

前言
WARNING本章存在大量 LaTeX 公式渲染,可能存在一些浏览器加载卡顿或卡死。建议使用新的内核访问。
这段时间学习了密码学和信息安全相关内容,这一部分有些理论还是有些抽象,我会按照我自己的理解来记录。个人笔记记录,可能会存在些许错漏,如有错误欢迎评论。
笔记将遵循教科书:《密码学原理与实践》第三版,点此进入豆瓣介绍页。
NOTE教材信息:
数学基础
带余除法
从小学数学开始,老师教过我们带余数的除法,例如 。它的正式定义如下:
对于任意整数 和正整数 ,存在唯一的整数 (商)和 (余数),使得:
这里要求 余数必须是非负的,且必须小于除数。数学上可以有负余数,但在计算机和密码学标准里,我们通常要求 。
所以根据这个原理, 因为余数是非负的,所以 ,余数是 , 而不是 。面对负数 取余数的情况,我们可以直接加除数 的 倍,直到为正数,剩余的部分即为余数,即 。
因为 ,可能会出现余数相同的情况,例如 , 。于是我们定义:
如果在除以同一个数 时,两个整数 和 的余数相同,则称 与 模 同余,记作:
例如:
- ✓ (都余 2)
- ✓ (都余 2)
- ✓ (100÷7=14 余 2)
例如 ,我们可以将其写回带余除法的形式:
- 它们只是商不同,除数 和余数 都相同。那我们看看 的形式:
我们可以发现,余数已经消失了,所以可以得到同余的一个推论:
如果在除以同一个数 时,两个整数 和 的余数相同,则 能整除它们的差,记作:
对于除数 ,我们按照除 的余数对被除数 进行分类。因为 ,所以按照余数分类可以分成 种类型,我们把每一种分类称为一个 剩余类 (Residue Classes)。它的正式定义如下:
对于正整数 ,所有除以 余数相同的整数构成一个 剩余类。余数为 的剩余类记作: 或
为什么我们还要折腾这些余数呢?我想一个合理的解释是计算机的存储是有限的。如果不取模,数字不断相乘会变得巨大无比,撑爆内存。通过取模,无论怎么算,结果永远在 到 之间。
此外,密码学需要把原来的信息(明文)弄得面目全非(密文)。模运算是一种很好的“搅拌机”。它很难逆向推导(比如我知道余数是 3,除数是 5,但我不知道原来的数是 3 还是 13 还是 10008)。这种 不可逆性(在某些条件下)是公钥密码学(如 RSA)的基础。
我们前面推导减法规则:,那如果是加法和乘法呢?我们尝试进行推理:
同理,可以得到乘法: 。
群、环、域
我们重新回顾数学中的基础概念:
- 集合 (Set):一堆数字(或其他元素)的合集。例如:整数集合 。
- 运算 (Operation):一种处理元素的方法。例如:加法 () 或乘法 ()。
我们现在要重新定义一个集合中的运算及其遵守的规则。以 整数集合和加法运算 为例,定义如下的规则:
- 封闭性 (Closure):整数加整数还是整数,即对于任意的 ,有 。
- 结合律 (Associativity):对于任意的 ,有 。
- 逆元 (Inverse):对于任意的 ,存在一个 加法逆元 ,使得 , 是 加法单位元。
当满足了如上的加法运算规则后,我们就称其为 加法群 (Additive Group)。我们的整数集合 正好满足这些要求。我们把满足一个运算的应有规则的集合 称为 群 (Group)。
当然,回顾小学数学,我们知道加法有三大规则:交换律、结合率和分配率。如果一个整数加法群 满足交换律,即对于任意的 ,有 ,则称这个群为 阿贝尔群 (Abelian Group) 或交换群。
同理,我们在整数集合上定义乘法及其规则:
- 封闭性 (Closure):整数乘整数还是整数,即对于任意的 ,有 。
- 结合律 (Associativity):对于任意的 ,有 。
- 交换律 (Commutative),即对于任意的 ,有 。
整数集合在满足乘法的这些要求上,还能满足加法与乘法之间的分配率,即对于任意的 ,有 。
此时你发现,怎么乘法的规则里面没有逆元这一条。因为整数之间的除法不一定能得到整数,可能会出现分数。
整数集合 同时满足了加法的 4 条规则和乘法的 2 条规则, 以及加法和乘法的分配率。我们称一个集合 同时满足 两个运算 的规则时,它是一个 环 (Rings)。所以,整数集合 是一个整数环。
在 上,你可以随意加减乘,得到的还是整数。但是你不能随意除(比如 不是整数)。
注意,此时整数集合在乘法上,并不是群,因为其不满足一定有逆元在整数域中。
当一个集合,在 加法 上是一个群,去掉 元素后,它在 乘法 上也是一个群(意味着每个非零元素都有倒数),则称为 域 (Field)。
此时乘法也满足了群的特征,即其逆元也在集合中。例如我们最常见的 实数域 ,或 有理数域 。
我们在电脑里做加密,不能用无限的实数,必须用 有限 的整数。但是普通的整数集合 只是环,不能除。我们需要构造一个 既是有限的,又能做除法 的系统。这就是 有限域 (Finitefield) 或伽罗瓦域(Galoisfield),通常记作 或 。
例如我们之前学到的 模 7 的剩余类 , 它的集合是 。在这个集合里,每个非零数字都有逆元 ,使得 。
例如:,, 所以 是 的逆元。同理我们一个个尝试,可以得到 中每一个非零数字的逆元,且在 中。所以它是一个 域。
但是,并非所有的模剩余类都是域,例如 模 12 的剩余类 。尝试找 2 的乘法逆元,会发现在 中无法找到。
一般而言,模 的剩余类的集合 中,当 为质数 (素数) 时, 是伽罗瓦域。具体证明比较繁杂,在计算机课程中就不涉及了。
总的来说,我将群、环、域总结为一张表以供参考:
| 结构 | 包含运算 | 逆元情况 | 典型例子 |
|---|---|---|---|
| 群 (Group) | 1种 (如 ) | 可以减 | 时钟算法, 椭圆曲线点集 |
| 环 (Ring) | 2种 () | 可以减, 不一定能除 | 整数 , 多项式 |
| 域 (Field) | 2种 () | 可以减, 可以除 | 实数 , 有限域 |
古典密码体系
在这一章节中,将简单介绍几个的古典密码体系,用于了解密码的发展。这一章中,一个密码系统必须满足:, 表示加密方法, 则是解密方法。
移位密码
因为英文有 26 个字母,我们将每一个字母都看作 中的元素,例如: A -> 0, B -> 1, ..., Z ->25。 是一个环,里面的元素满足加法和乘法的结果均属于这个环,且加法存在逆元。加法、减法、乘法都要 mod 26 以保证其在 中。
移位密码 (Shift Cipher) 运用了环的特性,在 的基础上,将每个字母整体平移 位后得到密文,具体来说定义为:
Shift Cipher设明文空间 、密文空间 和密钥空间 均为 。对于 ,任意 ,定义:
当 时,这个密码就是凯撒密码 (Caesar Cipher)。接下来通过一个例子去演示这个过程:
设移位密码的密钥为 ,明文为:
wewillmeetatmidnight,使用移位密码去加密它。
- 首先我们将明文按照字母表转为数字序列:22, 4, 22, 8…
- 然后将每个数都与 11 相加,再对其和取模 26 运算:例如 ,对应字母 H。
- 经过全部转换,我们得到密文:
HPHTWWXPPELEXTOYTRSE
如果需要解密时,每个密文字母转成数字后减 11 即可。
移位密码的安全性非常有限,因为其密钥空间仅有 26 个可能的取值,攻击者 Oscar 可以穷举所有 值,直到出现有意义的英文。
代换密码
另一个比较有名的古典密码体制是 代换密码(Substitution Cipher)。代换密码不再使用固定的移位,而是用一个完全随机的密码本替换字母表。
Substitution Cipher在替换密码中,明文空间和密文空间 。密钥空间 是由 26 个元素的所有可能排列(Permutations)构成的集合 。对于任意 ,定义:
表示置换 的逆置换。
例如有如下置换规则 :
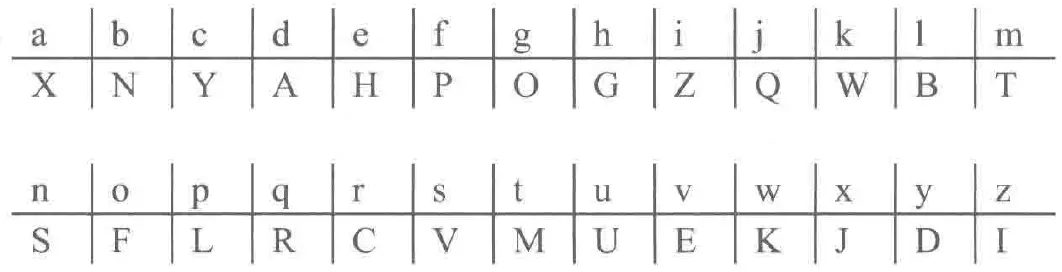
通过这种随机映射,明文中的每一个字母都被替换成密钥表中对应的另一个字母。解密函数是其相应的逆置换。
代换密码的密钥空间极大(),暴力破解难以奏效。那代换密码就安全了吗,显然不是。它依然无法掩盖自然语言的统计特性。攻击者可以通过频率分析法,统计密文中各个字母出现的概率并与标准英文频率对比,从而快速推断出替换规则并破解密文。
仿射密码
从前面我们看到,移位密码是代换密码的一种特殊情形,其只包含了 26 种置换情况。另一个代换密码的特殊情形是 仿射密码(Affine Cipher)。它的置换规则由一个线性方程决定。
Affine Cipher设 ,若有密钥 ,其中 是明文字母对应的数字,则定义:
- 加密函数为:
- 解密函数为:
如果密码能被解密,加密函数必须一一对应,否则两个明文字母可能加密成同一个密文字母,解密时就不知道还原成哪一个。即 必须是一个单射函数(指向唯一值),它与 同余:。分析这个仿射函数的解密,只要 ,则 。所以是否能解密主要专注于 是否有乘法逆元 。对于 ,若存在 ,使得 ,则 称为 在 上的乘法逆元,记作:.
有逆元的 唯一条件 是: 必须与 互素,即最大公约数 。例如 ,。此时加密字母 a (对应数字为 0) 和 n (对应数字为 13) 时:
两个不同字母映射到了同一个结果,这导致了加密不可逆。所以仿射密码有解的充分必要条件是:。那么 该如何取值使得其与 互素呢?下面是严谨一些的数学推导:
欧拉函数 (Euler’s totient function) 表示 里,有多少个数和 互素,即 . 例如在 中,,分别是:。接下来我们分类讨论 的不同情况:
- 如果 本身就是一个素数,那么除了它自己外, 全部和它互素。。例如 ,因为 7 是素数,除了它自己,前面的 1, 2, 3, 4, 5, 6 全部和它互素, .
- 如果 是一个素数的次方,例如 ,你会发现 除了那些包含因子 的数外 的数均与 互素。例如:。只有那些包含因子 3 的数和 27 不互素,也就是 3 的倍数:3, 6, 9, 12, 15, 18, 21, 24, 27。因为每 个数里面就有一个 的倍数,所以非互素的数量是:. 例子中则是 个。那么与 互素的数就可以计算为:.
