
前言
本章将从数据挖掘中的四项经典核心任务开始,探索数据挖掘的底层逻辑。从寻找相似性的 TF-IDF 和 MinHash 开始,到 Clustering (聚类) 和 Anomaly Detection (识别异常),最后再通过隐变量模型 (Latent Variable Model) 剥离表象,直达隐变量。
本章将通过四个经典的例题,并补充必要的数学知识,来介绍数据挖掘中的四项核心任务。
注:常见的考试中会出的部分将使用 红色 进行标记。简略部分的总结请看 总结部分。
Task 1: 基础数据收集与相似度分析
这一部分主要涉及数据的预处理,计算 TF-IDF,文档的向量化和简单的相似度计算。文档相似度分析是整个自然语言处理(NLP)和信息检索的核心基石。
这个过程包括:预处理与词频统计 -> TF-IDF 计算 -> 向量化构建 -> 余弦相似度分析。
假设我们有以下四个文档:
Document 1: The Development of Electric Vehicles
Electric vehicles have rapidly evolved, with battery technology driving their growth: new high-capacity battery designs have doubled the range of electric vehicles, directly elevating their performance. Better performance has made electric vehicles more competitive than traditional vehicles, attracting wider adoption. As battery innovation continues, electric vehicles will further improve in performance, solidifying their role in sustainable transportation.
Document 2: Advancements in Battery Technology
Modern battery innovations are reshaping global energy systems. New lithium-ion variants boost energy density, letting a single battery store more charge and extend device lifespans. Smart charge management also optimizes battery performance, reducing waste and enhancing storage efficiency. As demand for clean energy grows, next-gen batteries will further bridge gaps between energy production and storage, making reliable, fast charge solutions universal.
Document 3: Renewable Energy Integration
Renewable energy integration has become a global priority, as societies strive to replace fossil fuels with sustainable renewable sources like solar and wind. A key challenge lies in storing excess renewable energy, and battery technology emerges as a critical solution: batteries store surplus energy during peak production and release it when demand surges. Without reliable battery storage, the instability of renewable energy would hinder its large-scale integration into power grids, making batteries indispensable for unlocking renewable energy’s full potential.
