

前言
本章是分布式系统的学习笔记,从分布式系统的基本定义出发,解决时间与事件顺序的表达问题,重点讨论快照、故障模型、复制与共识等系统基础机制。
Introduction to Distributed Systems
分布式系统 (Distributed Systems) 是由多个位于网络中的硬件或软件组件组成,它们 只能通过消息传递(message passing) 进行通信和协作。简单来说就是多台通过网络通信的计算机,共同协作完成任务。
正是因为分布式系统 “只能发消息” 的特点,一旦系统分布到多台机器上,立刻就会出现三大核心问题:
- 通信可能失败:消息可能延迟、丢失,甚至不知道它失败了。
- 进程/机器可能崩溃:节点可能挂掉,而且其他节点未必立刻知道。
- 系统行为是非确定性的 (non-deterministic):网络时延、调度顺序、失败时机都会变化。
所以引出了我们设计分布式系统的三个目标:
- 性能 / 可扩展性 (Performance / Scalability):系统在节点数增加时,能否继续有效提升总处理能力。
- 容错 / 可用性 (Fault Tolerance / Availability):即使部分组件失败,系统整体仍尽可能继续提供服务。
- 一致性 (Consistency):当数据存在多个副本时,系统对外表现出的数据是否一致。
为了实现上述目标,研究人员开发了多种分布式计算框架。MapReduce 作为其中的经典代表,通过简化编程模型,成功解决了大规模数据集下的可扩展性与容错性问题。
试想一个业务中的常见场景:当系统需要处理规模非常大的数据,例如:TB / PB 级日志、网页抓取数据、搜索索引构建和用户行为分析等时,单台机器往往面临存储不下、计算太慢、一旦机器坏掉任务就中断等问题。在学习了之前提到的分布式系统的概念后很容易想到,分布式是大数据处理场景下的解决方案。
然而,我们也知道分布式系统存在的一大堆问题,MapReduce 通过把“复杂的分布式执行问题”抽象掉,让普通程序员也能写出大规模并行数据处理程序,而不需要自己实现复杂的分布式底层。
MapReduce 主要解决的是:单机无法处理的海量数据计算问题。它通过 “分而治之” 的思想,利用多台机器并行工作来提高效率。
MapReduce 的核心流程分为三个阶段:Map(映射)、Shuffle(混洗)、Reduce(归约)。
- Map 阶段:分而治之,提取特征。
系统会将庞大的输入文件切分成一个个小的数据块(Splits),分配给多台机器上的 Map 任务同时进行处理。每一个 Map 任务将读取数据块的文本,将每一行文本拆分成一个个单词,并为每个单词打上 “出现 1 次” 的标签。
如后续例子流程图,假设其中一个 Map 任务分配到的文本是
"Hello World Bye World"。Map 函数会逐词扫描,遇到 “Hello”,输出一个键值对:<"Hello", 1>,遇到 “World”,输出:<"World", 1>,遇到 “Bye”,输出:<"Bye", 1>,再次遇到 “World”,再次输出:<"World", 1>(注意这里不是 2, 而是固定的 1)。 - Shuffle & Sort 阶段:承上启下,物以类聚。
这是 MapReduce 最关键的一步,发生在 Map 和 Reduce 之间。它的核心目的是 “把相同的键(Key)聚集到一起”。Shuffle 将所有 Map 任务产生的杂乱无章的
<Key, Value>键值对进行收集、按 Key 排序、并进行分组,将其转换为<Key, List>的形式。 例如,file 1 产生了<"Hello", 1>,file 2 也产生了<"Hello", 1>,那么 Shuffle 阶段将它们组合在一起,形成列表的形式传递给下一个阶段,即<"Hello", [1, 1]> - Reduce 阶段:汇总聚合,得出结论。
经过 Shuffle 阶段的整理,Reduce 阶段将对每一个 Key 对应的 Value 列表执行汇总计算,并将最终结果保存下来。
在我们的例子中,一个 Reduce 任务接收到了 Shuffle 阶段传来的数据:
<"Hello", [1, 1]>。Reduce 函数开始工作,把列表里的数字加起来:1 + 1 = 2。它输出最终结果:<"Hello", 2>。所有的 Reduce 任务执行完毕后,每个单词的总出现次数就被计算出来了,并被统一写入到最终的输出文件中。
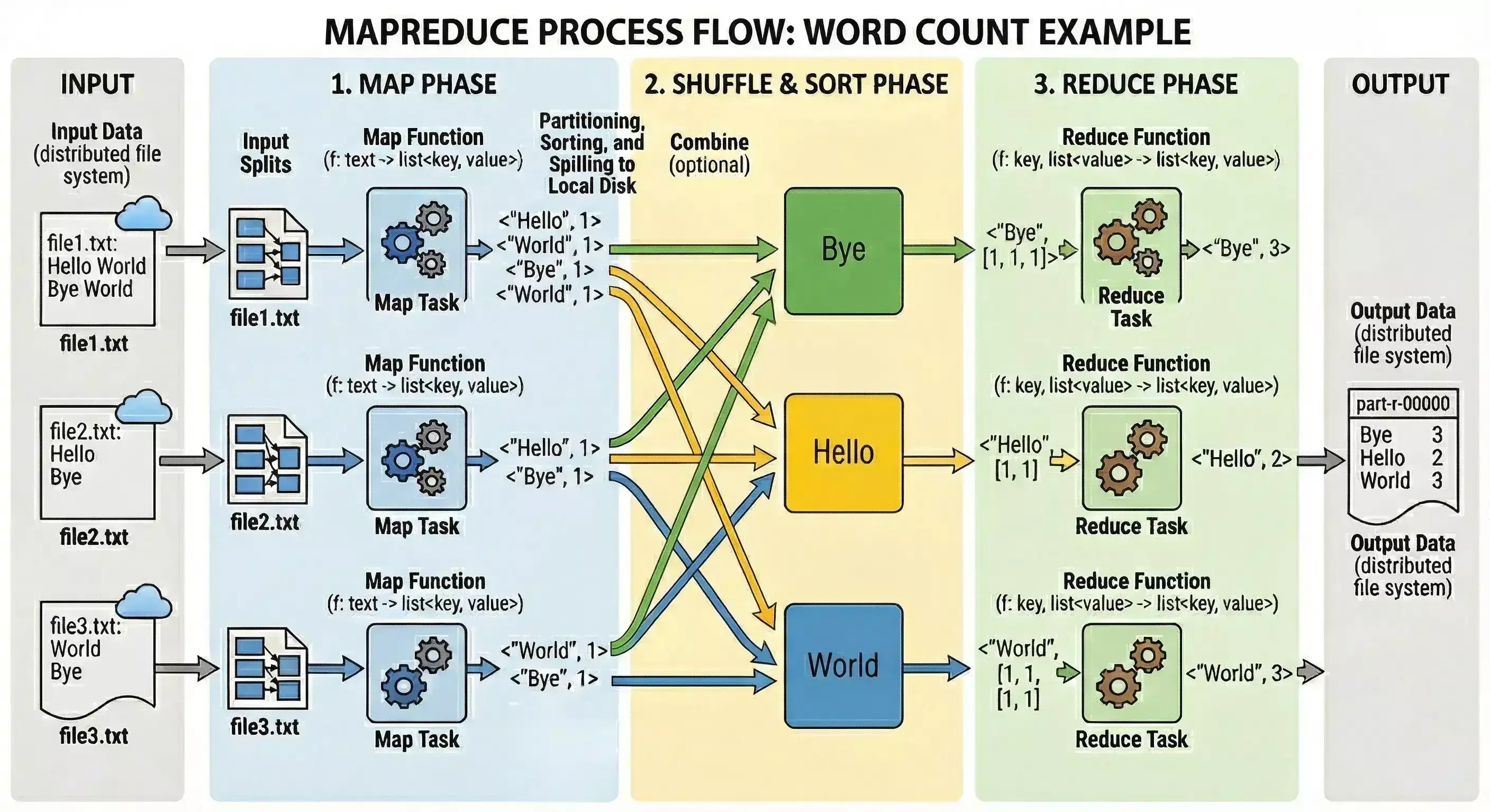
总结一下这三个过程:MapReduce 先由 Map 阶段对输入数据逐项处理,生成中间键值对 (intermediate key-value pairs);再由 Shuffle 阶段按 key 分组,把相同 key 的值聚合起来;最后由 Reduce 阶段对每个 key 对应的值列表进行汇总,生成输出。
这样的流程有没有什么弊端呢?例如一个 Mapper(映射器)处理了一大段文本,发现了“Apple”这个词 1000 次。如果没有 Combiner,Mapper 会输出 1000 个独立的键值对:(Apple, 1), (Apple, 1), ..., (Apple, 1)。这 1000 个数据对都必须通过网络发送给 Reducer。在分布式系统中,网络传输是最慢的一环,这会导致严重的网络拥堵。
为了节省网络带宽,提高运行速度,一个 合并器 (Combiner) 将会应用于 Map 阶段的后期。它会把那 1000 个 (Apple, 1) 提前在本地加起来,变成一个键值对:(Apple, 1000)。现在,只有这一个键值对需要通过网络传给 Reducer。
所以说提出合并功能的作用就是:在 Shuffle 之前对 Map 的输出做本地聚合,从而减少网络传输并提高效率。
MapReduce 里有很多复杂的操作(比如把数据分块、在网络间移动数据、确保每台机器都在干活)。对于程序员而言,只需要写好 Map 函数和 Reduce 函数,剩下的繁杂工作全部由 MapReduce Framework 来自动完成,大大减少了工作量和出错率。
框架负责的核心工作包括:
- Task Scheduling(任务调度):决定哪台机器执行哪个 Map 任务,哪台机器执行哪个 Reduce 任务。
- Data Partitioning(数据分区):在 Shuffle 阶段,决定哪些 Key 该去哪个 Reducer。
- Data Communication(数据传输):负责通过网络,高效地把 Map 的中间结果传输给 Reducer。
- Dealing with Failures(故障处理):自动处理机器故障、重试任务。
在分布式系统里,有成百上千台机器,某一台机器突然坏掉(故障)是非常正常的。
- 如果坏掉的是一个 Map 任务:因为它的中间结果存在本地磁盘,机器坏了数据也没了,Master 会让另一台健康的机器重新执行这个 Map 任务,原节点的数据不管怎么样全部重跑。
- 如果坏掉的是一个 Reduce 任务:它的最终结果还没写完,Master 会让另一台机器重新跑这个 Reduce 任务。
Physical Clock
分布式系统中,时间非常重要。分布式系统中时间主要用于:
- 触发动作:比如 timeout、retry、failure detector
- 记录现实:比如日志、数据库时间戳、性能分析
- 比较先后:多个节点上的事件谁先谁后
我们将时钟 (clock) 分为两种类型:
- 物理时钟 (physical clock):用于计算真实世界中经过的秒数。
- 逻辑时钟 (logical clock):用于计算发生的事件数,表达事件顺序。
在计算机中,常用如下的方式表示物理时钟:
- UTC:协调世界时,基于原子钟。
- Unix time:自 1970-01-01 00:00:00 UTC 以来的秒数。