- 现实情况中, 往往很复杂。我们学过一个重要的数学定理:任何一个整数都可以拆分成几个素数的乘积,这称为 质因数分解 (Prime Factorization)。这里简单复习一下,我们一般使用短除法来解决。例如 , 遵循如下的短除法算法对其进行质因数分解:
先从 2 开始试,依次尝试每一个素数因子,直到最后的商为 1。最后我们可以得到这样的素数组合:. 所以我们可以将 表示为,def prime_factors(n):factors = {}i = 2while i * i <= n:while n % i == 0:factors[i] = factors.get(i, 0) + 1n = n // ii += 1if n > 1:factors[n] = 1return factors接下来我们计算与 互素的数的个数,即 。根据上述第二点的结论,与 不互素的只有组成 的各个素数因子的倍数。因为这些素数是完全独立的,只需要把每个独立的 值乘起来就组成了 的 值。我们举一个例子来理解一般情况下的欧拉公式:例如 ,与 互素的数有 个。
回到仿射密码。对于英文字母表 ,其质因数分解为 ,与它互素的数,即使得仿射密码有解的 的值有 个。
拓展到任意的 ,对于仿射函数 , 有 种选择(因为其只是平移量,符合 的加法性质), 有 种选择。则 仿射密码的密钥空间 的大小为:。
在解密仿射密码时,需要知道 的乘法逆元 ,乘法逆元可以通过 拓展欧几里得算法 (Extended Euclidean Algorithm, EEA) 求得,在后续例子之后补充。在 下,乘法逆元如下:
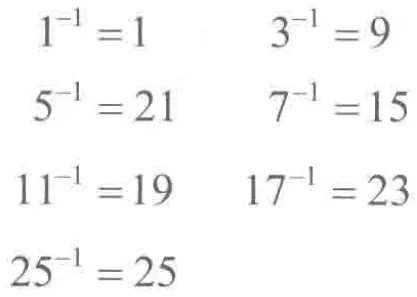
下面是一个仿射密码解密的例子:
假设仿射密码的密钥为 ,已知 。加密函数为:,解密密文:
AXG。
我们先将其转换为数字:,使用解密函数:, 代入密文可以得到:
- ,还原为
h; - ,还原为
o; - ,还原为
t。
通过上述步骤,密文 AXG 成功解密为明文 hot。
补充:计算乘法逆元的方法 扩展欧几里得算法 (Extended Euclidean Algorithm, EEA)。在模运算里,求 7 在模 26 下的乘法逆元,就是要找一个数 ,使得:,也就是对于整数 ,存在 。
先使用欧几里得算法 (辗转相除法) 计算 :反复用大数除以小数,取余数,直到余数为 0。以 为例:
| 步骤 | 运算 | 余数 |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 最后一个非零余数是 ,所以我们可以得出 26 和 7 的最大公约数 。 |
接下来,我们可以通过逆推上述步骤,找到整数 和 ,使得 :
| 步骤 | 运算 | 余数表达式 |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 |
现在我们要把 写成 和 的组合。
- 从第 3 步开始:,移项得到:,接着将第 2 步中得到的余数表达式代入此式:,展开得到:,观察到之前的步骤中存在余数 , 我们整理为带有上一步骤余数的形式:。
- 接着继续将第 1 步的余数表达式 代入:,展开得到:,合并保留 和 的组合:。
- 现在对等式两边模 :因为 , ,所以 。这说明 是 在 下的乘法逆元,写作 。但是乘法逆元需要 , 所以 。
维吉尼亚密码
在前面介绍的移位密码和代换密码中,一旦密钥被选定,则每个字母对应的数字都被加密变换成对应的唯一数字,这种密码体制我们一般称为单表代换密码。维吉尼亚密码 (Vigenère Cipher) 是一种多表替换密码 (Polyalphabetic cryptosystem),同一个明文字母在不同位置会被加密成不同的密文字母,从而抵抗简单的词频分析。
维吉尼亚密码 主要使用了一个维度为 的密钥向量,这个密钥是一组基于位置的密码表,让每个字母的移位不再和字母本身锁定,而是会随着位置的改变而改变。它的定义如下:
Vigenère Cipher对于正整数 ,定义 。对于任意以 维度向量表示的密钥 ,定义:
- 加密函数:
- 解密函数:
实际上维吉尼亚密码算是移位密码的拓展,接下来通过一个简单的例子来展示维吉尼亚密码的过程。
设 ,密钥字为
CIPHER,其对应于如下的数字串 。加密:thiscryptosystemisnotsecure
首先我们将明文串转化为对应的数字。 是一个维度为 的向量,它表示这套密码有 6 个不同的移动规则。我们将明文按 个字符进行分组得到:
thiscryptosystemisnotsecure:这一组不满 6 个就保留即可。
对于每一组中,第 个字母的偏移量为 。例如 thiscr 这一组中,第 个字母 t 的偏移量为 ,第 个字母 h 的偏移量为 ,依此类推。然后在下一组中重复。于是对于 thiscr 这一组,我们应用密钥 可以得到如下的表格:
| 步骤 | 第1位 | 第2位 | 第3位 | 第4位 | 第5位 | 第6位 |
|---|---|---|---|---|---|---|
| 1. 明文字母 | t | h | i | s | c | r |
| 2. 明文数字 (P) | 19 | 7 | 8 | 18 | 2 | 17 |
| 3. 密钥字母 | C | I | P | H | E | R |
| 4. 密钥数字 (K) | 2 | 8 | 15 | 7 | 4 | 17 |
| 5. 相加 (P+K) | 21 | 15 | 23 | 25 | 6 | 34 |
| 6. 取模 (mod 26) | 21 | 15 | 23 | 25 | 6 | 8 |
| 7. 密文字母 (C) | V | P | X | Z | G | I |
加密后 thiscr 变成了 VPXZGI。 |
解密同理,只需要将密钥的移位量减去即可,下面的表格记录了如何将 VPXZGI 解密回 thiscr 的过程:
| 步骤 | 第1位 | 第2位 | 第3位 | 第4位 | 第5位 | 第6位 |
|---|---|---|---|---|---|---|
| 1. 密文字母 | V | P | X | Z | G | I |
| 2. 密文数字 (C) | 21 | 15 | 23 | 25 | 6 | 8 |
| 3. 密钥字母 | C | I | P | H | E | R |
| 4. 密钥数字 (K) | 2 | 8 | 15 | 7 | 4 | 17 |
| 5. 相减 (C - K) | 19 | 7 | 8 | 18 | 2 | -9 |
| 6. 调整取模 (mod 26) | 19 | 7 | 8 | 18 | 2 | 17 |
| 7. 还原明文字母 (P) | t | h | i | s | c | r |
维吉尼亚密码的密钥空间大小为 。维吉尼亚密码比移位密码更难手工破解,但如果用于加解密的密钥 重复使用,就会产生周期性结构。只要猜出密钥长度 ,维吉尼亚密码就退化为 个独立的移位密码。
希尔密码
在维吉尼亚密码中,我们使用多表替换,同一个字母可能会变成不同的字母。但它的缺点也很明显,它是逐个字母加密的,如果破解者能猜出密钥的长度(比如长度是 6),他们就可以把密文分成 6 组,每组单独使用词频分析法来破解。