Document 4: Sustainable Transportation Solutions
Sustainable transportation solutions are reshaping urban mobility, with electric vehicles at their core. These electric vehicles reduce carbon emissions far more effectively than traditional cars, aligning perfectly with sustainable goals. Cities worldwide now prioritize electric transportation infrastructure—charging stations, dedicated lanes—to boost adoption of electric vehicles. Only by scaling such sustainable measures can transportation systems break free from fossil fuel reliance, making electric vehicles a cornerstone of truly sustainable transportation.
Step 1第一步:数据预处理与关键词提取 (Pre-processing)
在分析文档相似度之前,我们必须先清理数据。
- 去除停用词 (Stop Words): 原始文档包含很多像 “the”, “is”, “and” 这样的功能词,它们对文本含义贡献很小。我们需要根据给定的列表移除它们。
- 提取关键词 (Key Term Extraction): 去除停用词后,我们要统计剩余词汇的频率,并确定一个包含 个关键词的统一词汇表 ,这里以 10 个关键词为例。
- 词频统计 (Count):接下来在每个文档中,计算每个关键词出现的原始次数。在考试中,词频需要根据文档进行补全计数。此外,我们最好还需要计算出每个文档涉及的 关键词总数。
- D1 关键词总数为
- D2 关键词总数为
- D3 关键词总数为
- D4 关键词总数为
Step 2第二步:TF-IDF 计算 (The Core Calculation)
TF-IDF 是一种统计方法,用于衡量一个词对于一个文档集中的某一篇文档的重要性。它的计算包含:1. 词频 (Term Frequency, TF) 和 逆文档频率 (Inverse Document Frequency, IDF)。在考试中,TF-IDF 一般需要根据具体的数据和给出的 log 参考值进行计算 (TF为0的值不需要计算) 。
-
TF (Term Frequency, 词频): 衡量词 在文档 中的密集程度。公式:
例如:D1 中的 electric 出现次数为 ,总词数为 。
-
IDF (Inverse Document Frequency, 逆文档频率): 衡量词 的稀有程度(越稀有越重要,权重更高)。它是对于所有文档的。在本章中, 用 表示 (以 为底),以方便计算。
其中 是文档总数(这里 ), 是包含词 的文档数量。
例如对于词 electric,它出现在 D1 和 D4 中,所以 。
对于词 charge,只出现在 D2 中,。
-
TF-IDF: 词频-逆文档频率的乘积,用于衡量一个词对于一个文档的权重。
例如 D1 中 electric 的 TF-IDF 为:
Step 3第三步:文档向量化 (Vectorization)
计算出所有 TF-IDF 值后,我们将每篇文档转换成一个向量。这是将文本转化为计算机可计算形式的关键步骤。
我们需要构建一个矩阵,行代表文档,列代表词汇表中的 个关键词。这样的表示方式称为 词袋模型 (Bag-of-Words model)。
在考试中,向量化需要根据之前计算得到的 TF-IDF 值进行填空即可。
向量中为 0 的位置表示该词(如 energy, storage)在该文档中未出现。
Step 4第四步:余弦相似度分析 (Cosine Similarity)
最后,我们通过计算向量之间的夹角余弦值来判断文档有多相似。值越接近 ,文档越相似。余弦相似度:
-
计算向量长度 (Magnitude/Norm): 首先计算每个向量的模长 。例如 D1 的模长: 。
-
计算点积 (Dot Product): 计算两个向量 对应位置数值的乘积 之和。这个就是矩阵的点乘,以 D1 和 D4 为例:
-
计算相似度:
现在可以得到最终的相似度矩阵:
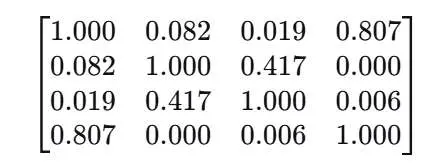
