bound,你的性能会瞬间提升。所以 只有高 AI workload 才能真正吃到结构化稀疏带来的性能提升。
量化
量化 (Quantization) 就是在把数据类型变小。我们知道,常见的数据类型及其大小如下:
| 数据类型 | 每个元素大小 |
|---|---|
| FP32 | 4 Bytes |
| FP16 | 2 Bytes |
| INT8 | 1 Byte |
| INT4 | 0.5 Byte |
假设原本采用了 FP16 的数据类型,现在我们使用量化将其压缩到 INT4。原来一个 weight 用 FP16 存,需要 2 Bytes。现在用 INT 4,只需要 0.5 Byte。
计算依然是那么多,但数据变小了。这就相当于硬件的 有效内存带宽 () 增大了,在同样的带宽下,能搬的数据更多了。
在 Roofline 模型中,量化通过减少搬运的数据量,直接提升了计算强度 。假设 INT4 使得有效带宽翻倍:,那么拐点将变成:,这意味着 Roofline 的 斜坡变得更陡峭了,同时 拐点 () 会向左移动。模型更容易进入算力受限区,从而更充分地发挥硬件的峰值性能。这种变化显著缓解了访存瓶颈对推理速度的制约,使得原本受限于带宽的任务在量化后能获得接近翻倍的性能提升。同时,这也为模型在端侧等带宽受限设备上的高效运行提供了理论依据。
当然量化会导致 精度 (numerical accuracy) 损失,这一点在 注意力权重 (attention scores) 和 归一化函数 (normalization) 上尤为明显。
Flash Attention
我们在标准的自注意力机制上,有 ,。如果序列长度 很大,计算 矩阵的显存占用和计算复杂度将以 的量级增长,这会严重限制模型处理长序列的能力。标准 Attention 会把这个 矩阵先写到 HBM 中,再读回来做归一化,再产生另一个 的概率矩阵。在长序列中, 一般会超过 L2 cache,迫使系统访问 HBM,导致 HBM 的数据量爆炸。
Flash Attention 的核心是:不要把完整的 的 矩阵存回 HBM 中。而是通过引入 分块计算和重计算技术, 在 SRAM 中分块计算注意力分数矩阵 ,通过 在线归一化 (online softmax) 去维护中间统计量,彻底消除了 矩阵的 HBM 访存,从而 减少大量的 HBM 流量,在不增加显存负担的情况下实现了更高的计算效率。具体的 Flash Attention 的设计方法这里就不展开了,因为这一部分主要在于分析各种方案如何优化 Roofline 模型的。
因为去除了自注意力机制中所占用最大的 HBM 读写,数据量急剧减小,这导致计算强度 得到急速上升,拐点 会发生 剧烈的向右移动,实际的性能 也会随之提升。
Batching
批处理 (Batching) 是一次处理多个样本,共享同一批权重的方法。它可以有效提高利用率,均摊权重的开销。例如我们之前在 NPU 中提到的 WS 数据流方法。MAC 利用率会随着批处理的大小 (batch size) 增大而提高。
当然 Batching 不是越大越好,批处理会导致延迟的增加,导致瓶颈的转移,这一点在之后的 Q9 中可以看到。在线 LLM 推理中,批处理太大会让单个用户等待更久;离线训练或批量推理中,批处理大通常更划算。
AI 架构优化回顾与总结
总结以上的优化方案可以得到:
| 优化方案 | 核心思想 | 主要改变的量 | 对 Roofline 表现的影响 | 可能导致的瓶颈变化 |
|---|---|---|---|---|
| 结构化稀疏 (Structured Sparsity) | 按固定模式跳过无效的 zero MAC,例如 2:4 稀疏 中每 4 个 weight 只计算 2 个非零值 | 主要 提高有效计算峰值: | 峰值性能被抬高;如果原 workload 已经 compute-bound,则可能获得更高性能 | 可能从 compute-bound 继续保持 compute-bound,但拐点也会升高。因此 workload 会变得更依赖足够高的计算强度;如果计算强度不够,可能反而更接近 memory bottleneck |