为了解决这个问题,希尔密码 (Hill Cipher) 采用了分组加密的思想。它利用线性代数中的矩阵乘法,将 个明文字母组成的向量同时进行变换。由于加密过程涉及到多个字母的线性组合,这使得密文不仅取决于当前的明文字母,还取决于与其同组的其他字母,从而更有效地抵御频率分析。
简单来说:希尔密码把几个字母打包成一个向量,然后用矩阵把它们混合起来。
Hill Cipher设 是正整数,定义 ,,, 为密文向量。对于任意的密钥矩阵 则定义:
接下来同样通过一个例子去解析这个过程。
设一次性处理 个字母,密钥 , ,需要加密的明文为
july。使用希尔密码进行加密。
根据 的值将明文分为两组,并将其转换为一组向量:
ju:ly:
接下来我们使用密钥矩阵对明文进行加密,在 ju 这一组中,让明文向量乘密钥矩阵(矩阵乘法,第一行乘第一列,第二行乘第二列):
然后将其放回 中,即 。得到 ,转换回字母得到 DE。
同理可以对第二组 ly 进行加密:
计算 , 。最终,明文 july 被成功加密成了密文 DELW。
既然加密是乘以矩阵 ,那解密自然就是乘以 的逆矩阵 ()。刚才例子中,以及给出了 。通过将密文转换的向量与逆矩阵相乘再取模就可以恢复明文了。例如解密 DE:
所以密文向量是:,相乘:。再模上 26 可以得到 ,转回字母可以解出 。
我们学习线性代数知道,不是所有的矩阵都有逆。 可逆是完成解密的必要条件,即 。 是密钥矩阵 的行列式,,其中 是代数余子式(删掉第 行第 列后剩余矩阵的行列式,它的符号由行列决定,为 )。下面是一个简单的例子:
如果我们按行展开:
求逆还需要伴随矩阵 ,它是所有代数余子式组成的矩阵再转置。例如对上述的 矩阵,第一步:计算每个位置的代数余子式 得到:
| 位置 | 删行删列后的子矩阵 | |||
|---|---|---|---|---|
| 24 | ||||
| 5 | ||||
| -4 | ||||
| -6 | ||||
| 9 | ||||
| 1 | ||||
| -7 | ||||
| -10 | ||||
| 8 | ||||
| 第二步:组成代数余子式矩阵 |
第三步:转置 → 得到伴随矩阵
有了行列式 和伴随矩阵 后,我们可以通过如下公式求逆:
在希尔密码中,矩阵的逆通常是在模 的情况下求出来的。有一个定理:当行列式与 不互素时,矩阵在模 下没有逆矩阵。例如刚才的例子中,, , 所以这个例子在 下存在逆矩阵。
所以 在 下,,而 . 根据我们之前提到的扩展欧几里得法,可以计算出 。所以 的逆是:
置换密码
在我们之前学习的密码中,它们都有一个共同点:核心逻辑是通过特定的映射规则将明文字符替换为另一个字符,从而改变字符的取值。如果你截获了一段密文,你可以笃定里面的字母都不是它原本的意思。
而 置换密码(Permutation Cipher) 反其道而行。它又称换位密码,其核心思想是 保持明文字符集不变,通过 改变字符在序列中的位置 来达到加密目的。与代换密码不同,它不改变字符本身的取值,仅对其进行重新排列。
置换密码首先将密码进行分组(类似希尔密码的分组),每 个字母切成一小块。在每一组中,规定一个固定的位置置换顺序。我们有如下置换密码的定义:
Permutation Cipher设 是一个正整数,定义 。密钥 是由定义在集合集合 上的一组置换组成。
- 加密函数:
- 解密函数: 其中 是 的逆置换。
置换密码实际上是希尔密码的一种特殊情况。如果希尔密码中的密钥矩阵 是一个 置换矩阵(即矩阵的每一行和每一列有且只有一个 ,其余元素均为 ),那么该希尔密码就等价于置换密码。
接下来通过一个例子来演示加密和解密过程。
设 ,密钥置换 定义为: 这意味着:第 1 位换成原先的第 3 位,第 2 位换成原先的第 5 位,以此类推。需要加密的明文为:
shesellsseashellsbytheseashore。
将明文按 分组,得到 shesel,lsseas,hellsb,ythese,ashore。
加密第一组 shesel:明文向量为 。接下来根据 进行位置映射:
| 密文位置 | 置换位置 | 置换后 |
|---|---|---|
| 1 | e | |
| 2 | e | |
| 3 | s | |
| 4 | l | |
| 5 | s | |
| 6 | h | |
所以:shesel → EESLSH。字母还是 s、h、e、s、e、l 这些字母,只是顺序变了。 |
解密过程需要用到逆置换 。根据 的定义,我们可以推导出 :
- 因为 ,所以
- 因为 ,所以
- 因为 ,所以
- 因为 ,所以
- 因为 ,所以
- 因为 ,所以
整理得到逆置换:
使用 对密文 EESLSH 进行解密即移动位置,即可还原回 shesel。
分组密码与高级加密标准
介绍分组密码之前,可以简单给加密算法进行分类。根据密钥的使用方式,加密算法可分为两大类:
- 对称加密 (Symmetric Encryption):加密和解密用的是同一串密钥。
- 非对称加密 (Asymmetric Cipher):加密与解密使用不同的密钥。
对称加密因其速度快、适合处理大量数据而广泛用于数据传输,但其只能保障数据的机密性;而非对称加密虽然速度慢,但可以同时保障数据的机密性、身份认证和不可否认性。
分组密码 (Block Ciphers) 是一种经典的 对称加密 (Symmetric Encryption) 算法。其基本原理是将明文数据按照固定长度的分组进行加密。
替换—置换网络
替换—置换网络 (Substitution-Permutation Network, SPN) 可以想象为我们之前学习的替换密码和置换密码的组合网络。它的核心思想很简单:一次简单操作不够安全,那就把 替换 和 位置置换 反复做很多轮。
它由两个重要组件组成:
- S盒(S-box, Substitution,代换/混淆):类似替换密码,通过替换改变数据的值。它的目的是打断明文和密文之间的直接联系,让关系混淆。
- P盒(P-box, Permutation,置换/扩散): 通过位置置换,改变数据的位置。它的目的是让明文中一个比特的影响迅速扩散到整个密文中。
如果只有 S 盒和 P 盒,如果这些规则是公开的,那么任何人都能照着做加密和解密。所以在 SPN 中,每一轮执行 S 和 P 操作时,都需要加入一个 轮密钥 (Round Key)。与每轮都使用同样的密钥不同,轮密钥使用密钥编排算法生成一组密钥编排方案 。在每一轮中,将与上一轮 P 盒的结果进行 异或 (XOR) 计算 以混合加密数据。解密时,混合模块不需要重新设计。只要拿出同一把轮密钥再做一次 XOR,数据就还原了。
SPN 的定义如下:
Substitution-Permutation Network, SPN设明文和密文都是长度为 的二进制向量 (),存在 S-box ,和 P-box 。密钥 由初始密钥 K 用密钥编排算法生成的所有可能的密钥编排方案的集合,对一个密钥编排方案 ,使用如下的过程加密明文 。
其中, 表示每个 S-box 处理多少 bit, 表示每轮有多少个 S-box, 则表示整个明文分块的大小。
在每轮中,有如下符号:
- : 表示第 轮结束后的状态。初始化时为 ,初始值为明文 的明文分块形式。