通过这样的矩阵,可以得出文档之间的相似度关系结论:
- D1 与 D4 最相似(≈0.806):共同高权重词是 electric / vehicles / sustainable / transportation(D4 几乎围绕可持续交通与电动车)。
- D2 与 D3 次相似(≈0.416):共同点在 energy / battery / storage(电池与能源存储链条)。
- D2 与 D4 几乎完全不相似(0):两者在该词汇表 TF‑IDF 上没有共同非零维度(D2 偏 energy/charge/storage;D4 偏 electric/transportation)。
在考试中,余弦相似度需要进行部分计算,并根据得到的相似度矩阵给出结论。
总结:这一部分是一个完整的文本相似度计算过程,需要根据具体数据进行计算和填空。建议是多加练习计算这一过程,并使用实际数据进行测试。
Task 2: MinHash (最小哈希)
如果在 Task 1 中我们关注的是词频和精确的余弦相似度,那么在 Task 2 中,我们切换到了 处理大规模数据 的思维模式:我们不再关心词频,只关心“有没有”,并用极短的 签名 (Signatures) 来快速估算文档的相似度。
Minhash 通过随机哈希函数,将文档映射到一个 签名 (Signature) 中,然后计算签名之间的相似度。
Step 1第一步:理解数据表示 (One-Hot Encoding)
首先,文档将不再转换为词频向量,而是简单的 二进制向量 (Binary Vectors)。
- 代表关键词存在 (presence)。
- 代表关键词不存在 (absence)。
例如给出关键词列表:
我们可以得到对应的每个文档的二进制向量(文档的具体内容省略了,这里直接展示了二进制向量):
对于 D1,它的向量中的 表示它包含第 1, 2, 3, 6, 9 个关键词。我们在 Task 1 中的 TF-IDF 矩阵是稠密的实数,而这里的输入是稀疏的 0/1 矩阵。
Step 2第二步:MinHash 签名计算
MinHash 的核心思想是:置换 (Permutation),即打乱列的顺序,看谁先出现 “1”。
我们需要根据置换向量 ,找到每个文档第一个出现 1 的位置,这个位置就是 MinHash 签名 (Signature)。在考试中,会给出随机的置换向量,根据向量的检查顺序找到其第一个 “1” 出现的位置。并得到 Document / MinHash Signature 表。
例如两个随机置换顺序 和 :
这意味着:先检查第 3 列,再检查第 8 列,然后第 1 列…以此类推。
同理, 先检查第 7 列,再检查第 2 列,然后第 9 列…以此类推。
我们需要记录的是在新的检查顺序下,第几次检查遇到了 “1”(即 Rank/Index),而不是原始的列号。
例如对于置换 1 (): [3, 8, 1, 6, 10, 4, 9, 2, 7, 5],我们可以根据置换矩阵改变文档的二进制向量顺序,得到:
我们按照 的检查顺序,检查每个文档的二进制向量,并记录第一个 “1” 的索引。
D1: 第一个”1”的索引是 1,所以 。 D2: 第一个”1”的索引是 2,所以 。 D3: 第一个”1”的索引是 1,所以 。 D4: 第一个”1”的索引是 2,所以 。
同理,我们可以得到 , , , 。
所以,此时有:
| Document | MinHash Signature [] |
|---|---|
| D1 | [1, 2] |
| D2 | [2, 1] |
| D3 | [1, 2] |
| D4 | [2, 1] |
Step 3第三步:相似度对比 (Jaccard vs. MinHash)
最后一步是计算 MinHash 的文档相似度,并评估 MinHash 的效果。
MinHash 方法中文档的相似度通过计算两两签名向量中,数值相同的位置所占的比例,即 数值相同的位置个数 / 所有的位置数。在考试中,可能会有多个签名,需要逐一进行比较计算其相似度。有几个置换向量就有几个位置数。
例如:
- D1 和 D3,。两个位置都一样 ()。所以相似度:
- D1 和 D2,。两个位置都不一样。相似度: 。
因为 MinHash 是用“哈希碰撞”的概率来模拟“集合重合”的比例。我们需要比较其相似度和真实值的差距。真实的相似度一般使用 Jaccard 相似度 来计算。它实际是文档关键词的 交集大小 / 并集大小。
例如 D1 和 D3,有 4 个共同关键词:“data, learning, optimization, system”,一共有 6 个非重复的关键词:“algorithm, data, learning, optimization, system, training”。