| 量化 (Quantization) | 用更低的数据类型表示数据,例如 FP16 → INT8 → INT4,减少每个元素的 byte 数 | 提高有效带宽: | 内存受限区域的斜率变陡;拐点左移: | 对 memory-bound workload 最有效,可能使其从 memory-bound 变成 compute-bound;如果原本已经 compute-bound,收益可能较小 |
| Flash Attention | 不把完整 的 矩阵写入 HBM,而是分块计算并用 online softmax 在 SRAM 中避免中间矩阵的生成,彻底 消除了最大的数据量 | 主要减少 HBM 流量,使 | 实际的计算性能提高 ,整体向右移动。 | 标准 Attention 常是 memory-bound;Flash Attention 可能把它变成 compute-bound,尤其在长序列场景下非常明显 |
| 批处理 (Batching) | 一次处理多个样本,本质上降低了 weight loading 的开销,提高 PE/NPU array 的利用率 | 主要 提高利用率,在权重复用场景中也提高了计算强度。 | 不一定改变理论 Roofline 的 或 ,但会让实际运行的利用率变高。 | 小 batch 时可能是 compute under-utilization;batch 增大后 compute 利用率提高,但 activation transfer、PCIe/interconnect traffic 也增加,可能把瓶颈转移到 data movement / PCIe |
我们同样通过一道题目来解析这些优化方案。
Q6: Optimization Techniques on the Roofline
给定一个 NPU 的峰值性能为 TOPS,HBM bandwidth 为 GB/s。一个 Transformer FFN 计算在这个 NPU 上的计算强度为 OPs/Byte。
- (a). 如果该 NPU 支持 2:4 结构化稀疏方法,其中存在 50% 的 0,理论可以提升 2 倍的计算峰值,实际上的 MAC 利用率为 75%, 计算有效计算峰值和新的拐点,并判断它的瓶颈。
- (b). 如果一个 INT4 的量化应用在当前 NPU 上,这会导致有效带宽提升 2 倍,这会对拐点和斜坡区域有什么影响?如果工作负载属于内存受限型,性能提升倍数会是多少?
- (c). Flash Attention 通过避免 矩阵的存取,从而减少了 HBM 流量。请解释 Flash Attention 如何改变 Roofline 图表上操作点 (Operating Points) (向右偏移、向上偏移,还是两者兼有?)
对于给出的 NPU,我们可以先计算其原始的拐点作为参考。 OPs/Byte。与题目初始给出的 FNN 计算强度对比:,所以这个 FNN 计算在这个 NPU 上是 算力受限型 (Compute-bound)。
- (a). 题目提到使用了 2:4 结构化稀疏方法,既然有一半是 0,理论上就可以跳过一半乘法,所以理论提升为 2 倍,但实际开销中打不到,利用率为 75%。所以我们可以计算提高的有效计算峰值: TOPS。此时新的拐点 OPs/Byte。可以发现,这个整体的屋顶被抬高了,新拐点 升高了,但是 ,说明 FFN 仍然是 算力受限型 (Compute-bound)。所以此时 TOPS。
- (b). 根据题目描述,通过我们量化后, GB/s。我们重新计算拐点: OPs/Byte。对比之前的拐点,,几乎下降了一半,拐点左移。在内存受限区域内,,此时因为 翻倍,实际性能上限 ,这导致斜率变成原来的 2 倍。如果原本的 workload 是 memory-bound,那么它们的性能得到了翻倍,如果量化后 workload 跨过拐点,性能会被峰值性能 截断,不能无限增长。对于本题的 FNN 计算而言,量化没有提高峰值性能,只是在真实系统里减少数据搬运能耗和延迟。
- (c). Flash Attention 消除了 矩阵对 HBM 的存取,大大减小了数据量。因为 ,这导致操作点 向右移动。至于会不会向上移动,我们需要分类讨论:
- 如果 workload 原本在 memory-bound 区域:,随着计算强度 的增加,其性能 将沿着带宽受限的斜率向上移动。如果它跨过拐点,则会被限制在峰值算力上。
- 如果 workload 原本已经 compute-bound:,此时 再增加,点继续向右,但纵向的性能不再上升,因为已经被峰值性能限制。 所以,Flash Attention 一定让点向右移动;如果原来 memory-bound,还会向上移动;如果跨过 ridge point,就会从 memory-bound 变成 compute-bound。