- :表示第 轮的轮密钥。
- : 是第 轮 S-box 的输入,它由上一轮的状态和轮密钥异或计算得到。
- :表示第 轮 S-box 的输出。
- :表示第 轮经过 P-box 重新排列后输出的状态。
假设我们要循环 次(称为 轮,Round):
- 初始化:把明文加入算法 ()。
- 前 轮循环:
- 密钥混合:把当前状态和这一轮的轮密钥进行 XOR ()。
- 替换:把数据切成小块,分别送进 S-box 进行替换 ()。
- 位置置换:把 S-box 的输出,按 P-box 的规则打乱位置 ()。
- 最后一轮 (第 轮) 的特殊处理:
- 密钥混合:把倒数第二轮的状态和最后一轮的轮密钥进行 XOR ()。
- 替换:把数据切成小块,分别送进 S-box 进行替换 ()。
- 不进行替换,再次进行密钥混合:。这是为了让加密和解密的电路是对称的,最后再加一次密钥,是为了防止破解者轻易剥离掉最后一轮的 S-box。这种首尾都加密钥的设计叫白化 (Whitening)。
算法的伪代码如图:

接下来通过一个例子来解析这个过程。
给出如下的 SPN 设置:设 ,S-box 的输入 与其输出 都是使用十六进制表示。
S-box (十六进制对照): 类似一个字典。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| E | 4 | D | 1 | 2 | F | B | 8 | 3 | A | 6 | C | 5 | 9 | 0 | 7 |
P-box: 表示输出 的第 位,取输入 的第 位。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 9 | 13 | 2 | 6 | 10 | 14 | 3 | 7 | 11 | 15 | 4 | 8 | 12 | 16 |
密钥 ,通过一些编排算法后得到如下的轮密钥:
明文是 。接下来我们开始这个流程:
- 初始化:
- 第 轮:
- 密钥混合:已知 ,将其与 逐位异或可以得到 。
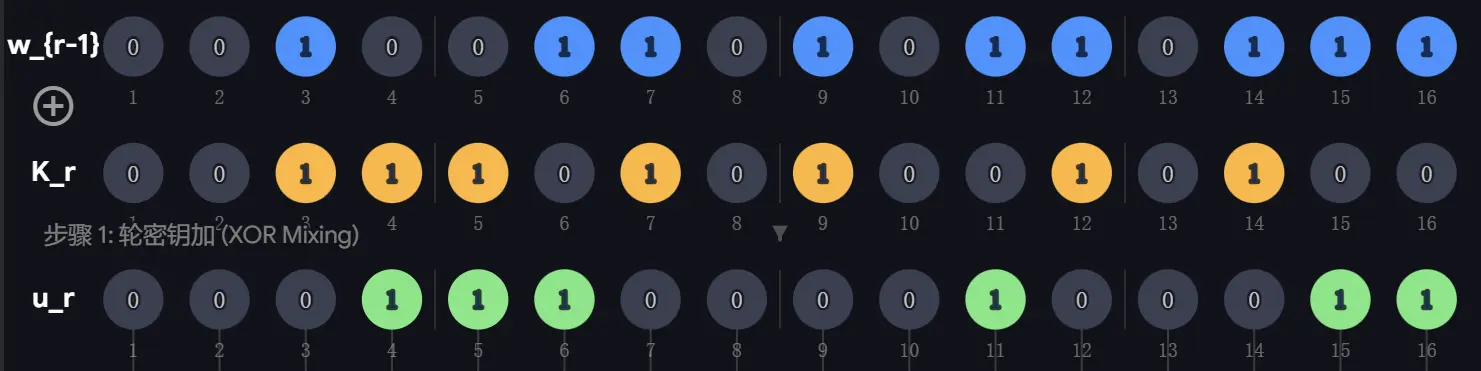
- 替换:把 分成 组,每组刚好四个 bit,将其转换会十六进制,对每组查表替换:,
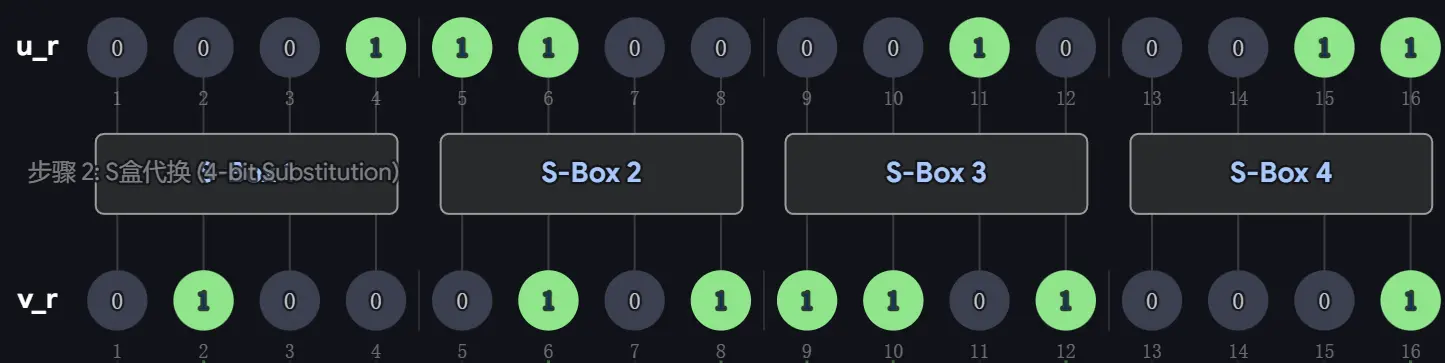
- 位置置换:应用 P-box 规则,例如 的第 位是 的第 位,第 位是 的第 位…
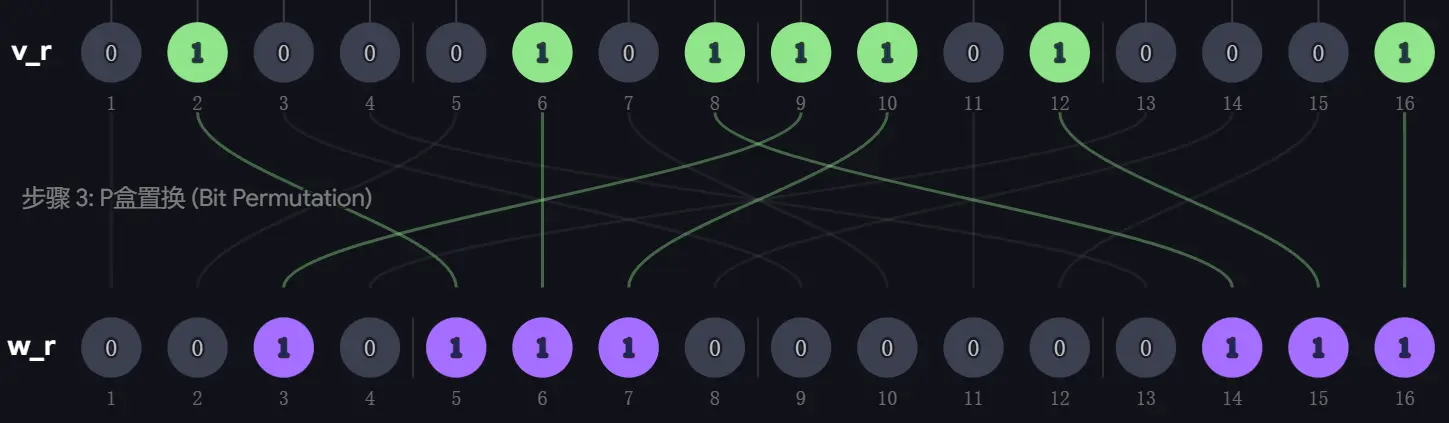
- 密钥混合:已知 ,将其与 逐位异或可以得到 。
- 接下来是第 2 ~ 3 轮,过程类似。
- 在第 4 轮中,
- 密钥混合: , ,
- S-box 替换:
- 白化:再次进行一轮密钥混合,, ,所以 ,将其转换为十六进制是
过程对照表如下:
| 阶段 | 值 |
|---|---|
| 0010 0110 1011 0111 | |
| 0011 1010 1001 0100 | |
| 0001 1100 0010 0011 | |
| 0100 0101 1101 0001 | |
| 0010 1110 0000 0111 | |
| 1010 1001 0100 1101 | |
| 1000 0111 0100 1010 | |
| 0011 1000 0010 0110 | |
| 0100 0001 1011 1000 | |
| 1001 0100 1101 0110 | |
| 1101 0101 0110 1110 | |
| 1001 1111 1011 0000 | |
| 1110 0100 0110 1110 | |
| 0100 1101 0110 0011 | |
| 1010 1001 0000 1101 | |
| 0110 1010 1110 1001 | |
| 1101 0110 0011 1111 | |
| 1011 1100 1101 0110 |
DES
在刚才学习的 SPN 网络中,有一个隐藏的问题:为了能让密文解密还原回明文,我们在 SPN 里使用的 S-box 必须是可逆的。然而在数学上,设计一个高安全度且可逆的 S-box 很困难。为了解决这个问题,密码学家提出了 Feistel 结构,并设计了 DES (Data Encryption Standard)。在这种结构中,每一轮的轮函数 (S-box) 并不要求是可逆的,因为其解密过程是通过 结构自身的对称性 来实现的。这使得 S 盒的设计更加灵活,可以使用更复杂的非线性映射来增强安全性,而无需担心解密时的可逆性限制。
Feistel 结构的基本原理是将输入的明文平分成左右两部分。具体而言:
- 每一轮把当前状态分成两半:, 表示左半边, 表示右半边。对于第 轮而言,它的输入是 。
- 在第 轮中:
- 将右半边的 复制一份,直接等于下一轮的左半边:
- 将右半边的 和当前这一轮的轮密钥 一起加入一个搅拌函数 中得到一个加密数据:。
- 最后将这个加密数据与原本的左半边 进行 异或 () 运算,得到的结果成为了下一轮的右半边:
下图展示了 Feistel 结构的基础架构:
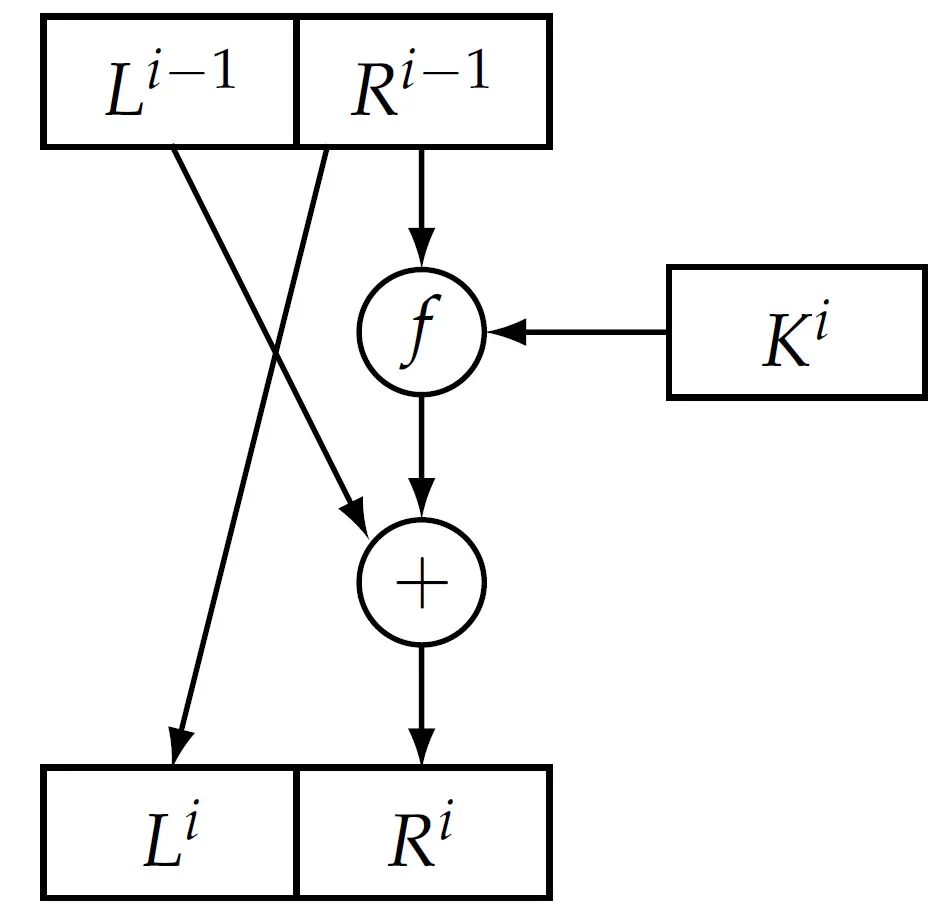
这个结构同时也是 DES 加密过程中的一轮。DES 是一个 16 轮的 Feistel 网络,处理 64 比特 的数据块,用一个 56 比特 的密钥(另有 8 比特奇偶校验,实际存储 64 比特)。
DES 的大致流程是:
- 先对明文 做一个固定的 初始置换 IP (Initial Permutation),记为
- 经过如上的 16 轮 Feistel 结构加密,得到 ,将其 交换顺序 得到:。
- 将交换顺序后的密文做一个固定的 逆置换 ,得到最后加密的密文 ,即 。
其中初始置换及其逆置换没有密码学意义,仅是为了适应当时的硬件设计。
那 DES 的设计为什么能解决要求轮函数可逆的问题呢?它运用了异或运算的数学性质:一个数据被同一个值异或两次,就会回到原值 。
假设你拿到了第 轮结束后的密文结果 :
- 就是上一轮的 ,所以可以得到
- 当你知道当前这一轮的密钥 时,你同时也知道上一轮的右半边 ,你可以代入加密函数重构它的值 。
- 接下来就可以通过异或的性质得到上一轮的左半边 :
在 DES 中,我们 根本不需要去逆向破解 函数。只需要重新运行它一次,利用异或运算的还原能力,就能把数据完美还原。DES 的加密和解密算法是完全相同的,解密时只需将相同的输入跑一遍,并把子密钥的调度顺序反过来即可。
你可能会好奇它的加密函数 内的样子,和 SPN 类似吗?下图展示了其加密函数的架构。
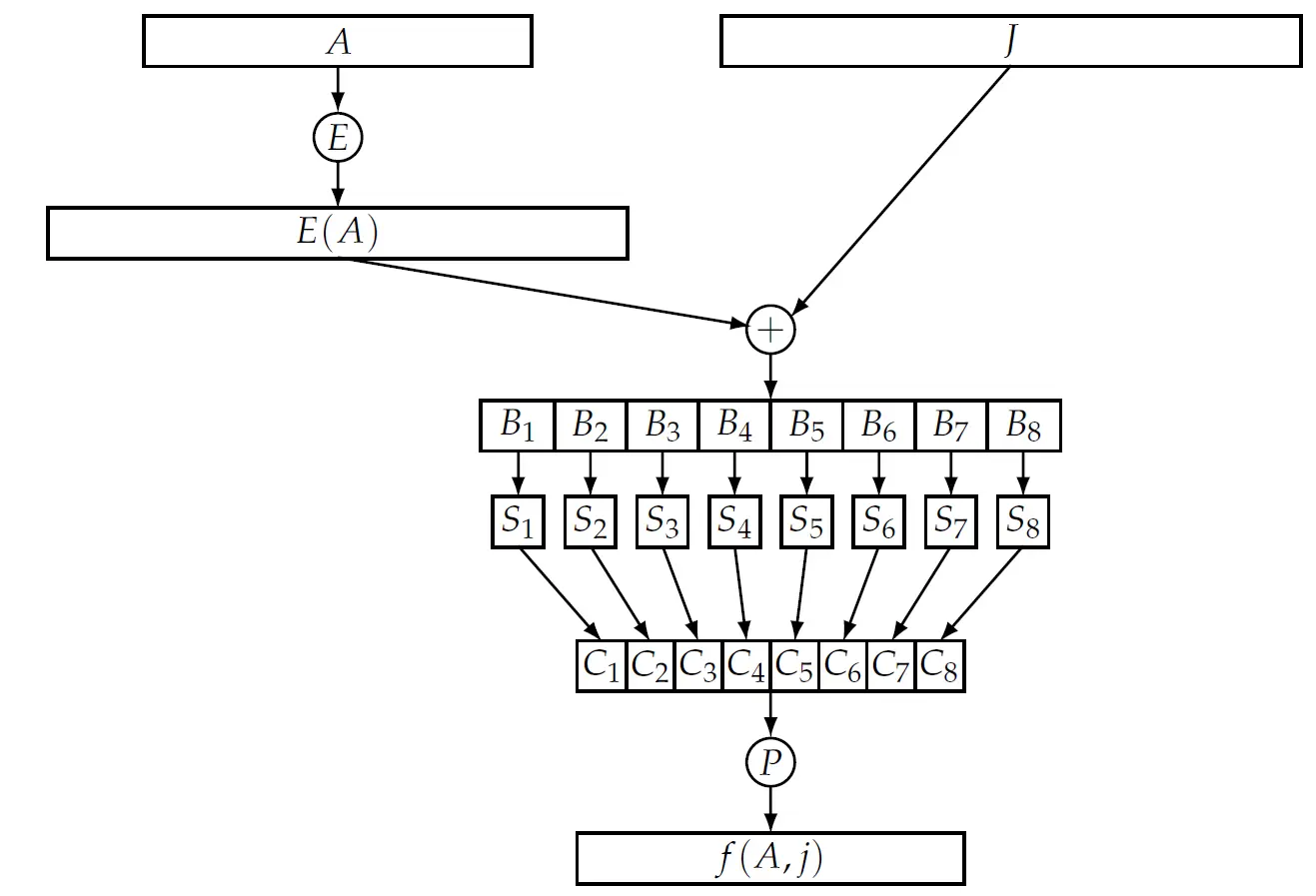
DES 函数的输入是:,它包含 32 位的右半边和 48 位的轮密钥,最后产生一个 32 位的结果。
- 在其中, 函数使用扩展函数 重新排列 32 位的右半边输入,并将其中的 16 位复制一遍,扩展成 48 位拉伸后的数据 ;
- 将其与轮密钥逐位异或:,并将运算结果分成 8 个小组( 到 ),每组包含 6 个比特。
- 将这 8 个组分别送入 8 个不同的 S 盒( 到 ),经过查表替换,每个 S 盒得到 4 个比特:.