所以 。
我们可以将 MinHash 的相似度与 Jaccard 的相似度进行对比,并评估 MinHash 的效果。即计算其误差
例如 D1 和 D3,。你会发现 MinHash 的估计值 (1.0) 和真实值 (0.667) 有较大误差。这可能是因为我们只用了 2 个置换 ()。样本太少,偶然性极大。

MinHash 是无偏估计。随着置换次数(哈希函数数量)的增加,MinHash 相似度会逐渐收敛于真实的 Jaccard 相似度。
总结:在计算 MinHash 的签名时,需要记录文档向量中第一个出现的 1 的索引。
- 列出置换顺序:把 向量写在草稿纸上。
- 逐个核对文档向量:像扫雷一样,按照 的顺序在文档向量里找第一个出现的 1。
- 填表:签名矩阵的行是哈希函数(P1, P2…),列是文档(D1, D2…)。
注意题目给出的索引是从 0 开始还是从 1 开始。如果 的第一个数是 3,代表我们要去看原始向量的第 3 个位置。
Task 3: 聚类分析与异常检测
这一部分分为两个核心阶段:K-means 聚类迭代 和 基于统计的异常检测。
- 聚类 (Clustering):寻找“大多数”的共性,建立秩序。
- 异常检测 (Anomaly Detection):关注“极少数”的偏离,发现变数。
Part 1第一阶段:K-means 聚类 (K-means Clustering)
K-means 的目标是找到数据的 自然分组。例如,把 6 个点分成 个簇。
假设我们有 6 个客户,两个特征 (月均消费评分(0–10)), (满意度评分(0–10)),给出初始中心 (Initial Centroids) 为 和 。
在考试中,经常需要补全迭代过程中的一些数据,需要牢记这个过程。
-
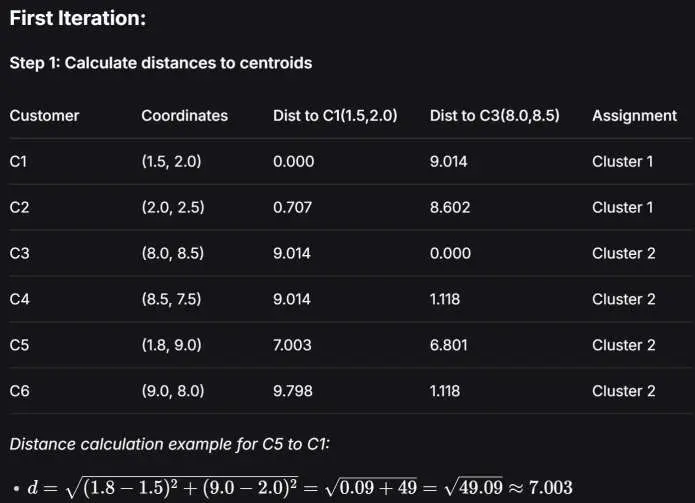
第一次迭代 —— 指派 (Assignment):计算每个点到这两个中心的欧几里得距离,谁近就归谁。
例如 :到簇 1 的距离 。到簇 2 的距离 。,所以 C5 被分配给 簇 2。
最后得到:
- 簇 1: C1, C2
- 簇 2: C3, C4, C5, C6
-
计算误差 MSE (Mean Squared Error,均方差/标准差):根据给出的 MSE 公式,计算当前迭代中的均方误差。
其中 : 样本总数 (这里 );: 第 个样本点;: 第 个样本所属簇的中心点;: 欧几里得距离的平方 (Squared Euclidean Distance)。
我们需要计算所有点到其簇的平方距离,例如 :到其分配的簇 2 的平方距离为
将这些距离的平方相加后除样本数 ,,
-
更新中心 (Update):根据分配结果,重新计算中心点(即计算簇内所有点的平均值)。
- 新簇 1 ,分配节点为 (C1, C2),中心变为 。
- 新簇 2 ,分配节点为 (C3, C4, C5, C6),中心变为 。
-
计算更新后的误差 (Error After Update):根据新的簇坐标,重新计算距离得到新的误差。
可以看到,误差减小了。
-
迭代:使用新的中心点再次计算距离并重新分配。重复步骤 1-4,当分配不再改变时,算法收敛 (Converged)。
我们可以手动模拟一下第二次迭代如图:
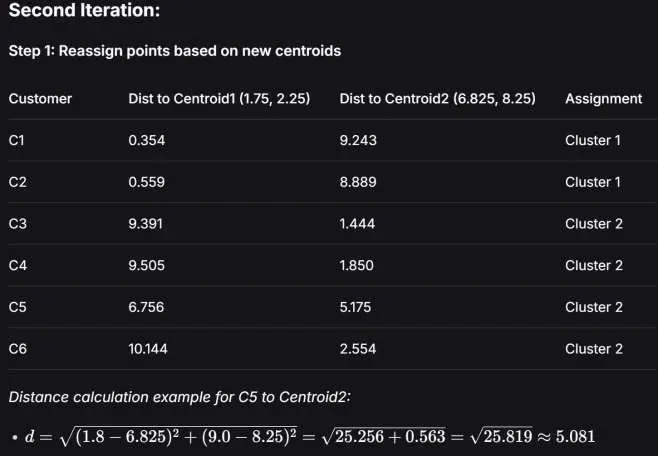
可以发现分配没有改变,算法收敛。
Part 2第二阶段:异常检测 (Anomaly Detection)
聚类的过程中,我们发现难免有些数据会离群。例如,C5 被分配给簇 2,但 C5 的特征值离簇 2 的中心点太远了。在考试中,会要求我们根据数据计算阈值,并判断异常点。
下面的步骤可以进行 基于统计的异常检测:
- 计算簇内距离 (Intra-cluster Distances):我们需要计算每个点到它最终归属的簇中心的距离。这个在我们前面计算 MSE 的时候已经计算过了。

可以发现,C1, C2 距离簇 1 中心都很近 ()。C3, C4, C6 距离簇 2 中心也算正常 ()。C5 (1.8, 9.0) 虽然归在簇 2(高消费高满意),但它其实是“低消费高满意”。它距离簇 2 中心 的距离高达 5.081。
-
统计学判定 (Statistical Thresholding):不能光凭感觉说 5.081 很大,我们需要一个统计标准。根据经验公式,一般采用 作为阈值。其中, 是簇内距离的均值, 是簇内距离的方差。
-
计算 均值 (Mean): 所有 6 个距离 () 的平均值
-
计算 标准差 (Std Dev): 根据计算得到的均值,带入标准差公式测算距离波动的大小。
带入数据,
-
计算 阈值 (Threshold):
-
-