- ISO 8601:与 UTC 之间的偏移量表示,如
2020-11-09T09:50:17+00:00。
在分布式系统中,物理时钟由于存在硬件差异和时钟漂移 (Drift),难以保证多台机器间的绝对同步。在时钟漂移导致误差逐渐累积后,在同一个时刻时,不同时钟之间会存在时钟偏差 (Clock Skew)。
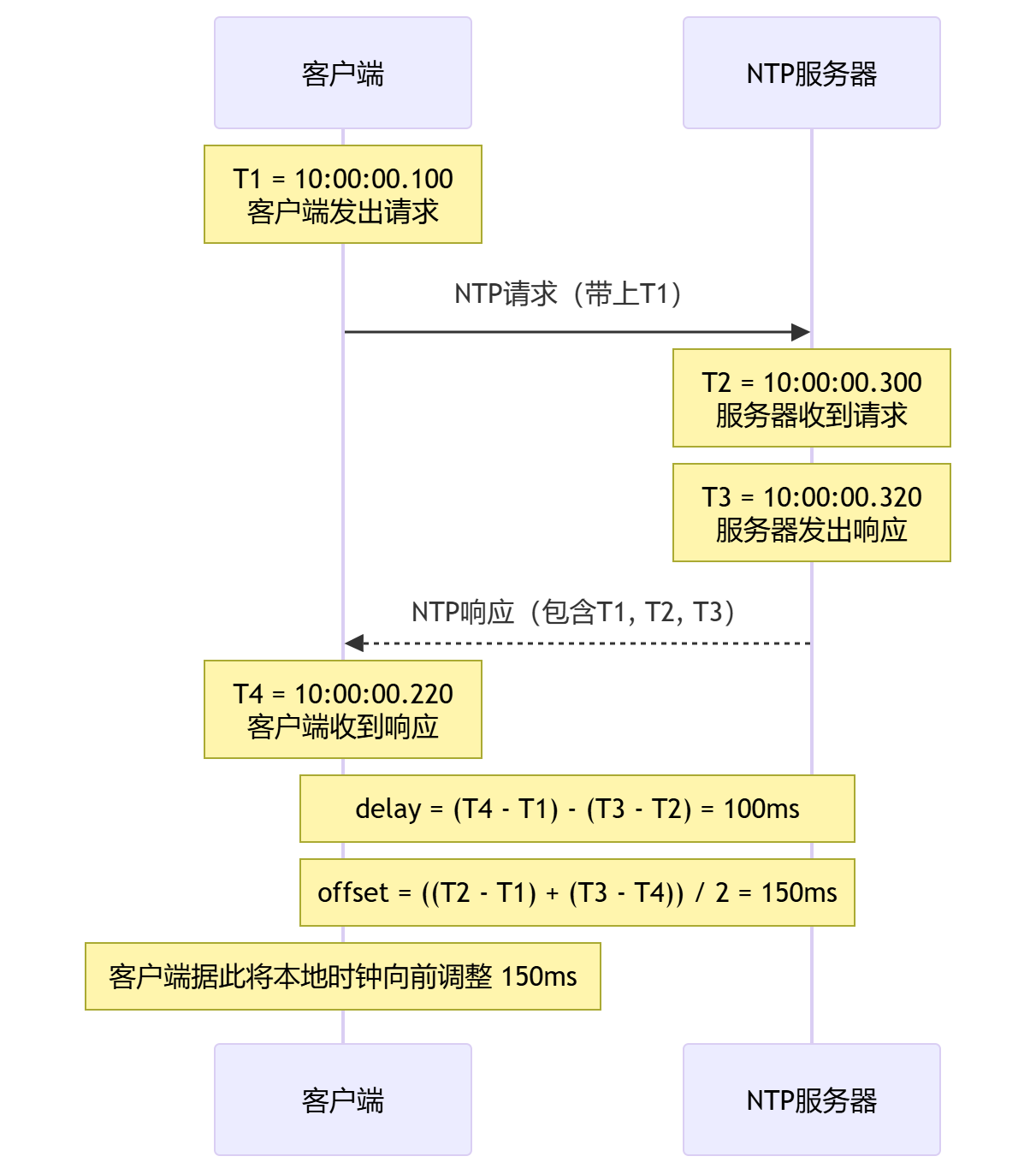
为了应对物理时钟带来的偏差,系统通常会使用网络时间协议(NTP)进行定期同步。接下来通过一个简单的例子来解析这个过程。如下图,
- 自己的客户端发送 NTP 请求到 NTP 服务器,发送时的时间为:
T1 = 10:00:00.100。 - 时间服务器收到这个请求时,它自己的准确时间是:
T2 = 10:00:00.300。 - 时间服务器处理好请求后,发送回客户端,此时时间为时间服务器时间
T3 = 10:00:00.320。 - 客户端电脑收到响应,客户端此时的本地时间为:
T4 = 10:00:00.220。
NTP 会根据这 4 个时间计算两个关键量:
这意味着:
- 整个来回网络 + 处理一共花了 ms
- 其中服务器自己处理花了 ms
- 所以纯网络来回大约是 ms
为了弥补这些延迟,我们还需要计算时钟偏移 offset:
offset 在不同的范围内将执行不同的操作,参考如下:
| 条件 | 操作 |
|---|---|
| |θ| < 125 ms | Slew:微调时钟速度(±500 ppm),约 5 分钟内同步 |
| 125 ms ≤ |θ| < 1000 s | Step:突然重置时钟 |
| |θ| ≥ 1000 s | Panic:不做任何操作,留给人工处理 |
Logic Clock
只有物理时钟在分布式系统中是远远不够的,在分布式系统中,真实时间顺序不一定等于因果顺序。
例如,A 先发消息 m1,B 收到后回复 m2,这个消息之前存在因果关系 m1 -> m2。但由于不同机器时钟误差、网络延迟、同步不完美,可能出现:timestamp(m2) < timestamp(m1)
所以我们需要 逻辑时钟 去解决这样的因果顺序问题。
Leslie Lamport 提出了一个非常聪明且简洁的解决方案:既然物理时间不可靠,我们就用“事件的 因果关系” 和 “计数器” 来为人为定义一个 “逻辑时间”。
Lamport Clock Algorithm 遵循如下规则:
- 每个节点(进程)都会维护一个自己的本地计数器,记为 ,初始状态下,所有节点 .
- 节点在执行任何事件(如计算、发送消息、接收消息)之前,必须将自己的计数器加一。.
- 当节点发送消息时,它必须将自己当前的计数器值 附带在消息里一起发出去。
- 当节点收到消息时,它必须对比自己的计数器 和消息带过来的 ,取两者的最大值,然后再加一。.
通过这样的规则,可以保证存在因果消息传递的 ,一定有 。但是反之不一定成立,即 。
接下来通过一个例子来演示,如下图,其中黑点表示在某个进程下发生了一个本地事件,不同进程间通过箭头传递信息,信息中携带了自己的时间戳和信息内容 。
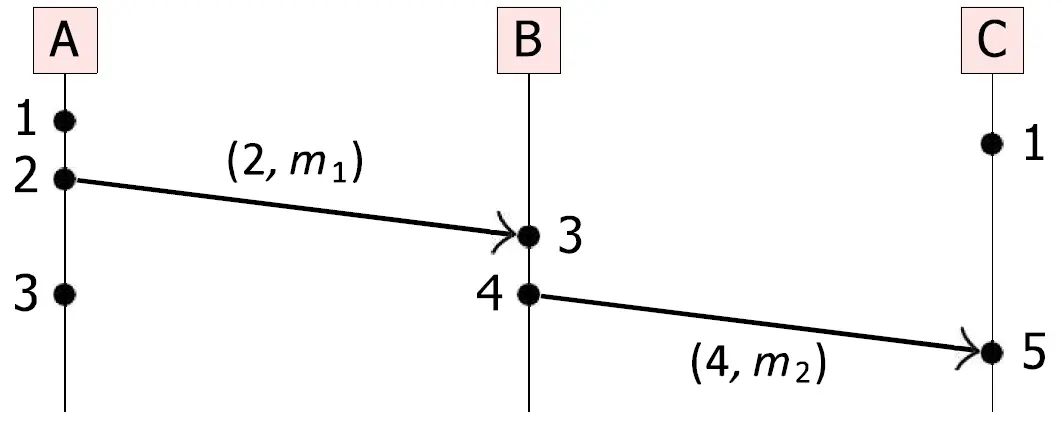
- 进程 A 的时间线分析
- 黑点 1: 进程 A 发生了一个本地事件。根据规则,它的本地时钟从 0 加 1,所以该事件的时间戳是 1。
- 黑点 2(发送消息): 进程 A 准备向 B 发送消息 。这也是一个事件,所以时钟继续加 1,变成 2。此时,A 把带有自己时间戳 的消息发出去,记作 。
- 黑点 3: 进程 A 之后又发生了一个本地事件。时钟继续加 1,变成 3,此时 。
- 进程 B 的时间线分析
- 黑点 3(接收消息): 进程 B 收到了来自 A 的消息 。此时 B 在这之前没有发生过任何事件,所以它自己的本地时钟是初始值 。接收到的消息里,带过来的时间戳是 2。根据接收规则:。
- 黑点 4(发送消息): 进程 B 紧接着处理完逻辑,向进程 C 发送消息 。作为一个新事件,本地时钟加 1,从 3 变成了 4。发出的消息同样附带当前的时间戳,记作 。
- 进程 C 的时间线分析
- 黑点 1:进程 C 内部自己先发生了一个本地事件,.
- 黑点 5(接收消息): 进程 C 收到了来自 B 的消息 。.
根据 Lamport Clock Algorithm,可以清晰识别出因果链条,但是有了 后,我们不能反向识别出 或 (并行),例如图中进程 A 的黑点 3 和进程 B 的黑点 4 是并行的,但是 。
为了彻底解决“如何精准判断因果关系与并发”的问题,向量时钟 (Vector Clocks) 诞生了。
假设系统里有 个进程,那么每个进程不再只维护一个单调递增的数字,而是维护一个长度为 的数组(也就是向量)。所以在 Lamport Clock Algorithm 的基础上,规则将修改为:
- 每个进程都会维护一个长度为 的向量数组 ,初始状态下为 。
- 进程在执行任何事件(计算、发送、接收)前,只把向量中 代表自己的那个数字加一。
- 进程发送消息时,把自己的整个向量附带在消息里。
- 接收方不仅要(根据规则1)把自己的数字加一,还要把本地的向量和消息里带过来的向量进行 逐项对比,每一项都取最大值。
接下来继续通过一个例子来演示这个过程:
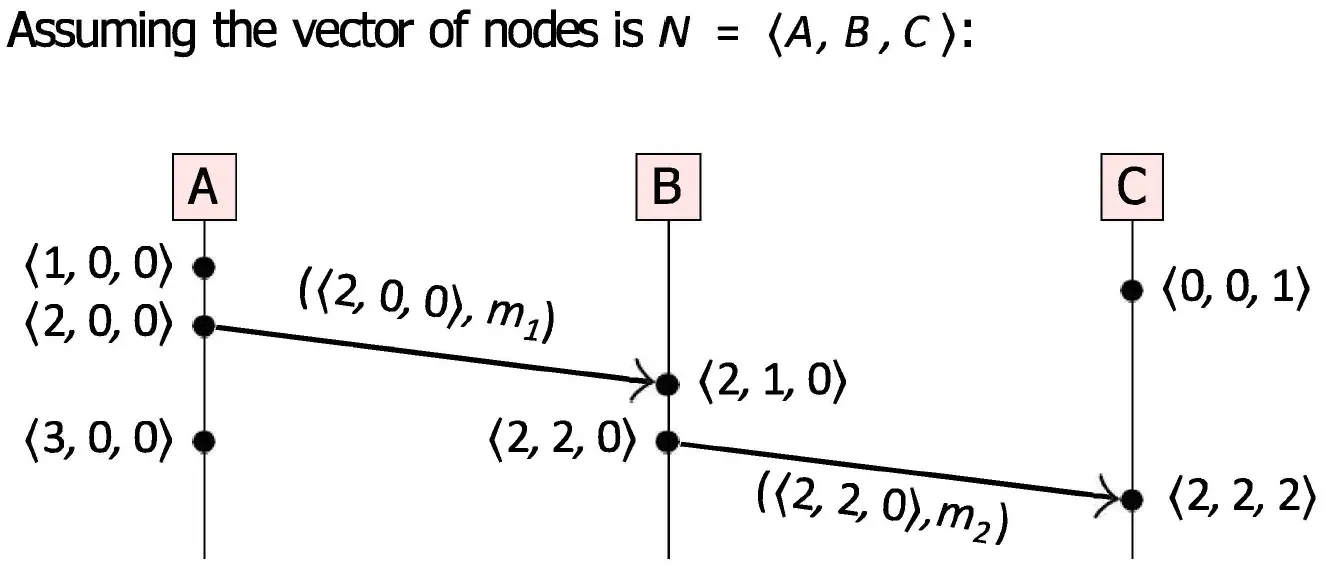
现在有三个节点 A, B, C,三个数字分别代表 A, B, C 节点的事件数。初始状态下,大家的向量都是 。
- 对于进程 A:A 只负责更新向量的 第一个位置
- 第一个黑点(本地事件): A 发生本地事件,将自己的计数器加一。向量更新为 。
- 第二个黑点(发送消息): A 准备发送消息 。这是 A 的第二个事件,所以自己的计数器再加一,向量变为 。随后,A 将带有这个向量时间戳的消息 发送给 B。
- 第三个黑点(本地事件): A 又发生了一个本地事件,计数器继续加一,向量变为 。
- 对于进程 B:B 负责更新向量的 第二个位置
- 接收消息 : B 收到了 A 的消息。先把 B 自己的计数器加一,本地向量从初始的 变成 。然后 B 将本地向量 与消息附带的向量 进行 逐位对比,取最大值:, , 。该接收事件的向量时间戳定格为 。这意味着:B 现在知道 A 发生了 2 个事件,B 自己发生了 1 个事件,C 发生了 0 个事件。
- 发送消息 :B 准备向 C 发送消息。作为新事件,B 把自己的计数器加一,向量变为 。它将此向量附在消息 中发出。
- 对于进程 C:C 负责更新向量的 第三个位置
- 第一个黑点(本地事件): 在收到任何消息前,C 发生了一个本地事件。它把自己的计数器加一,向量变为 。
- 接收消息 : C 收到了 B 的消息。先把自己的计数器加一,本地向量从 变成 。然后,C 将本地向量 与消息带来的向量 逐位取最大值:, , 。最终,该接收事件的向量定格为 。这说明 C 此时已经“吸收”了 A 的前 2 个事件和 B 的前 2 个事件的历史。
对比 Lamport 算法,使用向量时钟后,我们可以拿出任意两个点,通过对比它们的向量,就能绝对确信它们的关系。例如,对比 A 的发送事件 和 C 的接收事件 。因为 ,,,且 至少一项是严格小于的,所以我们可以知道 A 的发送事件绝对先于 C 的接收事件发生。
而对比 A 的第一个事件 和 C 的第一个事件 。它们无法满足“一方的每一位都小于等于另一方”。由此,这两个事件是并发的,互不影响。
无论是 Lamport Clock Algorithm 还是 Vector Clock Algorithm,它们都专注于一个节点向另一个节点之间发送信息的组合。在实际业务中,有很多情况会遇到一个节点同时向一组节点发消息的情况,我们该如何确保消息的顺序呢?