分层 Roofline 模型与空间局部性
我们的计算机里不是只有一种内存。你可以把它想成一个“仓库系统”:
- 寄存器 PE / Register File:例如手边的工具盒,最快、最小。
- L1 Cache:例如车间的小货架,很快、较小。
- L2 Cache:例如车间共享仓库,快、中等容量。
- HBM / DRAM:例如远处大仓库,容量大、慢、贵。
- PCIe / Network:跨设备运输,最慢、最容易变瓶颈。
在普通 Roofline 中只有一个 bandwidth :。
但真实系统有很多个 ,对于不同的 ,每一层都有自己的拐点:。我们将这样多层的 Roofline 模型称为 分层 Roofline (Hierarchical Roofline)。
分块技术
当我们在算力强大的芯片上运行普通的矩阵乘法时,如果不做任何优化,每次 MAC 都去 HBM 拿数据,算术强度极低,必定会触发Memory Bound。这个过程中计算单元一直等数据。
分块 (Tiling) 的思想是:不要一次处理整个大矩阵,把大矩阵切成小块,让小块放进 L1 / L2 / SRAM,在片上反复使用,最后再写回 HBM。
分块通常不改变计算量 FLOPs,而是减少了 HBM 的存取次数,也就是减少了数据量,所以导致计算强度 增大。
分层 Roofline 的分析
接下来我们通过一个例子去分析分层 Roofline 模型。
Q7: Hierarchical Roofline & Caching
假设一个 CPU 的峰值性能 TFLOPS。在这个 CPU 上运行的一个 workload 分为两个阶段如下表:、
Phase 占比 Memory Level Bandwidth AI Phase A 30% L1 10 TB/s 15 FLOPs/Byte Phase B 70% DRAM 200 GB/s 150 FLOPs/Byte
- (a). 计算 L1 和 DRAM 的拐点,及其遇到的瓶颈。
- (b). 假设阶段 A 占 30% 的运行时间,阶段 B 占用 70%。计算整体的有效性能 (加权调和平均值),并解释优化峰值性能对其的作用。
- (c). 如果我们使用分块技术,使得 Phase B 的 50 % 的数据来自 L2 ( TB/s, FLOPs/Byte),量化说明 Roofline 模型的转变。
- (a). 我们可以分别计算 CPU 在 L1 和 DRAM 的拐点。 TFLOPS, TB/s, FLOPs/Byte;同理, GB/s, FLOPs/Byte。 对于题目给出的 ,所以 Phase A 是 算力受限型 (Compute Bound)。同样的,,所以 Phase B 也是 算力受限型 (Compute Bound)。
- (b). 因为两个阶段都是算力受限型,所以 TFLOPS。对于整体而言,我们加权计算: TFLOPS,所以有效性能也是 2 TFLOPS。此时继续优化峰值性能没什么意义,因为在真实系统里,有效的 L1 bandwidth 不一定能达到理论值,可能受各种因素影响,例如协议效率、内存冲突、突发效率等等。如果这导致了 Phase A 变成 memory-bound,改善 不如增加缓存带宽或改善局部性。瓶颈并不只在峰值性能上,还可能出现在内存层次结构的任何层级。
- (c). 我们先计算 L2 的拐点, FLOPs/Byte,给定 。所以在 L2 上进行的 Phase B 的一部分也是 算力受限型 (Compute Bound)。如果 Phase B 有 50% 数据来自 L2,你重新计算还是会发现 , 但是,Phase B 的执行时间会下降,因为原来从 DRAM 读的数据,现在一半来自 L2。L2 bandwidth 是 2 TB/s,DRAM 是 200 GB/s,也就是 L2 带宽约 10×。此时的主要收益是延迟下降了。
空间局部性及其分析
在 GPU 这种拥有超高 HBM 带宽的硬件上,嵌入查找(Embedding Lookup)往往跑得很慢。原因不在于带宽总量不够,而在于 带宽利用率极低。这可能涉及 空间局部性 (Spatial Locality)。