- 将其输出拼在一起得到 32 位的 ,然后送进置换函数 中进行置换。置换后输出的 ,就是 函数的最终产物。
AES
DES 为了避开设计可逆 S 盒的难题,使用了 Feistel 结构,代价是 每轮只能加密一半的数据。密码学家利用高级的数学工具(有限域/伽罗瓦域)制造出了 SPN 中的完美可逆 S 盒。AES (Advanced Encryption Standard) 抛弃了 Feistel 结构,全面回归了 SPN 结构。这使得 AES 每轮能把所有数据都加密一遍,效率提高。
AES 中,标准的数据块是 128 bits。它不再把这 128 bits 看作一条序列,而是把它切成 16 个 Byte(1 byte = 8 bits),然后转换成一个 4 x 4 的矩阵。这个矩阵在 AES 中被称为 状态矩阵 (State),其表达式如下(Byte 按 列顺序 摆出)。
AES 会根据不同的密钥长度定义不同的轮数,一般来说 AES-128 是 10 轮,AES-192 是 12 轮,AES-256 是 14 轮。
在 轮中,都包含如下四步:
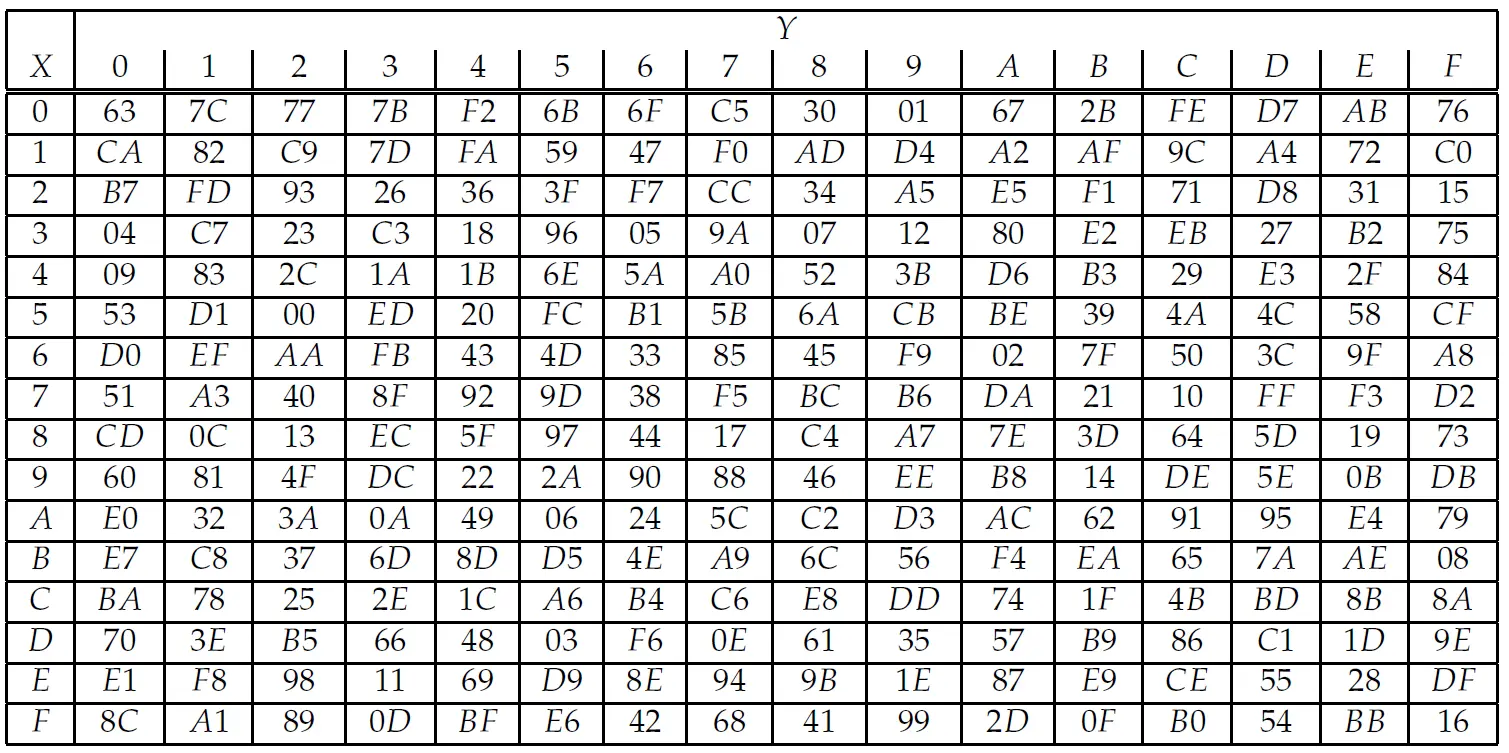
- 字节代换 (SubBytes):将状态矩阵通过一个 16 x 16 的固定 S 盒,每个 byte 通过 S-box 替换。如图是一个 S 表的例子。
- 行移位 (ShiftRows):它会将每一行循环左移不同距离,相当于行置换。第 行整体向左移动 格。例如第 0 行移动 0 格(不变),第 1 行经过上一步后的输出为:,经过 ShiftRows 向左移动 1 格后变为:。
- 列混淆 (MixColumns):将每一列内部混合。它每次处理矩阵的一列。它把这 4 个字节当作多项式的系数,去乘以一个固定的矩阵。经过极度复杂的运算后,输出全新的 4 个字节。
- 轮密钥加 (AddRoundKey):最后,把这一轮的 128 位轮密钥也拆分为字节,排成一个 4x4 的矩阵,跟我们刚才搅拌好的状态矩阵进行简单的 异或 () 运算。
而 第 轮时则没有 MixColumns 这个操作。
AES 的轮密钥是通过 密钥拓展 (Key Expansion) 生成的,这一过程将初始密钥按 字 (Word) (1 Word = 4 Bytes) 扩展为一个更大的密钥序列,确保每一轮迭代都使用唯一的子密钥。例如 AES-128 需要将 128 位的初始密钥扩展为 11 组轮密钥,128 位的密钥对应 16 个 Byte,即 4 Words。Key Expansion 会生成 个 Word,每轮 AddRoundKey 使用其中 4 个 Word。
Hash 函数
Hash 函数和 MAC
之前学习的加密算法都在尝试各种方法将一段信息加密为其他人看不懂的内容,在现实世界中,只有机密性是不够的。其他人就算看不懂密文,但他如果把密文拦截下来,随便篡改几个字节都会导致你解密失败。或者是黑客假冒你的身份发了一条指令,这时解密者不知道是否是你发的。
这时候我们就需要解决两个新问题:
- 完整性 (Integrity):数据在传输过程中,有没有被改动过。
- 认证 (Authentication):这数据是否是你本人发出来的。
一个很简单的方法就是:添加指纹 (fingerprint)。
哈希函数 (Hash Function) 是一种给信息添加指纹的方法。它的输入可以是任意长度的消息(一个文件、一句话、一部电影),输出则是固定长度的无规律字符串,也就是数字指纹,也被称为 消息摘要 (message digest)。比如常见的 MD5 或 SHA-256 就是 Hash 算法。这个指纹是公开可计算的,任何人拿到消息,都能通过同样的 Hash 函数算出一样的指纹。Hash 函数具有如下的特性:
- 不可逆:无法通过 Hash 值推导出原信息是什么。
- 雪崩效应 (Avalanche Effect):信息发生任何的改动都会导致 Hash 值的变化。
- 抗碰稳固:很难找到两份内容不同但 Hash 值却一样的文件。
一个非常常见的 Hash 函数的应用就是 软件完整性验证:官网发布软件时,同时公布它的 Hash 值。个人下载软件后自己算一遍 Hash 值,对比官网的值,就知道文件有没有被篡改或损坏。
Hash 算法是没有密钥的,每个人都可以算。而在此基础上,消息认证码 (MAC) 则是加上了一个密钥。MAC 的计算不仅依赖于文件内容,还依赖于一个 只有通信双方才知道的秘密密钥 ()。黑客就算篡改了文件,想重新算一个合法的 MAC,但他 没有密钥,所以算不出来。
Hash 函数解决了数据有没有变的问题,而 MAC 更进一步,不仅解决了数据有没有变,还提供了密钥认证,以确定计算者的身份,保证数据是你发的。
Merkle-Damgård 结构
我们知道,哈希函数具有输入为任意长度的信息,输出为固定长度的信息摘要的特点。这样的特性是怎么设计的呢?在密码学里,数学家们非常擅长使用 压缩函数 (Compression Function,通常记为 ),它只可以接受固定长度的输入,并输出固定长度的信息。密码学家设计了一种 Merkle-Damgård (MD) 结构,将压缩函数 扩展成一个 可以处理任意长消息 的 Hash 函数。
MD 结构的核心思想是:用一个只能处理固定长度输入的压缩函数 ,反复处理长消息 的每一块;每一轮的输出变成下一轮的状态,最后一个状态就是 hash 值。这样的过程类似于递归求解。
首先我们设定一个碰撞稳固的压缩函数:,它的输入是 bits,输出是 bits。这个 也是多轮递归处理时的状态长度(因为上一轮的输出一定是 ),同时最后生成的 Hash 值也是长度为 的消息摘要。 表示除了状态以外还能吃进去的额外空间相关参数。我们用 记录整体输入信息的长度。
我们需要构造这样的 Hash 函数:,其中 是足够长的有限比特字符串的集合。现在问题是:真实的输入 可能很长,而压缩函数只能处理固定长度 bits。所以 MD 结构设计了这样的链式结构:
初始状态 → 吃第 1 块 → 新状态新状态 → 吃第 2 块 → 新状态新状态 → 吃第 3 块 → 新状态...最终状态 = hash 消息摘要在第 轮可以写作:, 表示第 轮后的状态; 表示第 个信息块, 表示拼接。我们可以把每一轮的状态 理解为前 个消息块共同留下来的 累计指纹,因为我们不是分块单独压缩,而是基于前面的分块再加上当前分块的链式压缩。所以每一轮压缩函数都必须带上上一次的状态 ,这也类似于递归中的值的传递。每一轮的压缩本质上是把前面的内容压缩成一个固定长度状态。
那我们已经知道,第 轮压缩后的状态 是 位的。而下一轮的压缩函数只能输入 位,直觉上第 轮可以吃 t 位的信息块,但实际上还需要在上一轮状态和这一轮的信息块之间 加入 1 bit 的固定标记 。这是为了防止 内部碰撞,即如果攻击者能找到某个状态与消息块的组合碰撞,他就可以在两个长度不同的消息间制造相同的哈希值。
所以 信息块的长度 应该设置为:. 那么根据这个长度,我们可以将初始的输入 分为长度为 的若干块,所需要的块数是:。此时得到:
因此,可能会存在最后一个块 的长度小于 bits. 例如每块长度是 bits,消息长度是 bits,那么:,最后一块 . 遇到这种情况的时候,我们一般会给它后面补 个 , 。
此外,我们 还要额外记录补 0 的个数 ,用 来表示 的二进制。如果只补 0,不记录补了几个 0,会产生歧义。如果刚好有其他的信息二进制与补 0 后的信息相同,那么它们的 hash 值也会相同,这就存在碰撞。
算法的过程如下:
Algorithm 5.6: MERKLE-DAMGARD(x)
external compresscomment: compress : {0,1}^{m+t} -> {0,1}^m, where t >= 2
n <- |x| // 原始的长度k <- ceil(n / (t - 1)) // 分块的数量d <- k(t - 1) - n // 需要补 0 的个数
for i <- 1 to k - 1: // 遍历 k-1 个分块,用 y 表示每个分块,长度都是 t-1 bits y_i <- x_i // x_i 是消息 x 已经切好的分块,在 k-1 时直接赋值
y_k <- x_k || 0^d // 给最后一块 x_k 补 0,让它变成 t-1 bitsy_{k+1} <- binary representation of d // 记录补 0 的数量,用于消除编码歧义
z_1 <- 0^{m+1} || y_1 // 补充初始状态和标志位,均为 0g_1 <- compress(z_1) // 进行第一次压缩,得到第 1 轮的状态
for i <- 1 to k: // 循环压缩,直到压缩完所有分块 z_{i+1} <- g_i || 1 || y_{i+1} // 补充输入 g_{i+1} <- compress(z_{i+1}) // 压缩第 i+1 轮
h(x) <- g_{k+1} // 包含处理最后的 y_k+1return h(x)- MD 结构首先将输入的 按固定大小切块,得到 。设长度块 为 MD 算法中用到的信息块,在 块内,;在第 块中,可能需要进行补 0;同时再用一个 来表示补 0 的个数。现在原消息 被变成了一串 信息块:,每一个的长度都是 bits。
- 我们使用 表示第 轮应该输入给压缩函数的输入,根据我们之前的分析,它应该包含
上一轮的状态 | 分隔标志位 | 信息块。在初始情况下, 没有上一轮的状态,理论上也不需要标志位,所以需要在前面补 个 0: 。在之后的第 轮的输入中,,就需要加上上一轮的状态和分隔标志位 了。 - 循环处理压缩,直到压缩完所有分块。
我们这个算法的设计是有逻辑链的,如下描述可以帮助理解:
- : 长消息太长 → 必须切块
- : 最后一块可能不满 → 右侧补 0
- : 只补 0 会有歧义 → 额外记录补了几个 0
- 压缩一次只能吃一个固定长度输入 → 必须多轮处理
- 每轮要记住前面处理结果 → 用 作为链式状态
- 第一轮和后续轮要区分 → 用 0/1 作为结构标记
- 最后一个状态 → 就是 hash 值
MD 结构是 抗冲突的 (collision resistant)。如果两个不同消息 , 最后得到同一个 hash ,这说明 。
- 如果发现 ,那我们就发现了是压缩函数产生了冲突。
- 如果发现 ,那说明上一轮状态和当前块都一样:, 。最后只有可能在某一轮找到了压缩函数的冲突,或者是 值都一样。
- 但如果是所有的 都一样,因为 记录了补 0 的长度,所以可以唯一还原原始 。这就会推出:,这与我们的假设逻辑冲突。
所以,如果能找到 的冲突,那么就能找到压缩函数的冲突;因此压缩函数是抗冲突的,构造出的 hash 函数也抗冲突。
我们刚才处理的情况中,压缩函数除了长度为 的状态外,还能处理多出的 bits 的信息块。但如果在极端情况下,压缩函数只能处理 bits 的输入,此时我们不能将原信息分成 bits 了,因为 . 那么在这种情况下如何将一整条长消息加入压缩函数呢?