为了解决这个问题,分布式系统引入了 广播协议(Broadcast Protocols)。通常来说,广播算法从网络层 收到 (receive) 消息后,可能先放入缓冲区,之后才 交付(deliver) 给上层应用。很多顺序保证,其实约束的是 deliver 顺序,不是 network receive 顺序。
在确保了消息能送达(可靠)的前提下,系统对“顺序”的要求由弱到强,分为以下三种经典模型:
- FIFO 广播 (First-In-First-Out Broadcast) 针对 同一个发送者。如果节点 A 先发了消息 ,后发了消息 。那么系统中的所有节点,都必须先交付 ,再交付 。不同发送者之间不作约束。如果 A 发了 ,B 发了 ,有的节点可能先收到 ,有的节点可能先收到 。
- 因果广播 (Causal Broadcast) 针对 有因果关系 的消息,如果消息 的发送 “先行发生” 于消息 的发送(即 ),那么所有节点必须先交付 ,再交付 。就像是有人提问后才有回答一样,它的底层通常就是依赖 向量时钟 (Vector Clocks) 来拦截和排序那些乱序到达的消息。
- 全序广播 (Total Order Broadcast / Atomic Broadcast) 它要求系统中的 所有节点,必须以完全相同的顺序交付所有的消息。不管这些消息是谁发的,不管它们有没有因果关系。
知道了我们想要的顺序,接下来看看底层是如何把消息通过广播算法分发出去的。
- 激进可靠广播 (Eager Reliable Broadcast) 当一个节点 第一次 收到某条新消息时。它立刻把这条消息转发给组内的 所有其他节点。然后它才在本地交付(处理)这条消息。如果它 再次收到这条相同 的消息(别人转给它的),它就直接丢弃。容错率极高,但是每条消息在网络中会被重复发送 次,容易产生网络风暴。
- Gossip 协议 (流言协议 / 传染病算法) 为了解决 Eager 广播极差的扩展性,Gossip 协议模仿了人类社会传八卦或者病毒传播的方式。系统中没有中心节点。每隔一个固定的时间(比如 1s),每个节点会 随机 挑选 个其他节点( 通常很小,比如 2 或 3)。把自己目前知道的最新消息“同步”给这几个被选中的节点。收到消息的节点,在下一个周期也会继续随机找另外 个人同步。它平均了网络负载,但是你无法准确预测一个消息到底需要多久才能到达所有节点。
总结一下逻辑时钟中的重要概念:
根据 Lamport Clock algorithm,Lamport Clock (LC) value 会被如下两个规则改变:
- 本地事件规则:发生任何事件前先加 1.
- 消息传递规则:收到消息时,取最大值再加 1.
在 Vector Clock 中,Vector Clock (VC) value 则变成了向量版本:
- 本地事件规则:只给向量中自己的那一位加 1.
- 消息传递规则:接收方不仅要把自己的数字加 1, 还要对每一位都要取最大值。
对于值的比较,在 Lamport Clock algorithm 下,如果 ,我们 不能确定因果关系,可能 ,也可能 。Lamport Clock 只能保证:
而在 Vector Clock 中,如果 ,那我们就 可以确定因果关系 。如果无法比较 和 ,那么可以确定是并行关系 。
Snapshot
分布式系统里有很多机器,它们彼此发消息,而且每台机器都在不停变化。如果你想知道,例如:
- 整个系统的状态是什么样的,不通过读日记来获取。
- 出故障后能不能从一个一致的状态恢复?
- 有没有死锁?
- 检查进程的垃圾回收机制…
对于单独的主机来说,直接暂停程序、拷贝内存就行了。但是对于分布式系统而言,时钟会有偏差(clock skew),且节点一直在运行、网络中随时有消息在飞,我们无法记下正在 信道中传输的消息。所以想要给整个系统记录某个时刻或状态的 全局快照 (Global Snapshots) 非常困难。
在分布式系统中,我们定义一个 全局快照 (Global Snapshots) 记录如下的信息:
- 节点状态 (Node State):每个机器在快照那一瞬间的本地数据(比如变量值)。
- 通道状态 (Channel State): 在快照那一瞬间,正飞行在网络线路中、还未到达目的地的消息。也就是那些“已经发送但还没被接收”的消息。
Chandy-Lamport 算法 是一种分布式系统中记录全局快照的方法,它允许系统在不停机、不阻塞任何正常业务的情况下,拍下一张逻辑上绝对 一致 的全局快照。
算法引入了一种特殊的控制消息,叫做 Marker(标记)。Marker 的作用是把时间线一分为二:Marker 之前的消息属于“过去”,Marker 之后的消息属于“未来”。
假设系统里有系统里有 N 个进程互相连接,没有故障,任何人都可以随时发起快照,每对进程之间有两个 FIFO 单向信道。系统遵循以下三个极其精妙的规则:
- 发起者 (Initiator) 的动作:当节点 A 决定发起快照时,它需要做三件事:
- 记录本地状态:A 立刻记录自己当前的本地状态,并且准备一个 Marker 信息。
- 发送 Marker:A 沿着自己所有的输出通道(Outgoing Channels),向外发送 Marker 消息。
- 开始记录:A 开始记录从所有输入通道(Incoming Channels)接收到的正常消息。 可以理解为:发起者先把 “自己的照片” 拍下来,然后给大家发一个 “开始拍快照” 的边界信号。
- 节点 “第一次” 收到 Marker 的动作:例如,当节点 B 从通道 收到了 Marker,且这是 B 第一次参与本次快照时,它必须立刻响应:
- 记录本地状态:B 立刻记录自己当前的本地状态。
- 标记通道为空:B 把收到 Marker 的那条信道 的通道状态记为 空(因为 Marker 前面的所有消息,如果存在,都应该已经先到达了)。
- 发送 Marker:B 沿着自己所有的输出通道,向外发送 Marker。
- 开始记录:B 开始记录从 其他所有 输入通道收到的正常消息(不包括通道 C)。
- 节点“再次”收到 Marker 的动作:当节点 B 已经记录过本地状态后,如果又从另一个通道 收到了 Marker:
- 关闭记录:B 停止记录从通道 接收的消息。
- 生成通道状态:将从开始记录到现在之间在 上收到的所有消息,作为通道 的状态(即快照发生时,在通道 中的消息)。 当一个进程在所有输入信道上都收到 Marker 后,它对本次快照的记录完成。当 发起者记录结束后,整个 Chandy-Lamport 算法将结束,这个过程中系统照常运行,业务消息照常发送。
Chandy-Lamport 算法利用 Marker 把状态完美地“封存”了起来。如果在 Marker 到达之前有消息发送了,它要么已经被接收(记入了接收方的节点状态),要么就被接收方的记录了下来(记入了通道状态)。
接下来通过一个例子来演示算法的过程,对于如下的两个进程 A, B,存在两个 FIFO 通道 和 。
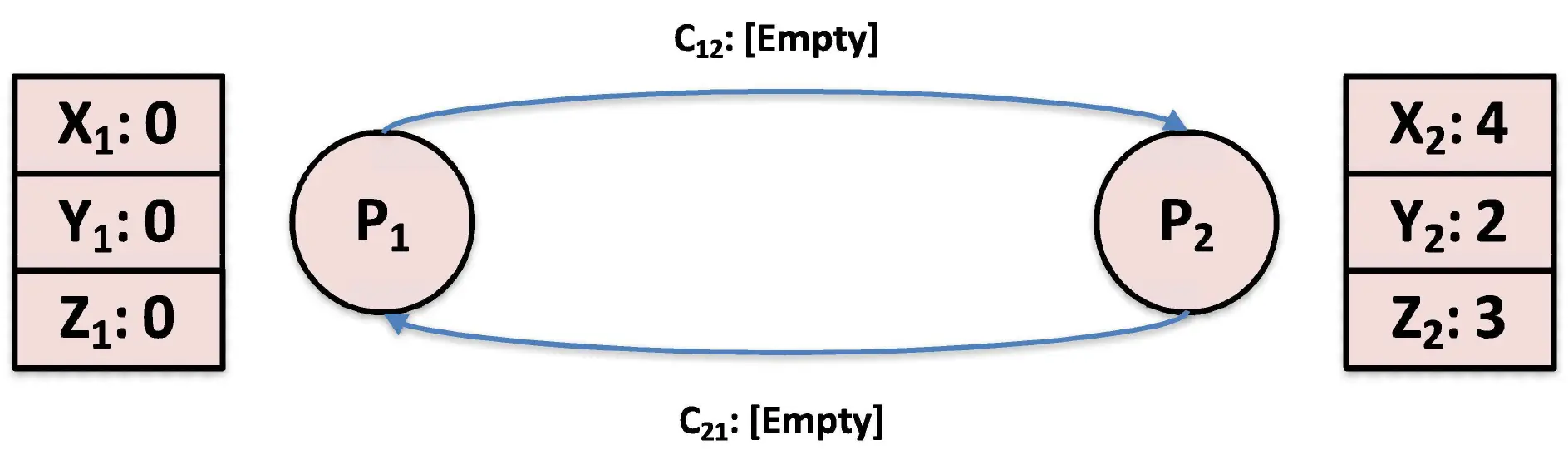
- 首先, 发起快照。那么根据算法规则,
- 记录本地状态: 立刻开始记录自己的状态。此时 的快照状态被固定为:。
- 发送 Marker: 沿着输出通道 向 发送一个 Marker 消息。
- 开启记录: 立刻打开针对输入通道 的记录,准备记录接下来从 飞过来的所有正常消息。
- 并发的发生与 的反应:在 的 Marker 还在通道 上往 飞的时候, 恰好向 发送了一个正常消息 。随后, 才收到了 发来的 Marker。
此时是 第一次收到 Marker,所以对于 :
- 记录本地状态: 立刻放下手头工作,记录自己的状态。此时 的快照状态被固定为:。
- 记录通道状态:因为 是从 收到 Marker 的,它认定 这个通道在快照期间是空的。所以设置 的快照状态为
[Empty]。 - 发送 Marker: 沿着输出通道 ,向 发回一个 Marker 消息。此前 发出的 会排在 发出的 Marker 前面。
- 开启记录: 开始针对输入通道 的记录。
- 收到 Marker 并捕获通道状态:
- 收到消息:首先, 会收到排在前面的普通消息 ,并将其记录了下来。接着, 收到了 发来的 Marker。