在硬件底层,内存访问通常是以缓存行(Cache Line)或内存突发(Burst)为单位进行的。计算机的内存总线(HBM/DRAM)是非常“死板”的。例如,当你向内存索要 4 个字节时,硬件底层并不会只给你那 4 字节,而是会把周围相邻的 32 或 64 字节 一整行数据 全部打包塞给你。
如果你的程序是按顺序、挨个读取数据的(比如图像处理或矩阵乘法)。HBM / DRAM 拉取到 1 缓存行的数据,处理器能全部将其用完。此时硬件的有效带宽 = 物理理论带宽。
- 如果你在做矩阵乘法,数据是顺序排列的。硬件拉回来 64 字节的一整行,你刚好接下来就要用到这整行的所有数据。此时,每一比特的搬运功劳都没白费,你的“有效带宽”就等于“理论带宽”。
- 但在推荐系统或搜索业务中,你是在几百万行的词表里“随机”查生词。你只需要第 100 行和第 100 万行的某几个字节。由于硬件必须“整行拉取”,结果就是你的带宽利用率极低。
接下来通过一个例子来看看这种极端情况。
Q8: Recommendation System & Extreme Memory Bound
假设一个 GPU 的峰值性能为 TFLOPS, TB/s。有一个推荐系统 DLRM 的嵌入查找运算部署在这个 GPU 上面,它每传输 1 Byte 数据大约消耗 0.1 FLOP 计算量。
- (a). 计算嵌入查找的计算强度,实际性能及其 GPU 利用率。
- (b). 从架构层面解释两个原因,说明为什么 GPU 尽管峰值性能很高,但在嵌入查找运算下性能却不佳。
- (c). 给定一个专用的 NPU 以支持 4-bit 的嵌入压缩,它的 HBM 带宽为 TB/s。它还集成了一个 MB 的片上 SRAM 缓存。性能分析显示,90% 的嵌入式查找操作都能命中该缓存。SRAM 的带宽为 TB/s,而未命中的查找操作则由 HBM 处理。使用加权的有效带宽公式,去估算有效带宽,并计算其实际的性能,相当于 (a). 的多少倍。最后解释为什么使用这样专用的 NPU 是合理的。
,其中 表示其缓存命中率。
在原本的 GPU 上,我们先计算其拐点: FLOPs/Byte。
- (a). 我们根据题目的描述,可以推断出嵌入查找运算在 GPU 上的计算量为 FLOP,数据量为 Byte,所以 FLOPs/Byte。此时 ,这是一个很严重的 内存限制型 (Memory Bound)。所以其实际性能为 TFLOPS。利用率为 Utilization ,其利用率极低。
- (b). 为什么 GPU 不适合嵌入查找呢,从两个角度分析:
- 原因一:访问模式太随机。针对 SIMT/Warp 的连续合并访问模式 ,GPU 进行了专门优化。而嵌入查找表现出随机、稀疏的聚集-分散访问模式,这种模式会破坏缓存局部性并导致严重的 Warp 发散。内存子系统无法利用空间局部性。
- 原因二:算子本身的计算强度太低。这是一个纯内存查找,计算量微不足道。无论计算峰值多高都无济于事,因为瓶颈本质上是数据移动。GPU的庞大计算阵列空闲着等待内存的数据。
- (c). 根据提供的加权公式,代入 TB/s, TB/s,以及 ,我们可以计算出 TB/s。此时实际的性能为 TFLOPS。这对比 (a). 中我们计算的结果 Speedup x。 我们分析 (a) 和 (c) 可知:当 时,唯一能提升的就是有效带宽 。因为 GPU 缺乏用于热嵌入的大容量、低延迟 SRAM 缓存,以及对应的地址生成逻辑,很难为嵌入查询提供所需的有效带宽。我们发现,即使有 90% 的缓存命中率,10% 的 HBM 未命中会将有效带宽拖低至约 TB/s,但这仍然是原始 GPU 的 43 倍。需要使用专用设计的 AGU、固定的功能解压方案和 100+ MB 的 SRAM 缓存的专用 NPU 是推荐系统设计的最大瓶颈。
系统级建模
异构系统
在 AI 不断发展的今天,对计算能力的需求正以前所未有的速度增长,传统的单一处理器架构已难以满足高效处理海量数据的需求。
异构系统 (Heterogeneous System) 将一个复杂的 AI 任务(Workload)根据计算特性的不同,分发给不同类型的硬件去处理。在异构系统中,硬件之间通过 高速互连(PCIe, NVLink 等) 紧密配合。让最合适的硬件干最合适的事。处理同样的 AI 任务,异构系统可能比纯 CPU 集群能效高出数十倍,且延迟更低。
对比我们常见的硬件设施,可以分析出其擅长和不擅长的方向:
| 硬件 | 擅长什么 | 不擅长什么 |