判定异常点 (Detect Anomalies):如果某个点到簇中心的距离超过了阈值,则判定为异常点。根据我们计算得到的数据,C5 的距离 (5.081) > 阈值 (4.244)。所以 C5 是异常点 (Outlier)。
我们可以将其进行业务上的分析:C5 可能是一个极低消费但极高满意度的客户,这在统计上是不符合常理的(可能是数据录入错误,或者是薅羊毛用户),因此被识别为异常。
总结:
- K-means 流程: “分配 -> 更新 -> 分配 -> 更新”,直到不动为止。
- 异常检测逻辑: 这里的异常不是指“离原点远”,而是指“离所属簇的中心远”。
Task 4: 隐变量模型 —— EM 算法
在数据挖掘中,我们观察到的叫“观测变量”(比如:考试成绩、购买记录)。很多现实数据的生成机制里,存在一些你没观测到、但确实在影响结果的因素,例如:一门课的成绩分布可能来自两类学生群体(基础好/基础弱),但你并不知道具体的每个学生属于哪类;或一段时间序列的当前状态(健康/故障、冷/热)是隐藏的,但你只观测到传感器读数。
这些“看不见的因素”就是 隐变量 (Latent Variable)。
具体而言,我们通过一个例子来了解:
想象这样一个场景:你是一个老师,你手里有一叠试卷,包含 A、B、C、D 四个等级。你想统计每种等级的 概率分布(比如得 A 的概率是多少,得 B 的是多少…)。 通常情况下,这很简单:数一下 A 多少张,B 多少张,除以总数就行了。这种计算方法在概率与统计中称为 最大似然估计 (Maximum Likelihood Estimation, MLE)。
如果,每个等级的数量都知道了,每一个概率分布都可以直接计算。但是,现在出了个问题,助教把试卷搞乱了。
他明确分出了 C 等级和 D 等级的卷子。但是,他把 A 等级和 B 等级的卷子混在了一个袋子里,统称为 “High grades” ()。你只知道袋子里一共有 20 张卷子,但你看不见每一张具体是 A 还是 B。
你的任务是找出 B 等级的概率(我们称为 )。但是很容易发现,缺少了关键的数据后,会进入死循环:
- 如果我想算出 :我就得知道袋子里具体有几张 B(记为 )。
- 如果我想知道袋子里有几张 B ():我就得先知道 B 出现的概率(也就是 ),然后按照比例去猜。
这样因为缺少了关键的隐变量而陷入死循环的问题模型我们称为 隐变量模型 (Latent Variable Model)。
EM 算法 (Expectation-Maximization Algorithm) 提供了解决隐变量模型的思路:既然解不开,那就先猜一个!
- 先随便猜一个 (比如猜 )。
- E-Step (填空):基于这个猜测的 ,估算袋子里大概有多少张 B。
- M-Step (更新):把你估算的 B 的数量当成“真实数据”,重新计算最合理的 。
- 循环:用新的 再去估算 B 的数量,重复上述步骤直到结果不再变化。
对于上面这样的问题,我们建模如下:
- 观测数据 (Observed Data): 我们确实看到的, (混合的高分), , 。
- 隐变量 (Latent Data): 我们看不到的细节, (A的数量), (B的数量)。
- 参数 (Parameters): 控制概率分布的变量,这里是 ,初始化时 。
在每次 值更新后,我们固定参数 不变,根据当前的概率比例,把 个混合样本“按比例分配”给 A 和 B。即计算其内部的期望值:
接下来,我们假设 E-step 算出来的 是真实的,使用最大似然估计 MLE 去反推参数 等于多少时,能让这个结果出现的概率最大。
现在我们带着这套逻辑回到下面的题目中。下面的部分在考试中将会被要求解答。
考试成绩分 A, B, C, D 四档。
- 观测数据 (Observed Data): 人得了 “High grades” (A 或 B 都在这里,但我们不知道具体几个 A 几个 B)。
- 人得了 C。
- 人得了 D。
- 总人数 。
成绩分布符合某种概率(下面给出的是散点的情况,连续的情况可能是某些常见的概率密度函数):
- (固定)
- (未知,待求解)
注:所有概率加起来
Step 1E-Step: 期望步 (Expectation) —— “填补缺失数据”
假设当前的 是真的,那么 这个混合堆里,应该有多少个 B?
A 和 B 的总权重是 。
因此,在 一个 “High grade”样本中,它是 B 的概率(条件概率)是:
对于所有的 “High grade” 样本,其中 B 的数量为:
是使用第 次迭代得到的 估算出的 B 的数量,从 0 开始。
Step 2M-Step: 最大化步 (Maximization) —— “更新规则”
假设刚才估算出来的 就是真实数据,最有可能 (最大) 的 应该是多少?