- 关闭记录:因为 早就记录过自己的状态了(它是发起者),所以再次收到 Marker 时, 关闭 的记录。
- 生成通道状态: 检查该通道记录下的所有消息,并且将其设置为通道状态。因此,通道 的快照状态就是
[M1]。
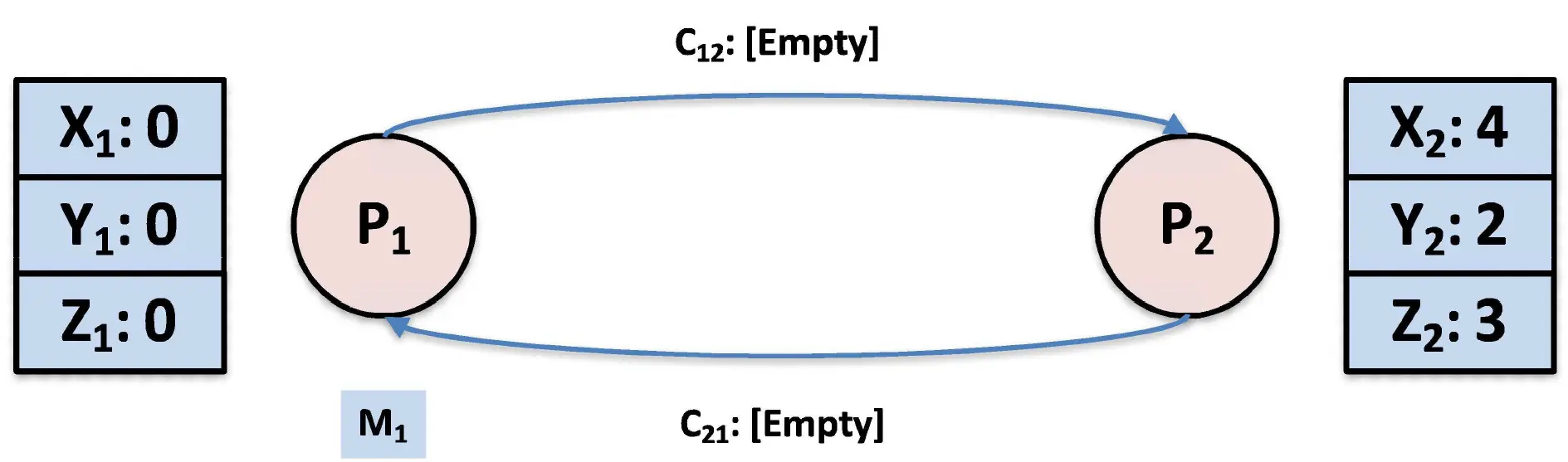
经过上述过程,整个分布式系统的全局快照(蓝色部分)就拼凑出来了:
- 进程 的状态:
- 进程 的状态:
- 通道 的状态():
[Empty] - 通道 的状态():
[M1]
需要注意的是:
- 分布式系统的全局状态不仅包括进程本地状态,还包括通信信道中的状态。不记录 channel state,就无法得到完整且因果自洽的 global state。
- 快照实际上是一组 满足因果一致性的切面,即 一致全局状态 (consistent global state),不是所有机器真的在同一物理时刻停下来的记录。
- 通道状态不是“这条信道历史上所有消息”,通道状态只包含在本次快照边界下,被判定为“仍在路上”的消息。不是全部历史消息。
- Marker 的本质不是通知,而是“划边界”。对于每个进程,第一次看到 Marker 的时刻,就是它的本地拍照时刻。对于每个通道而言,从“开始记录该信道”到“收到这条信道上的 Marker”为止,这段时间到达的消息,就是该信道在快照中的内容。所以 marker 真正做的是:为每个进程确定本地快照点,为每条信道确定哪些消息属于‘仍在路上’。
怎么理解这个算法满足的 因果一致性 (Causal consistency) 呢?
首先定义两个状态:
- presnapshot:某个事件发生在该进程的本地快照之前(拍进照片里)
- postsnapshot:某个事件发生在该进程的本地快照之后(没被拍进去、发生在拍照之后)
若事件 A 因果先于事件 B,且 B 已被包含在快照中,则 A 也必须被包含在快照中;否则会出现“有果无因”的不一致全局状态。
例如:一个简单的因果链:进程 A 发送消息,进程 B 接收消息。。
- 如果 发送发生在发送者 A 的本地快照之前:那么
send(m)是 presnapshot,如果接收也在接收者 B 的快照之前,那就没问题。 - 如果 发送在发送者 A 快照前,但接收在接收者 B 快照后:那这条消息不会丢失,它会被记录到 通道状态 里。
- 如果接收已经被拍进来了,但发送没拍进去:那就意味着“结果进了照片,原因没进”。在接收方 B 看来,
receive(m)发生在它记录本地状态之前,所以它已经是 presnapshot 了。但在发送方 A 看来,send(m)发生在它记录本地状态之后,所以它是 postsnapshot 的。 按照算法,A 一旦记录状态,就要立刻在所有输出通道上发 Marker。所以在 这条信道上,发送顺序一定是:Marker、m。因为信道 FIFO,同一条信道上先发的 Marker 必须先到。所以 B 一定会先收到 Marker,再收到消息 m。 当 B 收到 Marker 时就要记录自己的本地状态。所以 B 的快照时刻一定发生在它看到 m 之前。因此receive(m)不可能被拍进去。
所以对于事件 A 发生在事件 B 之前,但系统只记录了事件 B,那么不能说明系统满足因果一致性。
一致快照要求:如果 A → B 且 B 被记录,则 A 也必须被记录。只记录 B 而不记录 A 违反了因果一致性。Chandy-Lamport 算法通过 marker 机制保证:任何被记录事件的所有因果前驱都会被记录。
Faults Model
在单机系统中,程序要么运行,要么崩溃。但在分布式系统中,最可怕的不是机器坏了,而是 你不知道它是坏了、慢了,还是网络断了。
有一个经典的思维实验 —— 两军问题 (Two Generals Problem) 证明了 在不可靠的链路上,绝对的共识是不可能达成的。
两支友军(将军 A 和将军 B)分别驻扎在两个山头,准备夹击山谷里的敌军。他们必须同时发起进攻才能获胜。但他们唯一的沟通方式是派通讯兵穿过敌军所在的山谷,通讯兵随时可能被抓(消息丢失)。
假设两军之间存在如下的通信过程:
- A 派人送信:“明早 8 点进攻。”
- B 收到了信,为了让 A 放心,B 派人回信(ACK):“收到,明早 8 点见。”
那么问题来了,B 怎么知道自己的回信 A 收到了没?如果回信的兵被抓了,A 没收到,A 就不敢出兵,B 一个人去就会全军覆没。为了解决这个问题,A 收到回信后,必须再给 B 发一个确认信(ACK of ACK):“我收到了你的确认”。但此时同理的,A 同样会担心自己的“确认信”有没有送达。于是陷入死循环了。
无论发送多少次确认,两位将军永远无法达到 100% 的信心。推广到我们的分布式系统中,不可靠网络下,某些“必须双方完全协调一致”的目标,本质上无法通过有限次确认达到绝对保证。
如果说“两军问题”是网络不可靠,那么 Leslie Lamport 提出的 拜占庭将军问题 (Byzantine Generals Problem) 则更进一步:如果网络是可靠的,但节点本身是坏的、甚至会恶意撒谎呢?
拜占庭帝国的几支军队包围了一座城市。将军们必须投票决定是“进攻”还是“撤退”。只要大家行动一致就能赢。但麻烦的是,将军中 有叛徒。叛徒会故意向不同的将军发送不同的消息。比如叛徒 C 对忠臣 A 说“我投进攻”,转头对忠臣 B 说“我投撤退”。这会导致忠臣之间产生误判,最终分崩离析。
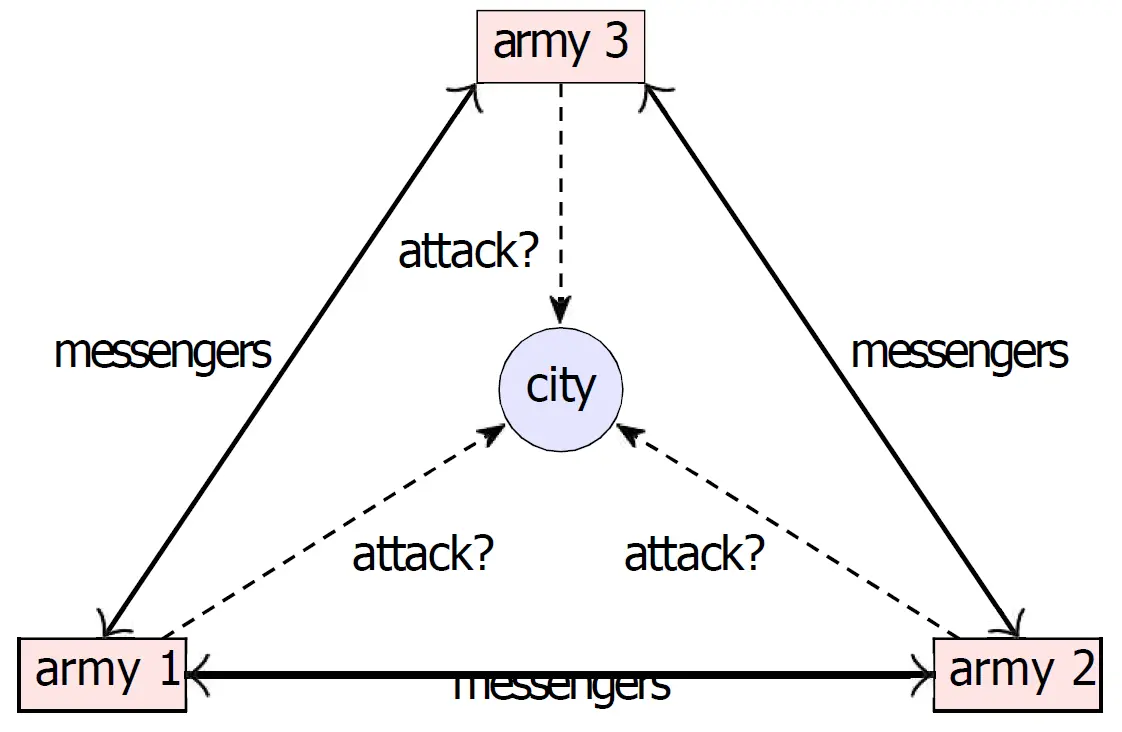
假设有 3 位将军:司令官(Commander)、副官 A(Lieutenant A)和副官 B(Lieutenant B)。规则是司令官下达命令,副官们互相核对信息,然后执行。
- 若副官 B 是叛徒:司令官下令:向 A 和 B 都发送了 “进攻”。A 收到了司令的“进攻”。此时,叛徒 B 为了搞破坏,对 A 撒谎说:“司令刚才悄悄让我 撤退”。此时 A 手里有两条信息:司令说“进攻”,同级副官 B 说“撤退”。A 无法判断是谁在撒谎。
- 或者是司令官本身就是叛徒,副官 A 和 B 都是忠诚的:司令官给 A 发送 “进攻”,却给 B 发送 “撤退”。忠诚的 B 如实对 A 说:“司令让我 撤退”。此时 A 手里依然有两条信息:司令说“进攻”,同级副官 B 说“撤退”。
以上的两种情况都会陷入了逻辑死局,共识彻底失败。
面临这样的情况,忠诚的将军们若想要达成共识,忠诚将军的数量必须占据压倒性的多数。在数学上,已经有一个严格证明(证明过程这里不展示),要想在包含 个恶意节点,且恶意节点可以互相串通(collude)的网络中,依然能够形成一个绝对可靠的多数派选票,系统的总节点数 必须满足 。
如果只有一个叛徒的情况下,总共 4 人:司令官、副官 A、副官 B、副官 C。我们重新推演:如果司令官是叛徒,A、B、C 都是忠诚的:他给 A 发 “进攻”,给 B 发 “撤退”,给 C 发 “进攻”。B 对 A 说:“司令让我撤退”。C 对 A 说:“司令让我进攻”。此时 A 进行投票统计:2 票进攻 vs 1 票撤退。同时,其他两位副官也统计收到的指令,三位忠诚的副官最后达成了完全一致的共识就是进攻。
我们通过一个例子来熟悉公式:例如 (有 2 名叛徒),代入公式进行计算,. 系统中 至少需要 7 名将军(即 5 名忠诚将军 + 2 名叛徒),才能在有 2 名叛徒串通搞破坏的情况下,依然达成可靠的共识。
系统的总节点数 必须满足 。这意味着,叛徒的比例必须严格小于总数的三分之一()。
如果系统总共有 名将军,最多能容忍多少名叛徒?代入公式计算:, 最多只能容忍 3 名叛徒。如果叛徒数量达到 4 名,共识机制就会被彻底破坏。
以上的两个实验给分布式系统一个启发:在实际系统中,节点和网络都可能出现故障。
- Two Generals Problem Model: 节点本身是诚实的,只是消息传输不可靠 (Nodes are honest, but messages may get lost)。它其实是 宕机模型 (Crash-stop / Crash-recovery) + 公平丢失链路 (Fair-loss links),或者统称为 遗漏故障模型 (Omission Fault Model)。两位将军(节点)都是忠诚的、诚实的,他们严格按照规则发消息,但是穿越山谷的通讯兵(网络)随时可能被抓(丢包)。