|---|---|---|
| CPU | 串行控制、分词 (tokenization)、采样 (sampling)、嵌入查询 (embedding lookup)、复杂逻辑 | 大规模密集型矩阵乘法 |
| GPU | 高并行密集型计算、Flash Attention、memory-bound element-wise ops | 极端随机访问、小 batch 串行控制 |
| NPU | 规则矩阵乘、FFN、Conv、脉冲阵列 (systolic array)、结构化稀疏 (structured sparsity) | 不规则控制流、随机 gather/scatter |
| PCIe / interconnect | 负责设备之间搬数据 | 带宽远低于 HBM / SRAM,容易成为瓶颈 |
在一个异构系统中,不是谁最快就用谁,而是匹配 哪些算子适合哪个硬件。
对于一个端到端的异构系统而言,其延时计算非常重要。最常用的延时计算公式是 。
- :CPU 预处理。这是数据进入加速器之前的准备工作。CPU 会根据不同的任务为数据进入 GPU/NPU 之前做准备。这些任务充满了复杂的逻辑判断和不规则的内存访问,必须由具备强大逻辑控制能力的 CPU 串行完成。
- :异构数据传输。把 CPU 内存(DRAM)准备好的数据,通过系统总线拷贝到加速器(GPU/NPU)的高带宽内存(HBM)中。主要途径是 PCIe 总线。
- :GPU/NPU 核心计算。这是在 GPU 或 NPU 上核心的数学运算,主要是极其密集的矩阵乘法,比如 注意力机制(Attention)和前馈网络(FFN) 等。
- :CPU 后处理。加速器算出一堆概率分布(Logits)后,需要送回 CPU 进行 采样(Sampling)和解码(Decode) ,这些任务都属于后处理部分。和预处理一样,这也是高度逻辑化和串行的工作。
这个简单的公式串联起一个完整的异构系统的例子,包含如下流程:
- CPU Prepocessing
- CPU to GPU/NPU transfer
- GPU/NPU compute
- GPU/NPU to CPU transfer
- CPU Postprocessing
在之后我们会有一个例子来计算一个异构系统中的延时。
阿姆达尔定律
如果系统里有一部分必须串行执行,当我们不断提高并行部分的速度时,整体速度最多能提升多少呢?
阿姆达尔定律揭示了一个残酷的硬件真相:一个系统的整体速度提升,并不取决于你最快的那部分跑得多快,而是取决于你最慢的那部分(串行部分)到底有多慢。
阿姆达尔定律的公式: ,其中:
- :系统整体的加速比(Speedup)。
- :必须串行执行的比例。
- :可以并行的比例,。
- :加速器的加速倍数(或处理器核心数)。
当加速器,即 GPU/NPU 无限快时,,公式可以简化为 。这说明只要串行计算部分存在,系统整体的加速比仍会受到该串行部分的严格限制。因此,在异构计算优化中,减少串行依赖 并提升代码的并行化程度,往往比单纯堆砌计算资源更为有效。
数据移动墙
在现代 AI 加速器中,我们经常看到一个尴尬的局面:计算单元(ALU)的频率已经拉满,但由于数据供不上,它大部分时间都在空转。这种由于数据搬运速度远赶不上计算速度而导致的性能瓶颈,被称为 数据移动墙 (Data-Movement Wall)。
在异构系统中,数据需要在不同的硬件之间穿梭,最典型的数据传输就是 PCIe。
在一个 NPU 中,HBM bandwidth 可能有 GB/s,而负责 CPU 与 NPU 之间传输数据的 PCIe bandwidth 可能只有 GB/s。内部与外部的带宽差了 8 倍。这意味着,即使 NPU 处理数据的速度再快,如果它需要频繁从 CPU 那里拿数据,它的实际表现就会被限制在 32 GB/s 的水平上。
因为数据移动墙的存在,设备内部的 Roofline 并不等于系统的 Roofline。如果你只看 NPU 内部运行的那一小段代码,它可能表现为 计算受限 (Compute-bound) 。一旦你把数据从主内存(DRAM)通过 PCIe 搬运的时间算进去,整个任务可能瞬间变成 内存受限 (Memory-bound)。
瓶颈转移
从上面的分析可以知道,PCIe 会严重拖慢异构系统的延迟。那么 PCIe 将一直是瓶颈吗?在异构系统中,瓶颈并不是永久固定在某个组件上的。