这需要用到最大似然估计 (MLE)。首先是构造最大化似然函数 ,数据的似然函数 (Likelihood ) 是 所有观测次数的乘积:
代表的是“观测到这组数据的所有组合方式”。如果总共有 次实验(),那么: 。它的组成中 不包含
以上是离散数据分布的情况,如果是连续的概率分布,假设你有一组观测值 ,它们服从参数为 的分布 。如果这些数据是独立同分布的(IID),那么它们的联合概率(似然函数)就是:
要求最有可能的 ,即对 求偏导。可以发现因为其表达式通常携带次方不便于计算,为了好计算,我们取对数 (Log-Likelihood):
对 求偏导并使其等于 0 可以得到:
于是我们就可以得到了 M-Step 的递推公式:
表示迭代的次数,从 1 开始。这样就可以开始迭代了。
Step 3循环迭代
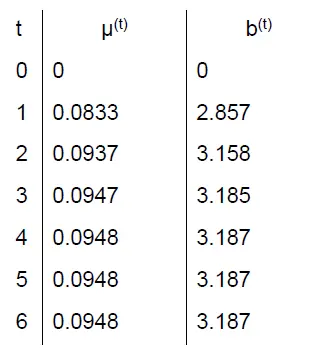
初始条件下,,题目给定初始猜测 。
-
第 1 轮迭代 (Iteration 1)
- E-Step (算 B 的数量):
这意味着,既然 B 的概率是 0,那这 20 个高分肯定全是 A。
- M-Step (更新 ): 现在的“完整数据”是:。代入公式:
-
第 2 轮迭代 (Iteration 2)
- E-Step (算 B 的数量): 现在用新的 。A 的权重 ,B 的权重 。B 在 High grade 中的占比 = 。
概率更新了,我们推测这 20 个人里大概有 2.857 个人其实是 B。
- M-Step (更新 ): 现在的“完整数据”是:。代入公式:
-
第 3 轮迭代 (Iteration 3)
- E-Step: 。
B 的数量在进一步增加,逐渐趋近真实数量。
- M-Step:
-
第 4 轮迭代 (Iteration 4)
- E-Step: 。
- M-Step:
-
第 5 轮迭代 (Iteration 5)
- E-Step: 。
- M-Step:
你会发现 的变化越来越小,当变化小于某个极其微小的值时,算法停止。我们可以将这个过程的数据汇聚为一张表为:
总结与练习
在这里对以上四个经典任务的解题过程与核心思路进行总结。
Task 1Task 1: 文档相似度分析 (TF-IDF & Cosine Similarity):将非结构化的“文本”转化为计算机可计算的“数值向量”。
解题过程:
- 预处理 (Pre-processing): 根据停用词表清洗数据,只保留有意义的关键词。
- 词频统计 (Term Frequency): 统计关键词在当前文档中的出现频率。。
- 加权计算 (IDF): 惩罚常见词,奖励稀有词。。
- 向量化 (Vectorization):计算生成 TF-IDF 矩阵。每一行是一个文档的特征向量。
- 相似度计算 (Cosine Similarity): 使用余弦相似度公式 计算文档间的夹角。值越接近 1,内容越相似。
不要只看词出现的次数,要看词的信息量(IDF)。相似度本质上是看两个向量在多维空间中方向是否一致,而不是看它们的长短。
Task 2Task 2: 最小哈希 (MinHash):大规模二进制数据的快速降维与近似。
这是一种“以小见大”的概率算法。通过多次随机置换抓取特征,我们将庞大的高维稀疏向量压缩成了极短的签名向量,虽然牺牲了一点精度,但换取了极高的计算效率。
解题过程:
- 数据转换:忽略词频,将文档转化为 0/1 的二进制向量 (One-hot)。
- 置换 (Permutation): 随机打乱列(关键词)的顺序。你需要根据置换向量 的指示,去改变检查的次序。
- 签名生成 (Signature): 在新的顺序下,找到第一个 “1” 出现的位置索引。这个索引就是签名值。
- 相似度估算: 比较两个文档的签名向量。签名相同的比例 真实的 Jaccard 相似度 (交集/并集)。
Task 3Task 3: 聚类与异常检测 (Clustering & Anomaly Detection):发现数据的自然分组,并基于分组识别离群点。
解题过程:
- 分配 (Assignment):计算每个样本点到现有中心点的欧几里得距离,将其归入最近的簇。
- 更新 (Update): 计算簇内所有点的均值 (Mean),以此作为新的中心点。这一步旨在最小化均方误差 (MSE)。
- 迭代 (Iterate): 重复上述两步,直到中心点不再移动(收敛)。
- 异常检测:计算每个点到其所属簇中心的距离。计算距离的均值和标准差。设定阈值 (如 Mean + 1.5 StdDev)。距离超过阈值的点即为异常。
K-means 是通过不断调整中心点来让簇内差异最小化。而异常是相对的——不是看你离原点有多远,而是看你离你的“组织”(簇中心)有多远。
Task 4Task 4: 潜变量模型 (EM Algorithm):在数据缺失的情况下,通过“猜测-验证”循环来估计参数。
当变量互相依赖无法直接求解时,先猜一个,然后用数据修正它。这是一个从“不确定”走向“确定”的收敛过程。
解题过程:
- 初始化:给未知参数 一个初始猜测值 (如 0)。
- E-Step (期望): 假设 是真的,利用条件概率公式 ,把混合数据 “软分配”给隐变量 。
- M-Step (最大化): 假设估算的 是真的,利用最大似然估计公式求偏导,得出 的迭代式,重新计算最优的 。