- Byzantine Generals Problem Model: 节点可能是不诚实的,但消息传递是可靠的 (Messages are reliable, but nodes may be dishonest)。为了单纯研究“内鬼”的破坏力,计算机科学家们在思想实验中排除了网络的干扰,假设信使只要派出去就一定能完美送达。但是,发出消息的将军可能是叛徒,他会故意发送虚假、自相矛盾的情报。
接下来将从网络行为、节点行为和时间时序行为入手,系统化分布式系统中的故障模型。
- 网络行为 (Network Behavior):描述消息是怎么丢的?定义了节点之间 连接通道的可靠程度。
- Reliable (Perfect) links (完美链路): 只要发送方把消息发出去,接收方 一定 能收到,绝对不丢包、不重复、不损坏。现实的物理网络中绝对不存在完美的链路。
- Fair-loss links (公平丢失链路): 消息可能会丢失、重复或乱序。如果 无限次地重复发送 同一条消息,那么这条消息 最终一定 能被成功送达。例如 TCP 协议的重传机制,本质上就是把物理层的不可靠链路,封装成了一个近似的 Fair-loss 链路。
- Arbitrary links (Active adversary / 任意或敌手链路): 链路不仅丢包,还可以捏造、篡改、拦截甚至复制重放消息。这是拜占庭模型在网络层的延伸。面对这种网络,我们必须引入密码学(如 TLS/SSL 加密、数字签名)来把 Arbitrary link 降级回 Fair-loss link 才能处理。
- Network Partition (网络分区): 整个网络被切断成两个或多个独立的子网。子网内部可以正常通信,但子网之间完全失联。例如光缆被挖断、机房交换机宕机。
- 节点行为 (Node Behavior):描述机器是怎么坏的?定义了系统中的计算机节点发生故障时的表现。按照破坏力从小到大排列:
- Crash-stop (Fail-stop / 宕机-停止): 节点一旦发生故障,就会立刻停止一切运行,并且 永远不会再活过来。同时,其他节点可以明确感知到它已经挂了。
- Crash-recovery (Fail-recovery / 宕机-恢复): 节点会宕机,但 过一段时间后可能会重启并重新加入网络。它的内存数据在宕机时会丢失(失忆),但可以通过读取本地硬盘(非易失性存储)或向其他节点请求来恢复状态。这是 最贴近现代云计算架构的模型。服务器可能会重启、容器可能会重建。
- Byzantine (Fail-arbitrary / 拜占庭故障): 节点不仅可能宕机,还可能 随心所欲地做任何事。它可能发乱码、可能恶意篡改数据、甚至与其他坏节点串通起来欺骗好节点。常见于不受信任的开放网络(如区块链),或遭遇黑客入侵的系统。
- 时间假设 (Synchrony Assumptions):系统能依赖时钟吗?分布式系统中的时间和延迟的影响。
- Synchronous (同步模型): 系统存在 严格且已知的上限(Upper bounds)。消息在网络中传输需要的时间,节点处理计算需要的时间等都是确定的。如果在规定时间内没收到回复,就可以确定对方宕机了。
- Partially Synchronous (部分同步模型): 系统大部分时间表现为异步(会有网络风暴、大延迟),但系统最终会度过这段混乱期,进入一个“同步期”(Global Stabilization Time, GST)。在 GST 之后,消息延迟就会恢复到一个正常的、有上限的水平。这是分布式系统共识算法设计的目标,在网络混乱(异步)时,它们可能无法提供服务(牺牲可用性),但绝对不会写错数据(保证一致性);等网络恢复平静(同步)时,它们又能快速恢复工作。
- Asynchronous (异步模型): 没有任何时间上限。一条消息可能 1 毫秒送到,也可能 100 年后才送到。节点处理可能瞬间完成,也可能卡顿无限久。在这种模型下,永远无法区分 一个节点是“挂了”还是单纯“很慢”。
在 Arbitrary link 模型中,网络里不仅有丢包,还可能潜伏着一个拥有“上帝视角”的黑客(中间人)。他可以拦截、篡改、伪造、甚至重复发送你的消息。
要想把这种恶劣的链路“净化”成我们可以信任的链路(通常在工程上称为 Authenticated Perfect Link,认证可靠链路),我们一般可以:先用 TLS 一类机制抑制 arbitrary 行为中的伪造/篡改/窃听/重放,再用 retry + dedup 一类机制把“可能丢、重复、乱序”的链路往更可靠的方向提升。
但若对手能永久丢弃流量或发生长期的网络分区,就不能保证真正的 reliable link。
面对上面这些像噩梦一样的故障,系统的抵抗能力就是 容错性 (Fault Tolerance)。它指的是 系统在发生部件故障时,依然能继续提供正确服务的能力。
可用性 (Availability) 是容错性的 定量指标。业界通常用 “几个 9” 来衡量。计算公式是:正常运行时间 / (正常运行时间 + 宕机时间)。
企业一般会定义 服务目标 (Service-Level Objective, SLO) 来定义可用性的范围,例如:“99.9% 的请求在一天内都能在 200 ms 内响应”。然后把某些 SLO 写进合同,并规定违反时的责任,这样成了 服务协议 (Service-Level Agreement, SLA)。
现代系统中一般引入了 故障检测器 机制,通过发送消息,等待响应,如果在某个时间内没有收到回复,则将节点标记为故障。
Replication
之前我们学习了分布式系统中的故障模型,也明白了容错性的重要性。为了提升容错性,提高读性能 / 负载均衡,并且兼顾不同地区的用户,我们通常会采用数据复制(Replication)技术。保存某份数据的节点称为 副本节点 (Replica)。
为了直观理解复制提高可用性,我们可以通过统计与概率直观理解副本的存在下,系统的故障概率。假设每个副本在某个时刻不可用的概率是 ,并且相互独立。
- 所有 n 个副本都坏掉的概率:,副本越多,全部同时挂掉的概率下降得非常快。
- 如果计算至少一个副本坏掉的概率: ,可以发现这个值随着 增大反而会上升。因为副本越多,“至少有一个出问题”当然更常见。但这不代表系统更差,因为我们通常关心的是 是不是还有至少一个能工作。
我们知道,如果数据不变化,复制数据到不同节点上很容易。但现实里数据经常变,例如点赞场景等,更新之后该如何维持副本的一致性与可用性?
我们通过一个点赞的例子来发现问题,假设客户端发出请求:点赞数 +1。点赞数本来当前是 12300,执行一次后应该变成 12301。但如果客户端没有收到响应,它可能会怀疑:请求是不是没到?服务器是不是执行了但响应丢了?于是客户端可能 重试一次。
但对于服务端而言,如果第一次其实已经执行成功,第二次又执行一次,那结果就是用户只点了一次赞,却加了两次。为了解决这样的重复更新问题 (Duplicate Update Problem),数据库必须跟踪它已经见过哪些请求,而且要保存在稳定存储中。
为了彻底解决 重复更新 问题,我们需要引入一个极其重要的数学概念——幂等性 (Idempotence)。
若一个操作执行一次和执行多次,产生的效果是完全相同的,那么可以称这项操作是 幂等的 (Idempotent)。用数学公式表达就是:。
以刚才的点赞为例,。如果执行两次:第一次是 , 第二次是 , 结果显然不一样,所以点赞操作 不是幂等的。
如果换一个思路,不用点赞数+1,而是维护一个“点赞用户集合”。,如果原来 , 用户 点赞,一次执行后 ,第二次点赞后结果不变,还是 ,不会重复增加,所以这个操作是 幂等的。
幂等操作适合副本的重试操作,因为重复执行不会把结果搞乱。在实际工程中,遇到重试操作时,一般会采取如下措施:
- 最多执行一次 (At-most-once): 这种模式下请求最多被执行一次,即使失败也不进行重试,虽然避免了副作用重复,但如果请求丢了,更新可能根本没发生。
- 至少执行一次 (At-least-once): 请求没收到确认就一直重试,更新大概率最终会发生,但可能重复执行。
- 恰好执行一次 (Exactly-once): 这是分布式系统追求的理想目标,即无论网络如何波动或重试多少次,最终效果等同于操作只执行了一次。在实现上一般使用重试 + 幂等操作或重试 + 去重来解决。