批处理(Batching) 是引发这种瓶颈转移最剧烈的杠杆。它本质上是通过 牺牲单次响应的延迟(Latency)来换取整体系统的吞吐量(Throughput)。
当 Batch Size 增加时
| 维度 | 增长方式 | 深度背后的原理 |
|---|---|---|
| CPU 串行开销 | Sub-linear (次线性) | “固定成本摊销”:无论 Batch 是 1 还是 128,CPU 启动内核(Kernel Launch)和调度指令的次数变动不大。Batch 越大,分摊到每个样本上的开销就越低。 |
| NPU 计算开销 | Sub-linear (次线性) | “权重重用 (Weight Stationary, WS)”:对于全连接层等,模型权重只需要从 HBM 读一次,就能给整个 Batch 的数据用。Batch 越大,计算相对于访存的比例(算术强度)越高。 |
| PCIe 传输开销 | Linear (线性) | “物理搬运”:每一份输入数据(Activation)都必须实打实地从内存搬到显存。Batch 翻倍,搬运的数据量就翻倍。 |
| 吞吐量 (Throughput) | 上升 (Up) | 由于 CPU 和 NPU 的效率提升速度快于开销增长速度,单位时间内处理的样本数显著增加。 |
| 延迟 (Latency) | 上升 (Up) | 显而易见,处理更多的数据、搬运更沉的负载,必然导致单个 Batch 完成的总时间变长。 |
在不同的批处理大小下,会呈现不同的瓶颈:
- 小 Batch 场景:由于计算量太小,无法填满 NPU 的数千个核心,此时系统往往受限于 CPU 串行调度延迟 和 PCIe 的传输延迟。
- 大 Batch 场景:NPU 的算力被充分压榨,CPU 变得清闲。但此时,由于数据量巨大,PCIe 带宽(甚至 HBM 带宽) 往往会先于计算能力达到顶峰。
接下来我们会通过一个例子来分析这种瓶颈的转移。
综合分析
Q9: Heterogeneous System & Amdahl’s Law — Bottleneck Shift
在一个端对端的大语言模型推理框架内,包含这样的一个 Pipeline:
- CPU 预处理:负责分词 (tokenization) 和 KV cache 的管理。当批处理大小为 时,它占用 15% 的运行时间。
- CPU 到 NPU 的数据传递 Transfer: 使用 PCIe 4.0 16,带宽为 32 GB/s。
- NPU 计算:计算自注意力和前馈神经网络 FNN,它的峰值性能是 TOPS,假设其达到了 计算受限 (Compute-bound)。
- NPU 到 CPU 的数据传递 Transfer: 使用 PCIe 4.0 16,带宽为 32 GB/s。
- CPU 后处理:包含采样 (sampling) 和解码 (decode)。当批处理大小为 时,它占用 10% 的运行时间。
在这个过程中,CPU 的串行开销随批处理大小的增长呈亚线性 (sub-linear) 增长,遵循公式:. 对于 时,NPU 所需的计算时间为 ,传输荷载 (Payload) 是 1 MB。
- (a). 在 下,计算 CPU 到 NPU 和 NPU 到 CPU 两个方向上的传输时间,以及总传输时间。然后计算端对端延迟,并确定主要瓶颈来源。
- (b). 使用阿姆达尔定律,计算如果 NPU 的运算速度能够无限提升时,其理论上的最大加速比 是多少。解释为什么 CPU 的串行调度会成为上限。
- (c). 现在将批处理增加到 。传输量呈线性增长,但 NPU 的计算时间仅增加到 1.9 倍(因为 WS 策略)。使用公式重新计算批次大小为 64 下的 CPU 串行的时间。并重新计算所有传输时间、新的端对端延迟,并确定新的瓶颈。瓶颈是否发生了转移?这对异构系统中的 Roofline 分析意味着什么?
对于一个如此复杂的异构系统中,我们要根据延时计算公式 算出系统跑 1 个数据()总共花多久。
(a). 首先是传输的时间 :,PCIe 带宽我们知道是 32 GB/s,假设传输 1 MB: . 因为 CPU 与 NPU 之间传递的带宽一致,那么来回传输的总时间为 。
那么并行部分与传输部分的总时间是:。根据题目我们知道,CPU 串行计算的时间占了 25%: ,那剩下的并行部分就占 75%。这样我们可以反求出端对端的总时间为 .
所以 CPU 串行部分的时间是:,其中,,.