- 迭代: 反复执行 E-M 步骤,直到 值不再显著变化(收敛)。
下面是基于例题的对于上述四种任务的一些练习,用于巩固这些知识。
(Task 1) 有 3 篇文档,我们已经去除了停用词,并确定了 5 个关键词的词汇表:,给出已经统计好的词频:
- D1: “AI model train AI” (4 words)
- D2: “data model code” (3 words)
- D3: “AI train code” (3 words)
任务:
- 计算 IDF: 计算词汇表中所有 5 个词的 IDF 值(使用 ,注意这里为了计算方便,我们统一用以 10 为底的对数,考试时请看清题目要求是 还是 )。
- 构建 TF-IDF 矩阵: 计算 D1 和 D3 的 TF-IDF 特征向量 (使用词袋模型,Bag-of-Words model)。
- 计算相似度: 计算 D1 和 D3 之间的余弦相似度 (Cosine Similarity)。
(提示:。,)
-
IDF 计算 (, base 10)
- AI: 出现在 D1, D3
- data: 出现在 D2
- model: 出现在 D1, D2
- train: 出现在 D1, D3
- code: 出现在 D2, D3
-
TF-IDF 向量构建:
- D1 Vector (AI:2, model:1, train:1, others:0 / Total: 4),所以 , ,
于是对于每一个词,带入 TF-IDF 公式中可以得到:
- AI:
- data:
- model:
- train:
- code:
D1 的向量矩阵为:
- D3 Vector (AI:1, train:1, code:1 / Total: 3),所以 。
对于每一个词,带入 TF-IDF 公式中可以得到:
- AI:
- data:
- model:
- train:
- code:
D3 的向量矩阵为:
-
余弦相似度计算:根据公式,我们需要计算两个向量相乘及其模长。
- 点积 (Dot Product): (这里的计算忽略了相乘为 0 的结果)
- 模长 (Magnitude):
- 带入公式计算相似度可以得到:
(Task 2) 有两个文档的二进制向量,长度为 8 (对应 8 个特征)。,。
任务:利用以下 3 个随机置换 (Permutations) 计算签名矩阵,并估算相似度。
- 构造 D1 和 D2 的 签名向量(每个向量包含 3 个签名值)。
- 计算 MinHash 估算的相似度。
- 计算 真实的 Jaccard 相似度,并 比较误差。
签名向量其实是经过随机置换后找到的第一个 “1” 的位置的向量,我们对两个文档应用三个随机置换向量:
-
- 应用 ,第 1 次检查检查原向量的第 2 个位置,发现是 1,找到签名为 .
- 应用 ,第 1 次检查检查原向量的第 5 个位置,发现是 0 继续;第 2 次检查检查原向量的第 1 个位置,发现是 0 继续;第 3 次检查检查原向量的第 8,发现是 1,找到签名为 .
- 应用 ,第 1 次检查检查原向量的第 8 个位置,发现是 1,找到签名为 . 所以签名向量
-
- 应用 ,第 1 次检查检查原向量的第 2 个位置,发现是 0 继续;第 2 次检查检查原向量的第 4 个位置,发现是 0 继续;第 3 次检查检查原向量的第 6 个位置,发现是 1,找到签名为 .
- 应用 ,第 1 次检查检查原向量的第 5 个位置,发现是 1,找到签名为 .
- 应用 ,第 1 次检查检查原向量的第 8 个位置,发现是 0 继续;第 2 次检查检查原向量的第 7 个位置,发现是 0 继续;第 3 次检查检查原向量的第 6 个位置,发现是 1,找到签名为 . 所以签名向量
接下来需要计算其估算的相似度,使用两个文档的签名向量。注意:这里的相似度是 每一位是否相同 的比较,而不是余弦相似度。比较 和 。
- Pos 1:
- Pos 2:
- Pos 3:
最后,我们需要计算真实的 Jaccard 相似度和误差,Jaccard 相似度为
,。
所以:
- 交集:,共 个。
- 并集:,共 个。
误差就是它们之间的差的绝对值:
这可以说明,当哈希函数数量较少时,MinHash 的波动可能很大。
(Task 3) 一家电商平台收集了 5 位用户的行为数据,包含两个特征(均为 0-10 分):
- : 价格敏感度 (Price Sensitivity)
- : 购买频率 (Purchase Frequency) 数据如下表所示:
用户 X1 (价格) X2 (频率) A 2.0 2.0 B 2.0 4.0 C 10.0 8.0 D 10.0 10.0 E 10.0 2.0 任务: 我们使用 K-means 算法 () 进行聚类。初始中心点 (Initial Centroids):
- Cluster 1 中心:
- Cluster 2 中心:
请完成以下计算步骤:
- 第一次迭代 (分配): 计算各点到初始中心点的欧几里得距离,并将每个用户分配给最近的簇。
- 第一次迭代 (更新): 根据分配结果,计算新的簇中心坐标。
- 异常检测: 计算每个点到其 所属新簇中心 的距离。计算这些距离的 均值 (Mean) 和 标准差 (Std Dev)。并使用阈值公式 ,判断是否存在异常用户?