虽然幂等操作可以解决重试操作带来的问题,但是 单个操作幂等,不代表多个操作组合后的并发合并也幂等。我们来看下面的场景:
假设我们有两个幂等操作,分别是添加点赞和取消点赞: 和 。有一个用户他同时在使用手机(Client 1)和电脑(Client 2)。
- 第一次点赞 (Client 1 发起 ): 手机向数据库发出了点赞请求 。数据库成功执行,把该用户的 ID 放进了集合里。
- 系统故障 (丢包): 数据库向手机回复了
ack,但这个ack在网络中丢失了。此时,手机的视角里,这次点赞大概率失败了,正在倒计时准备重试。 - 取消点赞 (Client 2 发起 ):在这倒计时的几秒钟里,该用户在电脑端看到了最新的状态(
set of likes),这时他反悔了,点击了取消点赞。电脑端发送了请求 。数据库成功执行,把用户 ID 从集合中删除了,并成功返回了ack。 - 手机的自动重试 (Client 1 再次发起 ): 手机端因为一直没收到第一次的
ack,自动重发了点赞请求 。数据库收到了这个迟到的 ,立刻又把用户 ID 加回了集合中,并返回了ack。
用户的实际操作顺序是:点赞 取消点赞。期望的最终状态是 。但由于网络重试,数据库实际执行的顺序变成了:点赞 取消点赞 点赞重试。最终状态变成了 。我们分析这个结果:。操作 本身确实是幂等的,但是,两次 之间插入了一个会改变状态的相反操作 ,重试会覆盖掉其相反操作。
这个例子告诉我们,在分布式系统里,幂等性解决的是“重复执行”的问题,但它解决不了“乱序执行”的问题。
此外,现实中的分布式数据在涉及 删除操作 时还可能会遇到 幽灵复活(Ghost Data / Resurrected Data) 问题。如图的例子中,
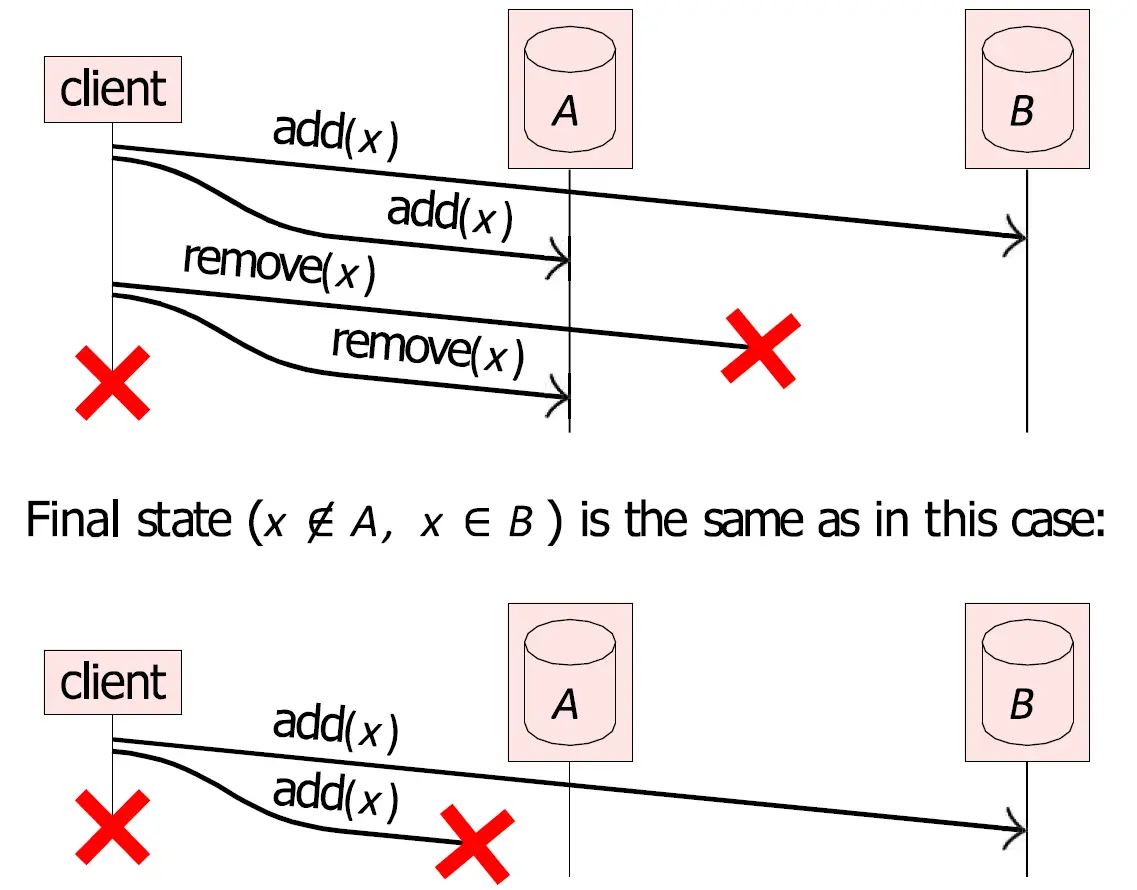
- 删除失败 (上半):客户端先向数据库 A 和 B 成功添加了数据
x。过了一会儿,客户端想删除x。它向 A 发送的remove(x)成功了,但向 B 发送的remove(x)因为网络故障失败了。客户端随后宕机。最后 A 里面没有x,B 里面有x。 - 添加失败 (下半):客户端向 A 和 B 添加数据
x。它向 B 发送的add(x)成功了,但向 A 发送的add(x)在半路上丢失了。客户端随后宕机。最后 A 里面没有x,B 里面有x。
在这两种情况的最后,系统的状态都是相同的:。当数据在 A 和 B 开始同步时,系统不知道应该同步删除还是同步添加,出现了 歧义。
为了消除这种歧义,我们引入了 时间戳 (Timestamps) + 墓碑 (Tombstone) 机制。同样是这个例子,客户端的每一次操作,都必须附带一个严格 单调递增 的逻辑时间戳(例如 Lamport Clock);当执行删除时,不要直接删除,而是给 x 打一个 不存在 (false) 的状态。如下图:
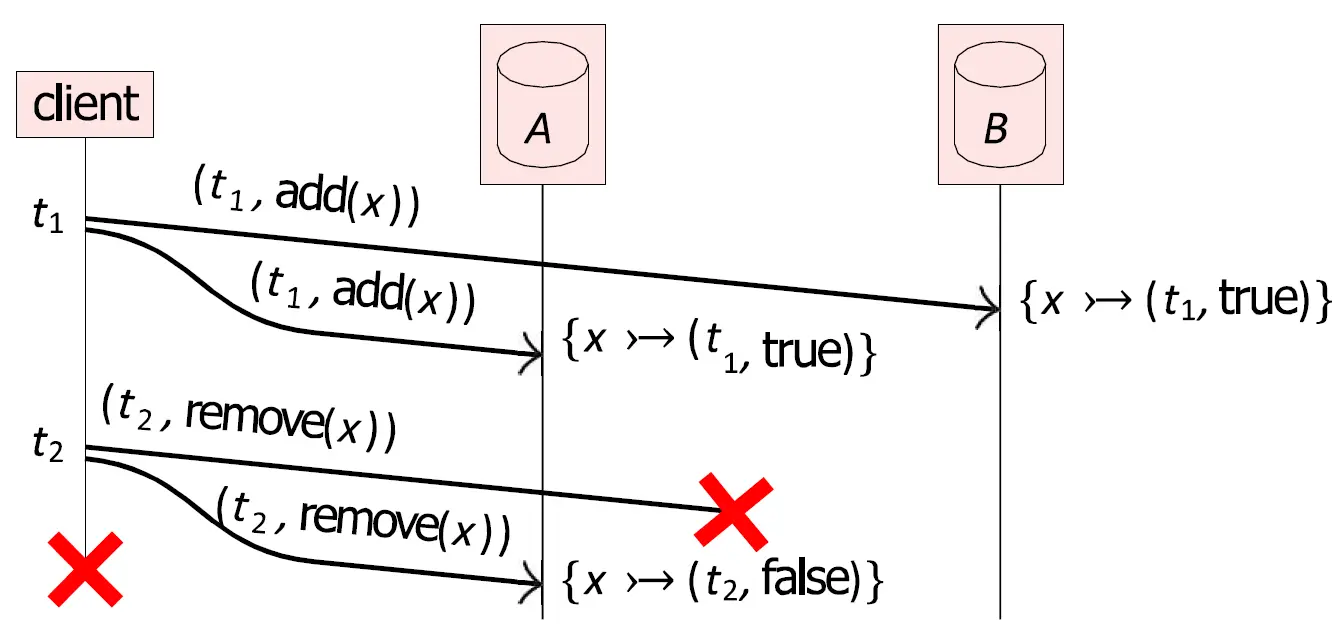
客户端带着时间戳 执行添加。A 和 B 都存下了这条记录:{x -> (t1, true)}。意思是在 时刻,x 是存活的。接下来在 时刻,删除请求发送给 A,在 A 并没有把 x 直接删掉,而是把记录更新为:{x -> (t2, false)};同理,删除请求发送给 B,但是请求在半路上丢包了,所以 B 依然保留着旧记录:{x -> (t1, true)}。
A, B 开始同步时,A: {x -> (t2, false)},B:{x -> (t1, true)}。因为 ,系统能得出正确的结论:删除操作发生在新,添加操作发生在旧。x 应该已经被删除,所以将 B 的记录也更新为墓碑 {x -> (t2, false)}。这个过程也称为 反熵 (anti-entropy),这个过程会定期在副本节点之间自动进行。
了解完重试操作和删除操作可能带来的不一致,及其解决方案后,我们再考虑一下一个经典的问题—— 并发写入。如果两个用户同时修改了同一个变量,怎么解决冲突?
两个客户端几乎同时更新同一个 key:client 1 写入 (t1,v1),client 2 写入 (t2,v2),而且两个写入之间没有明确谁先谁后的因果关系。这时不同副本可能先看到不同版本。对于这样的问题,我们一般有如下两种解决方案:
- LWW (Last-Write-Wins / 最后写入胜出): 给每次写入附带一个时间戳,服务器只保留时间戳最新的那个值(例如 Lamport Clock)。缺点也很明显,可能把并发且都合理的写入中的一个直接抹掉,产生 数据丢失 (data loss)。
- Multi-value Register (多值寄存器): 服务器通过带有因果的偏序时间戳 (例如 Vector Clock) 发现有两个并发的更新,如果
t2 > t1,说明v2因果上更新,保留v2;如果t1 || t2,则保留两个值{v1, v2}。由上层应用去解决多个值并存的问题。
与并发写入一样常见的是先读后写导致的一致性问题。在先读后写(Read-Modify-Write)场景下,如果客户端把数据写到副本 A,接着马上去副本 B 读取。如果 A 的更新还没传播到 B,那么客户端读到的是旧值。这就违反了 Read-after-write consistency(写后读一致性)
有一个简单但代价高的方法:写的时候写所有副本,读的时候也读所有副本。但是任何一个副本不可用,读/写都可能失败。
一个更加通用的解决方案是 Quorum (多数派/法定人数机制)。如果我们有 3 个副本,每次写入必须等 3 个都确认,太慢了且容错率低(挂 1 个就写不进去了)。如果只写 1 个,又容易丢数据。 Quorum 机制寻找了一个完美的平衡:不需要全部节点同意,只需要部分重叠的多数派同意即可。
假设系统有 个副本,配置写入需要 个节点确认,读取需要向 个节点查询。只要满足公式:,就能保证读取的 个节点中,必定至少包含一个拥有最新数据的节点。
我们通过一个例子来检验这个公式。如下图,假设总副本数 ,也就是节点 A、B、C。写入时,必须收到至少 2 个节点的确认,才算成功;读取时,必须向至少 2 个节点查询,才算成功。在这种情况下,由于 ,写入集合与读取集合必然存在交集。
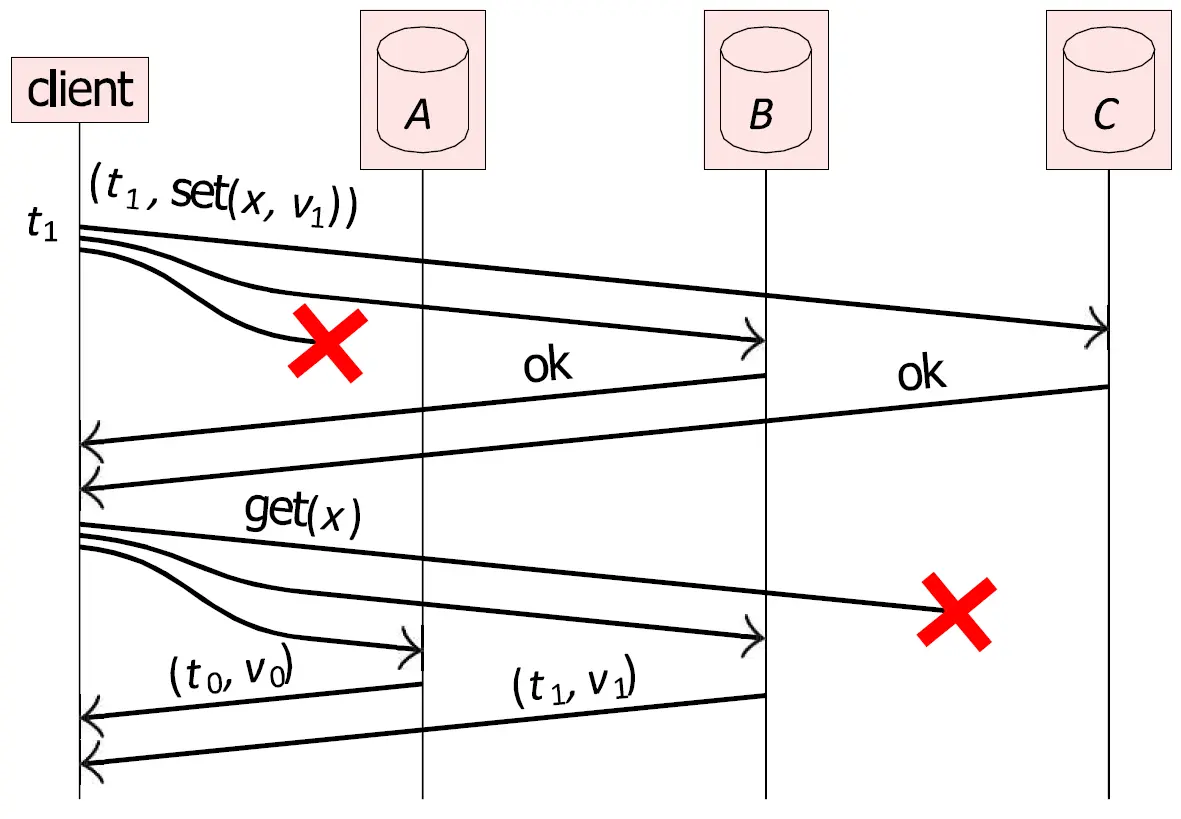
- 首先,客户端带着时间戳 发起写入请求,要把变量 的值设为 。请求被同时发给 A、B、C 三个节点。发给节点 A 的请求在半路丢包了,所以 A 根本不知道有这次更新,它依然是旧数据。B 和 C 成功收到了,并向客户端返回了
ok。客户端检查发现 ,所以认为写入成功。 - 过了一会儿,客户端想要读取 的值。客户端向 A、B、C 同时发送
get(x)请求。这一次是发往 C 的请求在半路丢了,A 和 B 成功收到了请求,并且返回了数据:A:(t0, v0),B:(t1, v1),客户端收到了 ,所以认为本次读取成功。
因为 的交集定律,客户端读取到的 2 份数据中,绝对包含至少一份最新写入的数据。所以客户端比较两份数据的时间戳: 和 。因为 ,所以 选取 B 提供的 作为最终的正确答案展示给用户。
在真实的系统中,客户端或者协调节点在发现 A 的数据落后时,还会顺手触发一个叫 Read Repair(读修复) 的后台动作,把 同步给 A 和 C(同步给其他所有的副本)。
在系统中, 和 的值一般取 ,这样可以推算出,读能容忍 个副本不可用,写能容忍 个副本不可用。
在以上的副本复制中,我们一直使用尽力而为的广播。为了实现更强的一致性,我们可以使用更强的 FIFO 全序广播 (FIFO Total Order Broadcast),即 每个节点按相同顺序交付相同消息。
我们可以把每个副本看作一个 状态机(State Machine),满足:初始状态相同、接收到的更新序列一样,且每一步执行逻辑是确定性的,那么最终状态一定一样。即 相同初始状态 + 相同输入顺序 + 确定性执行 = 相同最终状态。
我们可以定义,强一致性 (Strong Consistency) 是指每个副本初始状态相同,按相同的顺序经历相同的状态转换序列,使得所有副本的最终状态相同。