此时需要特殊处理,算法如下:
Algorithm 5.7: MERKLE-DAMGARD 2(x)
external compresscomment: compress : {0,1}^{m+1} → {0,1}^m
n ← |x| // 原信息的长度
y ← 11 || f(x1) || f(x2) || ... || f(xn) // 使用编码函数转换原始信息为 y
denote y = y1 || y2 || ... || yk, // 把编码后的 y 看成一串单独的 bit。where yi ∈ {0,1}, 1 ≤ i ≤ k
g1 ← compress(0^m || y1) // 补充初始状态和第 1 个 bit 作为输入
for i ← 1 to k − 1: // 链式压缩 gi+1 ← compress(gi || yi+1)
return gk它的思路是:先把原消息重新编码成 ,然后逐 bit 链式压缩。
- 假设原消息是:,注意这里的每一个 都是 1 bit 的,。
- 它定义了一个 特殊编码函数 。通过这个编码函数,我们将原始消息 转换为一个新的比特串 。我们还需要在 前面加上一个 前缀 , 用来标记编码的开始(因为不存在连续的 1)。例如二进制下 ,,。
- 接下来,把 拆成单个 bit。例如 ,那就可以分成 个 bit。这个 与之前的算法中的 不同。
- 开始压缩,压缩的输入需要由上一轮的状态 和 当前轮的单个 bit 组成。初始状态为 。
既然每轮只能吃 1 bit,那为什么不直接把 逐位吃入进行压缩,而是要使用一个转换后的 呢?这样 不能很好地处理不同长度消息之间的安全证明。假设两个不同长度的消息最终 hash 一样:,和我们之前的分析一样,可能会推出 短消息的 bit 串等于长消息 bit 串的后缀 这样的逻辑矛盾。例如 。我们加入了前缀 后就可以解决这个问题,因为编码主体不存在两个连续的 。如果两个编码长度不同,那么在没有找到压缩函数冲突的情况下,会推出一个编码是另一个编码的后缀,但这产生了逻辑矛盾。
Sponge 结构
海绵结构 (Sponge Construction) 是 Hash 函数设计里的另一条路线。SHA-3 就是基于海绵结构设计的。它不再使用 Merkle-Damgård 那种输出固定长度的压缩函数,而是使用一个 固定长度到固定长度 的函数 ,使得它不仅能 吃进任意长度 的数据,还能 吐出任意长度 的结果。
海绵结构的设计思路是:先把消息一块块吸进去,再从内部状态里挤出需要长度的输出。
海绵结构内部有一个固定大小的内存空间,我们称之为 状态 (State),总长度设为 bits (width)。这 个比特的空间,被划分成了上下两个区域,分别是:
- (bitrate,速率/吞吐量):这是海绵的表层。用于衡量每次能吸收 / 输出多少 bits。 越大,每次吸收越多,速度越快。
- (Capacity,容量/安全区): 这是海绵的深层核心。不直接接触消息和输出,为了在内部把数据搅乱,提供绝对的安全性。 越大,内部隐藏部分越多,安全性越强。
如图,我们知道 。此外,空间中还存在很多个搅拌机 ,负责把 (也就是 )里面的数据彻底打乱融合。
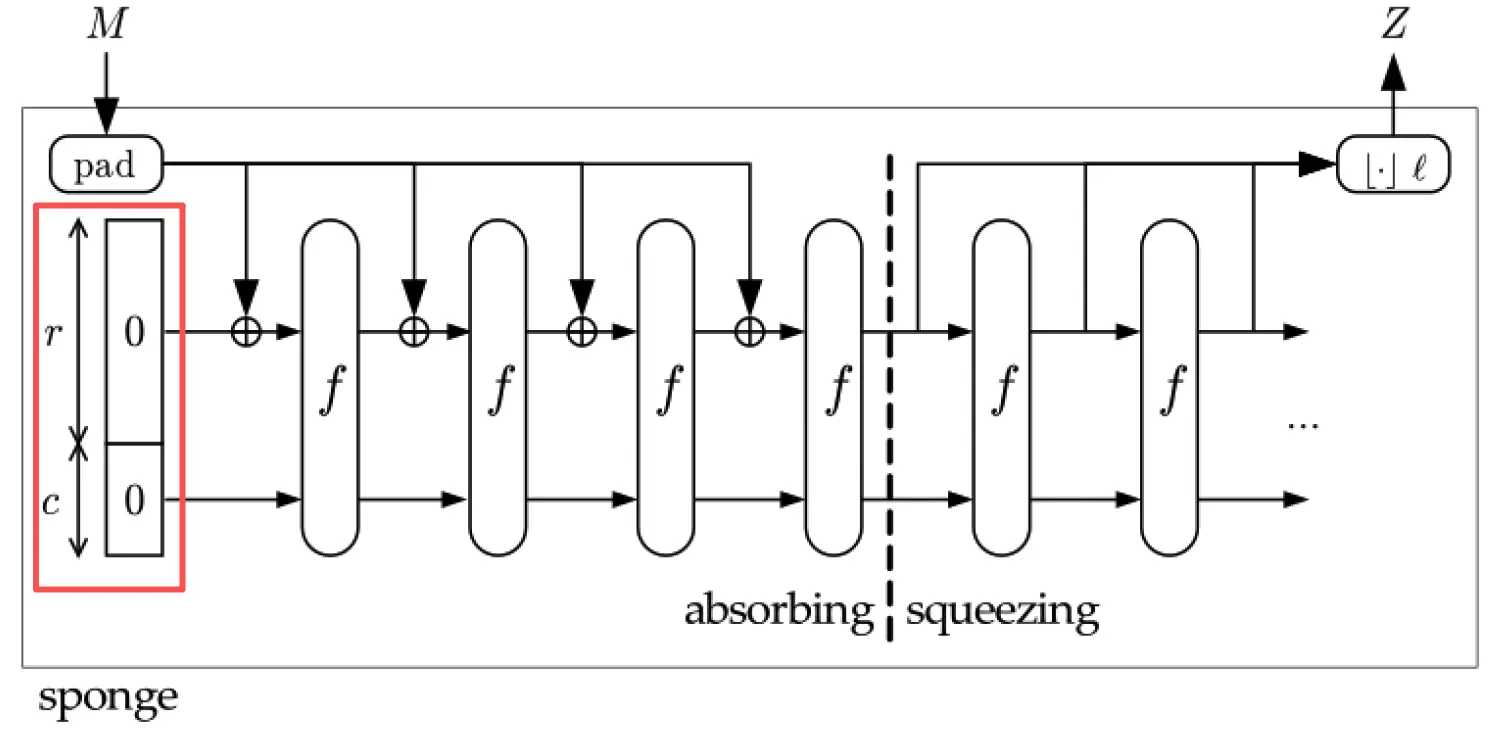
跟着这张图,下面展示海绵结构如何得到 hash 值的过程。首先是 吸收阶段 (Absorbing Phase)。
- 输入消息 :原始消息 先进入 中,将其切成 bits 个分块,得到:,每个 都是 bits。
- 初始化状态:在左侧设置一个初始状态:。
- 吸收第 1 块:第一块 和 state 上半部分 () 进行异或计算:, 然后整个状态进入 中执行搅拌,输出 。
- 吸收后续块:接下来把第 2 个数据块 ,与现在全新的表层 () 异或,再加入 中搅拌得到第 2 轮的状态 。循环往复,直到所有的数据块 到 全部被吸入并搅拌完毕。
接下来是 挤出阶段 (Squeezing Phase)。
- 挤出第 1 次:直接把当前海绵表层 的数据读出来,输出给用户。这就是你的第一段 Hash 值(长度为 )。
- 再次挤出直到结束:如果发现输出不够长,则对当前状态进行内部搅拌 后,再次把变幻后的表层 读出来,拼接到刚才的输出后面,直到挤出的总长度满足你的需求。
最后把挤出的输出块拼起来,只保留前 bits,这就是最终的信息摘要。
下表是两种结构的对比:MD 是把消息压短;Sponge 是把消息吸进一个大状态,再从状态中挤出输出。
| Merkle-Damgård | Sponge | |
|---|---|---|
| 基本组件 | 压缩函数 | 固定长度的搅拌函数 |
| 组件形式 | ||
| 处理消息方式 | 每轮压缩成较短的状态 | 每轮把消息 XOR 进当前状态,再搅拌 |
| 内部状态 | 通常就是最终输出长度附近 | |
| 输出长度 | 通常固定 | 可以任意长度 |
| 典型代表 | SHA-1, SHA-2 类结构 | SHA-3 / Keccak |
RSA
我们之前学的古典密码以及分组密码,都有一个致命的弱点:Alice 和 Bob 必须在通信之前共享一个秘密密钥。但是有一个严重的问题:如何在一个无法保证完全安全的信道中,把这把钥匙安全地交到对方手里?