整理一下 下的时间占比如下:
| 部分 | 时间 | 占比 |
|---|---|---|
| CPU serial | 187.5 μs | 25% |
| PCIe transfer | 62.5 μs | 8.3% |
| NPU compute | 500 μs | 66.7% |
| Total | 750 μs | 100% |
发现此时 NPU 的运算成为了瓶颈。
(b). 根据阿姆达尔定律,。即便 NPU 的算力达到无限大 ,,此时 . 最大理论加速比为 4x。这说明了哪怕 NPU 计算时间变成 0,CPU preprocessing 和 postprocessing 仍然存在。它们是不可消除的串行部分,所以系统最多只能快 4 倍。此时延迟最低为 。
(c). 当批处理大小 时,我们代入给出的公式可以计算 CPU 的串行开销: 。对于传输时间而言,因为批次增加,数据量变成 64 MB,传输时间暴涨:。
对于 NPU 的计算,其时间变成原来的 1.9 倍:。此时端对端的总延迟为:。
我们再次分析当前 下的时间分布:
| 部分 | 时间 | 占比 |
|---|---|---|
| CPU serial | 243.75 μs | 4.7% |
| NPU compute | 950 μs | 18.3% |
| PCIe transfer | 4000 μs | 77.0% |
| Total | 5193.75 μs | 100% |
此时瓶颈从 NPU compute 转移到了 PCIe transfer。
单独看 NPU,它可能是 Compute Bound;但在异构系统中,PCIe 这种硬件间的传输也必须被看成 内存分层 (memory hierarchy) 的一层。在大批次处理下 (),PCIe 的传输带宽会变成新的 Roofline 斜率,从而让整个系统撞到 数据移动墙(Data-Movement Wall)。
对于异构系统而言,我们可以计算一个系统级别的拐点: OPs/Byte,这个拐点比 NPU 自己的 HBM 拐点高得多: OPs/Byte。所以一个算子在 NPU 内部可能满足:,因此它在 NPU 上是 Compute Bound。但是如果考虑 PCIe 的整体系统中:,那么系统整体仍然可能是 Memory Bound。
最后是一个综合的问题,应用了全篇的知识。
Q10: Design & Exploration — Hybrid Transformer on Heterogeneous SoC
你正在设计一个用于基于 Transformer 的多模态模型的混合 CPU+GPU+NPU 的异构系统级芯片 SoC (System on Chip),该模型每个 token 的各层计算分布如下:
- 嵌入查询 (Embedding Lookup):0.1 FLOPs/Byte,必须在 CPU 上运行(大表,随机访问)。
- Self-Attention: FLOPs,其中 ,, 可以在 GPU 或 NPU上运行。
- 前馈网络 (FNN):,其中 ,可以运行在 NPU 上使用 2:4 稀疏化技术。
- 层归一化 + 残差连接 (LayerNorm + Residual):内存受限的逐元素运算,最适合在 GPU 上执行。
硬件参数如下表:
Component Peak Bandwidth Note CPU 1 TFLOPS 100 GB/s Handles serial ops & embedding GPU 1000 TFLOPS 2 TB/s Flash Attention available NPU 200 TOPS 256 GB/s WS/IS dataflow, 2:4 sparsity PCIe — 32 GB/s CPU↔GPU, CPU↔NPU 在批处理 时,CPU 串行调度的时间(包含嵌入,预处理和后处理)总占用 20% 的端到端延迟。在批处理 时,CPU 串行化调度时间大约为 。
- (a). 对于自注意力模块,比较在 GPU 上运行标准 Attentions 与 Flash Attentions 的情况。为两者分别计算计算强度 ,确定Roofline 区域,并决定将哪种技术分配给 GPU。
- (b). 对于分配于 NPU 的 FFN 计算,在批次大小 ,序列长度 的条件下,密集 FFN 的计算量 FLOPs ,HBM 流量为 MB。请计算 FFN 的计算强度 。然后应用 2:4 稀疏化技术 (实际利用率 75%,理论峰值性能提升 2 倍),计算此时的有效性能 及其拐点 。经过稀疏处理后,FFN 在 NPU 上是 Compute Bound 还是 Memory Bound?
- (c). 当批次 时,CPU 的嵌入查询阶段占端到端时间的 20% 且不可缩减()。Self-Attention 和 FNN 虽可并行化,但需通过 PCIe 传输激活值(假设每次迭代 (批次) 总传输量为 MB)。已知 PCIe 带宽为 GB/s,试论证数据移动与 CPU 的串行部分哪个对整体加速构成更根本的限制。在何种条件(批量大小、压缩率或流水线并行)下,主导限制因素会发生转变?