这种机制被称为 状态机复制(State Machine Replication),是实现分布式系统 强一致性 (Strong Consistency) 的核心范式。在这种模型下,只要底层网络能保证消息的全序传递,各副本即可独立演化并保持状态同步。
然而,SMR 可能导致无法立即更新状态,必须等待通过广播交付。如何在不可靠的网络环境中可靠地达成这种全局一致的顺序,正是接下来共识算法(Consensus)所要解决的核心挑战。
Consensus
在之前的 Quorum 机制中,我们看到系统可以容忍故障,但是客户端需要比较时间戳来决定用哪个数据。但在很多核心业务场景下,我们不能让客户端去猜。系统内部必须对某个事件达成 一致的共识。
共识算法 (Consensus Algorithms) 的目标就是让一群可能随时宕机、且网络可能随时延迟的节点,像一个单机节点一样对外提供确定性的服务。
最直观的方法就是 单领导者 (single leader) 法。系统先选择一个 leader,所有消息先发给 leader,leader 再按顺序广播给所有人。但是这样的中心化系统的问题也很明显:leader 一挂系统就挂了,而且换 leader 很麻烦,尤其要保证安全地切换。leader 挂了以后,一般有两种常见的思路:
- 手动故障切换(manual failover):人工选一个新 leader,然后重配置系统。
- 自动故障切换:使用 共识算法 (Consensus) 选取新的 leader。
共识 (Consensus) 的定义是:让所有节点对 单个值 达成一致(比如决定谁是 Leader)。一旦决定,永不更改。如果在 全序广播 (Total Order Broadcast) 中就是所有节点对 每一个下一条要交付的消息是谁 这一串值达成一致,即所有的节点都以相同的顺序交付一系列消息。
所以简单来说就是:共识 (Consensus) 决定一个值,全序广播 (Total Order Broadcast) 连续决定一串值。Total Order Broadcast = 一连串的 Consensus。共识 (Consensus) 和全序广播 (Total Order Broadcast) 在形式上是等价的。
如果想要实现全序广播,也就是状态机复制 SMR,只需要 连续不断地运行共识算法 即可。
常见的共识算法有:
- Paxos: 是一个经典的共识算法,一次只决定一个值的共识 (single-value consensus)。
- Multi-Paxos: 把 Paxos 扩展成连续决定多个值以支持 Total Order Broadcast。
- Raft / Viewstamped Replication / Zab: 这些算法在功能上与 Multi-Paxos 类似,旨在解决分布式系统中的状态机复制问题。它们通过引入强领导者(Leader)机制简化了共识流程,并提供了更为清晰的日志复制和成员变更规范。它们默认支持 FIFO Total Order Broadcast。
这些共识算法通常假设在如下的系统模型上:
- 时间假设:部分同步 (Partially Synchronous) ,时间不可靠,即系统平时可能乱,但最终会进入一个“足够稳定”的阶段。根据 FLP 不可能定理 证明了:在纯粹的异步网络中,哪怕只有一个节点会宕机,也不可能存在任何确定的共识算法。
- 节点行为:宕机-恢复 (Crash-recovery),假设节点诚实,不会发假消息(非拜占庭),但随时可能死机并重启。
- 网络行为:公平丢失链路 (Fair-loss) ,网络不可靠,允许网络丢包、乱序、延迟,甚至短暂的网络分区。
Multi-Paxos、Raft 等算法都使用 leader 来排序消息,它们一般使用超时故障检测器(例如定期发送 heartbeat)来判断 leader 疑似故障或不可用,一旦怀疑 leader 失效,就发起新的 leader 的选举。
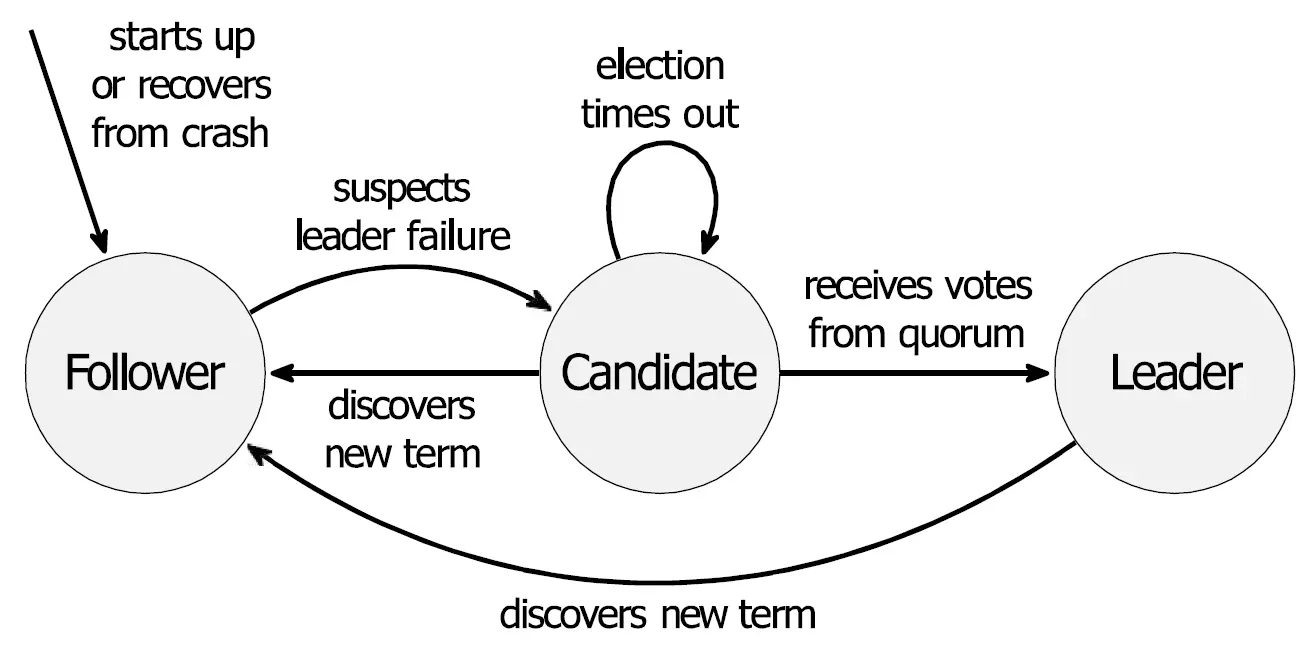
Raft 集群中的任何节点,在任意时刻只能处于以下三种状态之一:
- Follower (群众): 系统的初始状态。完全被动,只负责接收和回应 Leader 的指令或 Candidate 的拉票。如果在规定时间内没听到 Leader 的声音,就会发起选举。
- Candidate (候选人): Follower 没听到 Leader 心跳,怀疑 Leader 挂了后升级成的状态。它会向所有人发起投票,试图当选。
- Leader (领导者): 赢得多数派选票后上位。拥有绝对权威,负责接收客户端请求、向 Follower 同步日志,并持续发送心跳以维持统治。
当系统启动,或者现任 Leader 宕机时,选举开始:
- 某个 Follower 的倒计时(Election Timeout)结束。
- 它立刻将自己升级为 Candidate,把当前的 任期号 (Term) 加 1,并把票投给自己。
- 它向全网广播
RequestVote(拉票)消息。 - 其他 Follower 收到拉票请求,如果它在这个任期还没投过票(一个节点一个任期只能投一次票),并且觉得这个 Candidate 足够新,就会投赞成票。
- 随机超时: 为了防止所有人同时升级为 Candidate 导致平票,Raft 让每个节点的超时倒计时是一个 随机值。这就保证了总有一个节点会先醒来,迅速拉拢多数人。
一旦 Candidate 获得了集群中超过半数节点的选票 (Quorum),它就会正式晋升为新的 Leader。上位后的 Leader 会立即向所有节点发送心跳消息,以宣布自己的权威并重置各节点的倒计时,从而阻止新一轮选举的发生。通过这种多数派投票和任期机制,Raft 确保了在任何给定的任期内,系统中最多只有一个合法的 Leader 存在。
Raft 只能保证 同一个任期 (Term) 内最多只有一个合法的 Leader 存在, 而不能保证永远只有一个 Leader。如果网络发生分区,少数派那边可能会选出一个自己的 Leader,此时就是脑裂 (Split Brain) 现象了。但是因为它无法收集到多数派的确认,所以也无法当上真的 Leader。
Raft 的原则是认 Term 不认节点。假设由于网络故障,旧 Leader(Term=2)与其他节点失联了。大部队已经选出了新 Leader(Term=3)并正常工作。当网络恢复时,旧 Leader 依然以为自己是老大:旧 Leader 向大部队发送附带 Term=2 的心跳包。其他的节点收到后会回复一个拒绝消息,并在回包中附带当前的最新任期 Term=3。旧 Leader 收到这个回包,发现自己的任期小,马上降级为 Follower,并更新自己的 Term。
但是还有可能存在旧的 leader 提交信息的问题,所以对于每一个 decision(下一条要交付的消息),leader 都必须先从一个 quorum 获得确认。如果它已经被更高 term 的新 leader 取代,那它就拿不到 quorum 的确认。
Concurrency Control
从一个大家常见的场景开始,多个用户/设备共享一个文档,每个设备保存本地副本,可以随时修改本地副本,甚至离线修改,在网络恢复后再同步文档(例如 Git)。同步的时候就容易发现,如果 两个副本在都改了同一个对象,怎么合并?我们把这样的问题称为 并发更新 (concurrent updates)。
解决并发更新问题有两种常见的算法:
- CRDT (Conflict-free Replicated Data Types / 无冲突复制数据类型): 它使用了去中心化协调的数据结构。它通过特定的数学属性确保 即使更新操作以不同顺序到达,各副本最终也能收敛到一致的状态。CRDT 避免了复杂的冲突解决逻辑,非常适合用于实时协同编辑、分布式缓存和大规模状态同步等场景。
- OT (Operational Transformation / 操作转换): 通过对操作进行转换来确保并发更新的一致性。它通常依赖于 中心服务器对操作进行排序和转换处理,以保证所有副本在应用相同操作序列后达到一致的状态。OT 广泛应用于 Google Docs 等在线协作工具中,虽然其算法实现复杂度较高,但在处理复杂的文本编辑冲突时具有非常成熟的应用。