这种困境促使了 公钥密码学 (Public-key Cryptography) 的诞生。1976 年,Diffie 和 Hellman 提出了公钥加密的思想,而 RSA 算法则是第一个真正意义上实用的公钥加密系统。
RSA (Rivest, Shamir, Adleman, 1977) 使用非对称密钥——公钥 (Public key) 和私钥 (Private key),巧妙地解决了在不安全信道下分发密钥的难题。
RSA 的安全性基于一个“单向函数”的 数学陷阱:将两个大的素数相乘在计算上是非常容易的,但要将它们的乘积重新分解回原来的因数在计算上是几乎不可能的。
RSA 数学基础
在学习 RSA 之前,再次复习本篇之前提到的一些数学基础:
对于正整数 和正整数 其 最大公约数 GCD (Greatest Common Divisor) 可以通过 欧几里得算法 (Euclidean Algorithm) 计算:。当 时,我们认为 和 是互质 (素) 的,即它们没有共同的因子。
在模数空间中,如果存在 ,我们可以称 是 的 模逆 (Modular Inverse)(即之前仿射密码中提到的乘法逆)当且仅当 . 此时可以写作 。若 在模数空间 存在模逆 , 可以通过 扩展欧几里得算法 (Extended Euclidean Algorithm, EEA) 计算得到。前面的仿射密码处我们已经给出了一个例子。
欧拉函数 (Euler’s totient function) 表示 里,有多少个数和 互素,即 . 根据我们之前在仿射密码中证明的,如果把 通过质因数分解为若干个质数次方的乘积:, 表示一个质数, 表示其次数,那么有欧拉 函数:
特别地,当 且 均为质数(没有次数)时,。例如,,分别是 .
若 互质,即 ,. 有一个数 同时满足这样的同余方程组:
我们可以得到, 在模 下有 唯一解,。这样的推论称为 中国剩余定理 (Chinese Remainder Theorem, CRT)。
证明:对于每个 ,定义 。由于 之间互质,没有任何因子是其他模的因子,所以 与 互质,。所以存在模逆 使得:。我们将其代入第 个方程组中,构造:。已知 同时满足所有方程组的情况,所以在模 下, 需要满足:。此时, 在模数 下有唯一解,因为 是这一群互质的数的最小公倍数。
例如古籍中记载的问题:求 使得 ,,.
我们可以先计算其总模数 ,对每个模,分析其内部贡献,即计算:
| 模 | |||
|---|---|---|---|
| 3 | 35 | → → | 2 |
| 5 | 21 | → → | 1 |
| 7 | 15 | → → | 1 |
代入公式:
欧拉定理 (Euler’s Theorem) 是 RSA 算法的核心。它指出:若正整数 与正整数 互质,则存在 。
证明:我们知道在 中, 个数拥有其乘法逆元(模逆)。例如 ,它们在 的模数空间中里都有乘法逆元,比如 ,3 的逆元是 7,7 的逆元是 3。此时要求: 时, 在 里才是可逆的。
例如在 里,可逆余数是:。如果用 去乘这些可逆余数会得到:, , , . 观察这些同余结果,我们可以发现,所得的结果集 与原集合 在模 10 意义下是完全一致的,只是 元素的顺序发生了改变。这表明 在模 的乘法群中,任何与 互质的数 与所有可逆余数相乘,其结果依然是整个可逆余数集合,只是排列不同。
那么在 中,和 互质的余数是:,一共有 个。我们把这个集合称为一个乘法群 . 因为 与 互质,,所以:我们可以构造一个新的集合 ,它们仍然是这些数的重新排列。所以两边全部相乘,应该同余:.
左边有 个 ,所以:. 因为每个 都和 互质,所以它们的乘积也和 互质,因此这个乘积在可以在 下消掉,得到:
RSA 密码系统
RSA 的密码系统定义如下:
RSA Cryptosystem在 下,设 是两个质数 和 的乘积,定义密钥 。对于明文和密文 ,定义:
- 加密函数
- 解密函数 此时, 和 组成了公钥,, , 组成了私钥。
RSA 生成密钥的过程如下:

接下来,我们将通过一个简单的例子来看看 RSA 加解密的过程。
假设 Bob 生成的密钥:,所以 ,计算:。
如果他选定 ,。那么 需要满足:,通过拓展欧几里得算法,将其转换为余数表达式:, 可以算出 . 所以得到了:
- 公钥:
- 私钥:
Alice 将根据密钥进行加密,假设密文 , 加密后:,Alice 将向 Bob 发送这个密文。
Bob 用私钥指数 进行解密:,应用计算机计算可以得到最终值 .
我们来验证 RSA 的加密和解密过程是可逆的。在一个乘法群 中,如果 和 互质,根据欧拉定理,我们已知 ,.
因为 ,所以存在某个 , 使得 .
设密文 ,当我们将密文解密时:.
将 代入 中得到:
解密成功。
我们发现,在 RSA 过程中最难算的就是幂的模数了,即 和 ,因为 RSA 中取的密钥值通常都非常大。在计算机里一般使用 Square and Multiply 算法去快速计算这样幂的模。
Square and Multiply Algorithm设正整数 , , , ,要计算 ,则应用如下的算法过程:
- 将 转换为二进制的形式:, . 表示二进制的位数(从 0 开始的)。
- 初始化 , 然后从最高位到最低位处理指数的二进制位:. 每次处理做如下两件事:
- 平方 (Square):首先计算 ,并将其赋值给 :.
- 相乘 (Multiply):如果当前二进制位 ,将 与 相乘,否则什么都不做:.
SQUARE-AND-MULTIPLY(x, c, n)
z ← 1
for i ← ℓ - 1 downto 0 do z ← z^2 mod n if c_i = 1 then z ← (z × x) mod n
return z这个算法的时间复杂度是 ,这个算法的正确性证明这里省略,有兴趣可以自行去查看。接下来我们使用之前的例子来跑一遍这个算法的过程:要求
- 先将幂转换为二进制:.
- 初始化 , 应用算法进入循环:
- 第一轮:因为 , 平方后相乘得到:.
- 第二轮:因为 , 平方后相乘得到:, .
- 第三轮:因为 , 只平方:.
- 第四轮:因为 , 平方后相乘得到:, .
- 第五轮:因为 , 平方后相乘得到:, .
经过这个算法,最后可以算出 .
离散对数
离散对数数学基础
我们前面学习的 RSA 的精髓在于“把两个质数乘起来容易,拆开极难”,在接下来的一章中将介绍另一个著名的数学陷阱:离散对数问题 (Discrete Logarithm Problem, DLP)。
离散对数难题 建立在有限循环群 的基础之上,这个群内乘法运算和幂运算在模 的意义下执行,且群的阶 (元素个数) 是有限的。
在循环群 中,我们选一个数 ,不断计算它的幂:. 此时称 是一个 生成元 (generator)。因为循环群的性质, 的幂可以生成模 下的所有非零元素:, () .
这个 称为 以 为底, 的离散对数。它一点也不连续,值在模 的范围内乱跳,所以叫离散对数。如果我们知道了 ,要想反推出 : 在 很大时非常困难。
离散对数问题的这种单向性是许多现代密码体制的安全基石。例如,ElGamal 密码系统。
ElGamal 密码系统
ElGamal 密码系统 是一个建立在有限域上离散对数问题的困难性之上的非对称加密算法。RSA 每次使用同一公钥加密同一明文计算结果都一样,黑客即便解不开密文,但如果他看到你连续三天发送了完全相同的密文,他就能猜到你下达了相同的指令。ElGamal 引入 随机性 (Randomized Encryption),具有概率加密的特性,这意味着 相同的明文在不同时刻加密会产生不同的密文,从而能够更有效地抵御选择明文攻击。
ElGamal 密码系统定义如下:
ElGamal Cryptosystem设 是一个足够大的质数,选定一个生成元 ,在非零元素循环群 中,定义一个密钥:。对 ,选定一个随机数 , 对于明文 和密文 ,定义:
- 加密函数:, 其中 , .
- 解密函数:.
其中,, , 组成公钥, 则是私钥, 是每次随机生成的,不会被传递。
接下来一步步代入这个过程:
- 首先选择一个大质数 ,并选择一个 作为模 下的一个生成元,构建出循环群 。
- Bob 选择一个私钥:,然后计算公钥 :。根据离散对数问题的性质,别人知道 ,但很难从 反推出 。于是得到:公钥:,私钥:。
- Alice 想加密消息 ,他将随机选择一个临时随机数 ,然后计算:, ,得到一组密文: 。这里的 类似 提示纸条,而 则是真正加密的内容。
- Bob 收到密文,他用自己的私钥 计算:, 在之前我们计算了一个公钥 ,根据乘法交换律替换:,我们就解出了真正加密内容 中的重要参数 ,而不需要知道 的值。最后,只需要继续计算逆元 乘回 中,即可计算出明文 :。
下面是一个代入真实数据的例子,为了演示方便,这里选择较小的数据:
设 , ,在 中,选择私钥 。计算公钥中的 :,这样我们得到了公钥和私钥:
- 公钥:
- 私钥:
Alice 想加密消息:,Bob 随机选择:,计算:
- 提示纸条:.
- 加密内容:.
得到密文:.