对于这样一个复杂的问题,我们需要将其拆解为不同处理器的小部分进行分析。
(a). 在 GPU 上的自注意力模块,其 GPU 的拐点 FLOPs/Byte.
- 对于标准的 Attention:其计算量为 FLOPs GFLOPs。在 FP16 中,它有 ,,数据量 MB。其计算强度为 FLOPs/Byte。因为 ,所以标准的 Attention 在 Memory Bound 的区域(斜坡)。其实际性能是 TFLOPS,其利用率为 。
- 对于 Flash Attention:其计算量与标准的 Attention 一致,唯一的改变是数据量中没有 矩阵。 MB。其计算强度为 FLOPs/Byte。因为 ,所以 Flash Attention 在 Compute Bound 的区域(屋顶 Roof)。其实际性能是 TFLOPS,利用率为 。 对比可知,Flash Attention 的利用率远高于标准的 Attention,应该选择 Flash Attention 分配给 GPU。
(b). 在 NPU 上的 FFN 计算,其 NPU 的拐点 OPs/Byte。
在批次大小 ,序列长度 的条件下, OPs/Byte。因为 ,所以 FFN 的计算是 Compute Bound 的。应用2:4 稀疏化技术后,其峰值性能提升: TOPS,此时拐点变为: OPs/Byte。此时 ,FFN 的计算在 NPU 上还是 Compute Bound。其实际性能 TOPS.
(c). 在 时,CPU 串行调度所占的时间为端对端总延迟的 20%,那么并行时间则占端对端总延迟的 80%。对于一个方向上的数据转移:。
根据阿姆达尔定律,如果 GPU/NPU 上的 Attention 和 FFN 被无限加速,理论最大 speedup 是:。这说明在 下,CPU 的串行调度开销是硬上限。20% CPU 串行调度开销把最大 speedup 限制在 5×,此时 PCIe activation transfer 只是较小贡献,其 根本限制是阿姆达尔定律。
当我们加大批次大小到 ,此时因为次线性化的变化,CPU 串行调度的时间大约为 。而一个方向上的数据转移时间 。因为 WS 数据流的策略,在 NPU 上的延时不会线性增长 64 倍。
因为 ,此时主要瓶颈变成了 数据移动墙 (Data movement wall)。
总的来说:在小的 Batch size 下 阿姆达尔定律的串行比例分数 (Amdahl serial fraction) 是硬上限;在 Batch size 很大时,PCIe 数据移动墙 (data-movement wall) 会成为主瓶颈。
- 小 batch 时:传输数据很少,所以 PCIe transfer time 不大。真正卡住系统的是 CPU serial 部分。所以主要瓶颈在于 Amdahl 串行调度比例。
- 大 batch 时:Activation transfer 容量近似线性增长,主要瓶颈在于 Data movement。
这种瓶颈转移一般发生在 ,因为 PCIe 的带宽太低。
除了批处理大小外,还有以下几种情况会导致瓶颈转移:
- 输入激活压缩:如果把 压缩,那么每次跨 PCIe 搬的数据更少,transfer time 下降,所以 data-movement bottleneck 会晚一点出现。,压缩后 。如果输入激活的压缩,让同样的 PCIe 带宽能搬更多“有效数据”,就等价于提高了 effective bandwidth ,那么在 Roofline 图上,PCIe 这条 memory-bound 斜线变得更陡。
- 流水线并行:在 NPU 和 GPU 计算中,不要等传输完数据才开始算,也不要等算完这一层才开始搬下一层的数据,而是让“搬数据”和“计算”同时进行。当 GPU/NPU 正在计算第 层时,系统提前把第 层需要的数据搬过来。在这种情况下,流水线将搬数据和计算重叠在一起,例如:
原本,,现在变成 。也就是说,搬数据和计算谁更慢,就主要等谁,而不是两个时间简单相加。但是即使流水线把 PCIe transfer 藏起来,CPU 并行开销仍然存在。此时 阿姆达尔定律的串行比例分数 (Amdahl serial fraction) 重新成为主要瓶颈。Time: 0 4 6 8 10Layer 1: Transfer | ComputeLayer 2: Transfer | ComputeLayer 3: Transfer | Compute