CTDT 有两种实现思路,一种是基于操作的 (Operation-based CRDT),节点之间广播的是“做了什么操作”。还有一种是基于状态的 (State-based CRDT),它会更新自己的本地状态,再广播状态值,与自己进行合并。
以 Map(键值对映射表,比如字典或 JSON 对象)为例,基于操作的 CRDT 的基本思路是:当用户修改 Map 时,节点只在本地生成一个极小的“操作指令”(Operation),然后把这个指令广播出去。假设本地发生了一个操作:用户把 "title" 改成 "Lecture 1"。节点不会发送整个 Map,它只发送一条指令:(t1, "title", "Lecture 1"),并附带当前的全局唯一时间戳 。然后通过 reliable broadcast 广播给所有副本。
其他副本在收到该指令后,会根据其携带的时间戳和操作内容更新本地的 Map 状态。如果使用 Last Writer Wins (LWW) 方法,则保留时间戳最大的操作。
因为使用了 reliable broadcast, 所以每个更新最终都会被每个正常副本收到。因为网络会乱序,不同节点收到指令的顺序可能完全不同。基于操作的 CRDT 要求 所有的并发操作,必须是可交换的(Commutative)。它非常依赖底层网络,必须实现可靠的因果广播。最终达到 一致(Strong Eventual Consistency, 强最终一致性)。
基于状态的 CRDT 不再是广播操作,而是把整个 Map 的当前完整状态打包,再加上全局唯一的时间戳,通过尽力而为的广播发送给其他节点。如果我们要合并两个状态 Map A 和 Map B:对于只在 A 或只在 B 中存在的 Key 直接取两者的并集即可。存在并发更新冲突时,这就要求 CRDT 算法的合并同时满足:交换律 (Commutative) 以解决顺序不同的问题 - , 结合率 (Associative) 以解决同步过程可能分批发生的问题 - , 幂等性 (Idempotent) 以解决重复处理的问题 - ,
基于状态的 CRDT 对网络要求极低,不怕丢包,不怕乱序,不怕重复发送,但是因为每次广播都发送完整状态,网络开销大。
总的来说:
- 基于操作的 CRDT:消息小,但更依赖广播语义和操作交付。
- 基于状态的 CRDT:状态大,但实现上更鲁棒,因为重复发状态、丢了几次状态都没关系,之后继续 merge 还能收敛。
但当场景到更常用的共同编辑文本时,比 Map 操作难上很多。例如多人同时编辑一段字符串 "BC"。User A 想在最前面插入 "A",本地执行 insert(0, "A"),结果变成 ABC。User B 想在最后面插入 "D",本地执行 insert(2, "D"),结果变成 BCD。当 A 收到 B 的操作时,文本里位置发生了变化,索引整体变了。我们无法像 Map 操作那样找到一个固定位置的 Key。
OT (Operational Transformation) 使用 绝对位置 的整数索引(0, 1, 2…)来定位字符。但它的转换逻辑复杂,且通常需要一个中心服务器来确认操作的先后顺序。
- A 收到了 B 发来的
(insert, 2, "D")。如果 A 直接在自己的ABC的索引2处插入"D",结果会变成ABDC,但此时索引位置变了,这样插入是错的。A 的系统运行了一个转换函数 。它对比了刚才自己做的操作和收到的操作,得出结论:因为我已经在0的位置插了一个字符,所以 B 这个原本想插在2的操作,必须往后挪一位,变成插在3的位置上。 A 执行转换后的操作,最终得到ABCD。 - B 收到了 A 发来的
(insert, 0, "A")。B 的系统运行转换函数 。它发现自己是在索引2插入的,这完全不影响 A 在索引0的插入。,B 执行原封不动的操作,最终得到ABCD。
Text editing CRDT 的思路更加精细,它彻底抛弃容易产生偏移的整数索引,给每个字符分配一个全局唯一的、支持无限分割的 小数索引(Fractional Indexing)。例如:初始状态 "BC" 分别被赋予了位置:B(0.5) , C(0.75) 。预设开头为 0.0,结尾为 1.0。
- User A 想在开头插入
"A"。系统就在0.0和B(0.5)之间找一个数,比如选了0.25。A 发出的指令是(insert, 0.25, "A")。 - User B 想在最后插入
"D"。系统就在C(0.75)和1.0之间找一个数,比如选了0.875。B 发出的指令是(insert, 0.875, "D")。
当这两个并发操作在不同终端同步时,由于 0.25 和 0.875 是绝对且唯一的,只需要 按小数大小重新排个序 就行了。但它的代价是,每个字符都要背着一长串的元数据(比如那个越来越长的小数索引),内存占用大。
OT 和 CRDT 解决了单篇文档的并发合并。在实际的业务中,我们可能需要管理来自全球的数据,并且满足跨数据中心事务一致性。Google Spanner 是第一个把 全球分布 和 强一致性事务 完美结合的数据库系统。
Google Spanner 的目标是 Serializable Transactions Isolation (可串行化事务隔离) 和 Linearizable Reads/Writes (线性一致性读写)。
- Serializable Transactions (可串行化事务):在 Spanner 中,成千上万个事务在世界各地的服务器上并发执行。但 Spanner 保证,最终的数据结果,看起来就像是这些事务 串行执行 一样的。没有任何脏读、幻读或不可重复读的破绽。
- Linearizable Reads/Writes (线性一致性读写):如果一个写在现实时间上已经完成,那么之后开始的读必须能看到最新的它,就像只有一份副本那样。绝对不会读到旧历史。
在 Spanner 中,如果事务有因果关系:,那么一个包含 写入的快照,也必须包含 的写入;反过来,如果快照不包含 ,那也不该包含 。这说明快照必须尊重因果关系(consistent with causality)。如果 ,必须有 。
在并发控制中,最慢的就是读写冲突,即一个用户在读的时候,其他用户写的冲突。Spanner 使用了 MVCC (Multi-Version Concurrency Control / 多版本并发控制) 去解决。
MVCC 在写的时候不覆盖旧数据,而是会附带一个时间戳 ,作为新版本保存下来。当需要读取数据时,只需要告诉 Spanner:要读取时间戳 这一刻的快照。Spanner 就会在底层找到时间戳 小于等于 的最新版本给你。通过这样的方法,只读操作不需要加锁 (read-only transactions require no locks),也永远不会被写操作阻塞。
但是在 Spanner 中,不能直接用物理时钟或 Lamport clock 做 Spanner 的时间戳。物理时钟很好理解,因为不同地区时钟可能存在偏差。而Lamport clock 能通过计数器反映事件的因果顺序,但是无法反映真实物理时间顺序。Google 为了解决这个问题,直接在每个数据中心装上了原子钟(Atomic Clocks)和 GPS 接收器,引入 TrueTime。
TrueTime 不返回一个确切的时间点,而是返回一个 时间区间:。它向软件保证,当前的绝对真实时间,绝对在这个区间内。时钟不确定性 。
假设有两个节点: Node A 和 Node B,如图。
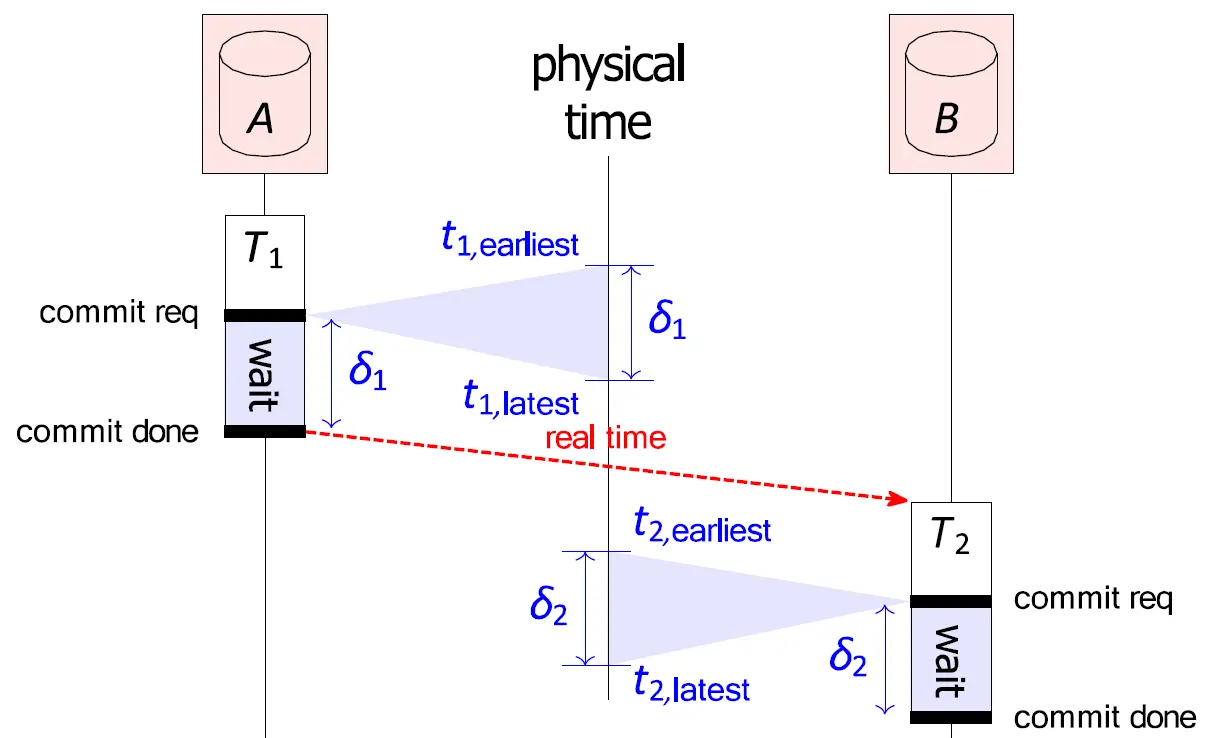
- 在节点 A 上,事务 准备提交 (
commit req)。它调用 TrueTime,得到了一个真实时间区间:。Spanner 强制给 分配的时间戳是这个区间的上限,也就是 。 - 此时系统会要求客户端 强制等待 (The Wait),等待 之后,真实的绝对物理时间,已经 越过了 刚才分配给 的时间戳 。此时,系统才触发
commit done,告诉外部世界事务已完成。 - 随后,如果有一个现实因果关系 ,它存在现实中的延迟,另一个事务 在节点 B 上开始, 发生时的真实物理时间。因为前面的强制等待,加上现实因果关系的时间流逝,对于 TrueTime 给出的 最早可能时间 ,在物理轴上已经严格晚于了 。
这就完美保证了:如果事务 在真实世界中发生于 之后,那么系统为 分配的时间戳,必定严格大于 的时间戳。