第一次迭代:距离计算与分配
我们需要计算每个点 到初始中心 和 的距离 。
- 用户 A (2, 2):
- 到 : 0
- 到 :
- 分配: Cluster 1
- 用户 B (2, 4):
- 到 :
- 到 :
- 分配: Cluster 1
- 用户 C (10, 8):
- 到 :
- 到 : 0
- 分配: Cluster 2
- 用户 D (10, 10):
- 到 :
- 到 :
- 分配: Cluster 2
- 用户 E (10, 2):
- 到 :
- 到 :
- 分配: Cluster 2
初始的分配结果:
- Cluster 1: {A, B}
- Cluster 2: {C, D, E}
更新中心点 (Recalculate Centroids):新中心点坐标为簇内所有点的坐标平均值。
- New Cluster 1 Centroid:
- 新中心
- New Cluster 2 Centroid:
- 新中心
在接下来的步骤中,将重复上述的分配和更新的过程,直到 分配没有改变 为止。
计算簇内距离 (Intra-cluster Distances):计算每个点到它新中心的距离。
- Cluster 1 (中心: 2.0, 3.0):
- A (2, 2):
- B (2, 4):
- Cluster 2 (中心: 10.0, 6.67):
- C (10, 8):
- D (10, 10):
- E (10, 2):
距离集合:
均值 (Mean):
标准差 (Std Dev): (先算方差 Variance = 每个距离与均值的差的平方和 / N)
- Sum of Squares
- Variance =
- Std Dev =
判定异常:根据阈值公式:
然后对每个用户进行比较,发现用户 E 的距离为 ,用户 E 是 异常点 (Anomaly)。
(Task 4) 假设我们在研究某种植物的基因型。基因型分为四种:AA, AB, BB, O。 由于检测技术的限制,我们无法区分 AA 和 AB,它们在检测中都会显示为 “Type A”。其他两种可以明确区分。我们收集了 个样本:
观测数据 (Observed Data):
- Type A (): 43 个 (包含 AA 和 AB,混合不可见)
- Type B (): 10 个 (对应基因型 BB)
- Type O (): 47 个 (对应基因型 O)
概率模型 (Probability Model): 我们将概率设为基于一个未知参数 的函数
- (固定,已知)
- (未知,潜变量)
任务: 通过 EM 算法 估算未知参数 ,输出一个迭代的表格。初始猜测
根据 EM 算法,我们在迭代前需要推导出针对当前模型的递推公式。
E-Step:使用当前的 去估算其中 AB 的数量 。
带入数据可以得到E-Step 公式:
M-Step:假设推测出的 是真实的,结合 (Type B) 和 (Type O) 来最大化似然函数。根据其最大值更新
似然函数:
去对数以方便求导:
对 求偏导,并求极值:
所以,M-Step 公式:
现在我们从 开始,执行迭代。
下面是计算得到的表格:
| 轮次 (Iteration) | 当前 | E-Step: 估算 (AB的数量) | M-Step: 更新 |
|---|---|---|---|
| Start (0) | 0.0000 | - | |
| 1 | 0.0000 | ||
| 2 | 0.0585 | ||
| 3 | 0.0863 | ||
| 4 | 0.0954 | ||
| 5 | 0.0980 |
结语
从 Task 1 到 Task 4,是从 显性计算 走向 隐性推断 的过程:
- 我们从最直观的 文本计数 (TF-IDF) 开始;
- 进阶到处理海量数据的概率压缩 (MinHash);
- 再到寻找数据内在结构的几何划分 (K-means);
- 最后攻克了抽象的缺失数据参数估计 (EM)。
本章涵盖了数据挖掘中“特征提取、相似度计算、无监督学习、概率图模型”四大支柱,适合作为数据挖掘的入门。