Bob 解密,她计算 ,根据之前的推理,. 所以代入解密函数中:。根据拓展欧几里得算法,可以计算出在模 下 的逆元 。代入可得:。
在攻击者的视角下,它们只知道公钥 ,而无法得到提示纸条中的遮罩 ,也就无法把 还原成 。
有限域
在最开始的数学基础知识中,我们已经介绍过了群、环、域的基本概念,在这里我们主要来讲讲 有限域 (Finite Fields),又称 伽罗瓦域 (Galoisfield)。有限域是指包含有限个元素的域,通常记作 ,其中 必须是某个质数 的 次幂 。
回顾一下域的概念,简单来说:域是一个集合,在这个集合里,可以做加、减、乘、除,而且 运算结果还留在这个集合里。例如: 是一个域,在模 下因为 是质数,。除 外,所有的其他元素都与 互质,它们都存在模逆(就是所谓的除法)。
根据欧拉函数的性质来看, 是域,当且仅当 是素数。那有限域的大小只能是这些素数组成的空间,例如 。但是密码学里经常需要大小为: 这样的空间,该怎么做呢?我们一般使用 多项式环 模一个不可约的多项式 来构造有限域。
表示 系数来自 的所有多项式。例如 中,系数只能是 0 或 1。考虑变量 的多项式,比如:,它们的系数全是 0 或 1。
以前我们学过整数模运算,例如:,余数是 2。现在多项式也可以做类似的事,例如 ,所有多项式都可以除以 ,得到一个余数:。
因为 的次数是 3,所以余数的次数一定小于 3。也就是说余数形式为:,一共有 种不同的多项式组合。这样就 构建了一个大小为 8 的有限域。
所以我们可以正式定义: 当且仅当 是 不可约多项式 (irreducible) 时,它的余数可以构成一个有限域。不可约多项式 就是多项式世界里的质数:它次数 ,不能分解成两个更低次数的多项式的乘积(系数仍取自 )。例如 我们可以将其进行多项式分解:,它变成了两个更低次数的多项式的乘积,这个多项式不是不可约多项式。
到这里可能有些抽象了,我们对比域在整数空间和多项式空间的定义清晰了:
| 整数世界 | 多项式世界 |
|---|---|
| 模 | 模 |
| 是素数 | 是不可约多项式 |
| 是域 | 是域 |
接下来我们通过一个例子来看构造有限域的过程。
我们的目标是:构造一个有 8 个元素的有限域。因为 8 不是素数,所以不能直接用 , 它不是一个域。所以我们可以借助多项式构造一个域:
一种通常的做法是:在 中找一个次数为 3 的不可约多项式 来构造 。因为系数只能是 0 或 1,所以三次多项式大概长这样:,
如果常数项 ,那么多项式一定可以被 整除。(此时所有的项都包含 ,所以均可约)。我们只需考虑具有常数项为 1 的多项式。我们通过二进制来看,用 分别表示次数为 2, 1, 0 时的系数,有这四种情况:001, 011, 101, 111,它们分别对应下面四个式子:
001:011:101:111:
在 中判断它们是否可约是非常简单的,因为如果 可约,它一定能分解成更低次数的多项式乘积。对于一个 3 次多项式,它要么分解成 一次 × 二次,要么 一次 × 一次 × 一次。无论如何,至少都有一个一次因子。所有可能的一次多项式只有两个:01: 和 11 . 所以我们只需要检查 和 是不是这个多项式的根即可。如果 ,说明 是因子;如果 ,因为 所以 是因子。
- 如果 , . 没找到 为因子。
- 如果 , . 发现 和 具有因子 ,所以它们是可约的。
经过验证,其中 和 是可约的:,.
因此, 和 就是我们要找的不可约多项式。
通过选择其中一个不可约多项式(如 ),我们就可以定义出 中的加法和乘法规则。我们模的是三次多项式,每个元素都可以表示成次数小于 3 的多项式:, 。通过二进制我们可以构造出有限域里的 8 个元素:
000001010011100101110111
在这个域中,我们计算加法时,可以使用二进制逐位计算得到。例如:,它们表示 ,逐位加相当于做 异或计算,得到:,所以多项式加法的结果是:。
在计算乘法的时候,我们可以先像普通多项式一样相乘,然后用 做模约化。例如:计算 。
对应二进制就是 101 乘以 111。我们将其像普通多项式相乘:。因为:,所以 。
这个式子现在要模:,这意味着: (自己模自己为 0),移项得到:,但是对于 中, 减法和加法一样。所以可以得到一个化简规则:。
回到上面的相乘式,我们用 来取代高次项:,所以原式变成:.
我们把化简规则: 带到高次项中,可以计算得到如下:
通过这个序列我们可以看到, 到 的计算结果恰好涵盖了有限域中所有的结果。
在这种构造下,域中的元素既可以表示为系数组成的多项式,也可以对应为二进制位串,这使得有限域运算在计算机硬件和软件中能够以极高的效率实现。
在密码学中,有限域为复杂的代数运算提供了封闭且稳定的数学结构,是实现 AES、ECC 等现代加密算法的核心基础。理解有限域的性质,有助于我们进一步探究非对称加密中更高效的构造方式。
椭圆曲线
椭圆曲线 (Elliptic Curve) 在实数中是一个类似 或水滴状的曲线,它的方程形如:.
但是在密码学里,我们通常不在实数里工作,而是在模素数 的有限世界里工作。也就是 ,
在这种定义下,原本平滑连续的曲线会变成由一系列离散点 组成的集合,再加上一个特殊的无穷远点 (point at infinity) 。它们构成了一个椭圆曲线群。这个 作为群的 单位元(就像加法里的 0)。
这个椭圆曲线的参数 是满足 的常量,用于保证曲线没有尖点或自交叉。
在椭圆曲线 上,我们可以定义一种特殊的“加法”运算。所有运算都在模 下进行。如果有两个点 , ,规定:。
若 ,且 ,则 (无穷远点)。
若 ,则加法的结果是:, 。对于斜率 ,有两种情况:
- 如果 :. 这是 和 两点之间的直线的斜率。
- 如果 :. 这是一条与椭圆曲线 切于 点的直线的斜率。
且定义单位元相加:.
我们来看一个例子:
设 是 上的椭圆曲线,它的点 满足 ,. 这个曲线在这个群里是一堆离散点。
在这个椭圆曲线中有哪些点呢?找点的方法就是 把 一个个代入曲线中,看看算出来的结果是不是一个完全平方数,我们称为二次剩余 (quadratic residue)。
我们先列出模 11 下所有平方值 :
接下来我们将 的各个取值代入方程 ,然后判断是否 。
例如:
- 若 ,代入后得到:。匹配后发现有二次剩余 , ,所以得到两个点: 和 。
- 若 , 代入后得到:。匹配后发现没有二次剩余,所有没有点。
所有的计算结果如下图:
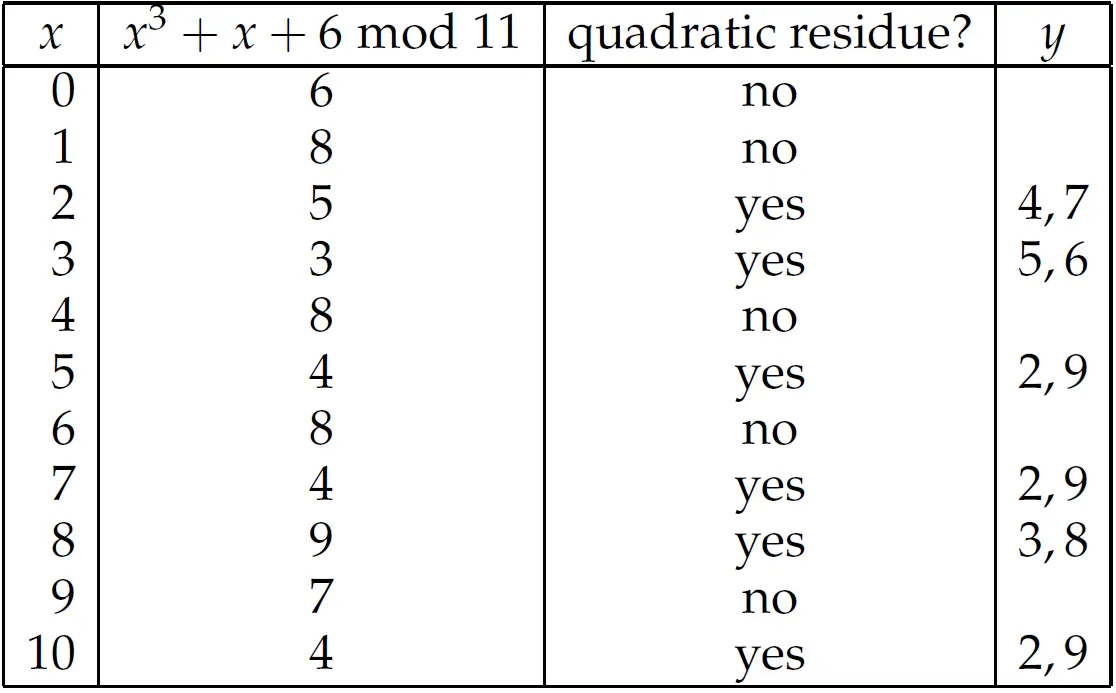
一共有 12 个普通点和 1 个无穷远点 。一共 13 个点,13 是素数。在群论中,如果一个有限群的阶是素数,那么这个群一定是循环群。
所以这个椭圆曲线最神奇的地方,是你可以把两个点 和 相加,得到第三个点 (而且 必定也在这条曲线上)。设一个生成元 ,我们来尝试计算 。
,因为此时 ,需要使用斜率公式 ,代入 得到:
,使用拓展欧几里得算法可以得到:,所以 。
代入计算 , .
所以:. 它也在曲线上。
同理我们计算 . 因为 ,所以 , 代入得到:.
同样使用拓展欧几里得算法,,所以 ,同理计算出 , 。
代入 中:, . 所以 ,它同样在曲线上。
在椭圆曲线的密码系统 (ECC)中,我们将离散对数 替换为 代替进行加密。
签名方案
我们前面学到了很多不同的加密方法,它们都是将明文加密,从而确保信息的机密性。然而,在实际通信过程中,验证发送者的身份以及确保消息在传输过程中未被篡改同样至关重要。
Hash 函数是给数据生成一个指纹,它只回答了内容有没有修改。我们还想知道并验证发送者的真实身份,数字签名方案正是为此设计的,它利用 非对称加密 技术,让发送方使用私钥对消息进行签名,而接收方通过对应的公钥来验证签名的有效性和完整性。
数字签名在本质上就是 Hash + 非对称加密。
RSA 签名方案
RSA 签名方案是一种基于 RSA 密码系统的数字签名方法,它的过程几乎与 RSA 加密一样。
在 下,设 是两个质数 和 的乘积,定义密钥 。对于明文和密文 ,定义:
- 签名函数
- 验证函数 此时, 和 组成了公钥,, , 组成了私钥。
也就是说对于消息 ,Alice 生成签名:;验证者检查: 是否等于原消息 。如果相等,签名有效;否则无效。
在这个 RSA 签名方案中,签名使用 RSA 的“解密规则”,验证使用 RSA 的“加密规则”。
接下来通过一个例子来看懂流程:
假设 Alice 选择质数 ,则 且 . 选择公钥指数:,然后找私钥指数 ,使得:,所以 .
- 公钥:
- 私钥:
现在 Alice 要签名消息:,代入签名函数:;
所以 Alice 发给 Bob:.
Bob 将使用验证函数及公钥进行验证:,结果正好等于原消息 ,所以验证通过。
如果攻击者想要伪造 Alice 对某条消息 的签名。他没有私钥,很难从 反推出 。但它是不安全的,因为黑客可以利用数学进行一种名为 “存在性伪造” (Existential Forgery) 的攻击。因为验证时会检查:,攻击者可以随意选取一个 ,计算:,得到一个合法的 ,因为数学上正确。
为了解决这种安全性问题,在实际应用中,RSA 签名通常不会直接对原始消息进行操作,而是先对消息计算 Hash 值。通过对 进行签名,攻击者由于无法控制 Hash 函数的输出结果,便难以通过随机选取 来反推一个有意义的消息 ,从而有效地抵御了存在性伪造攻击。
对比 RSA 加密和签名,区别如下:
| 项目 | RSA 加密 | RSA 签名 |
|---|---|---|
| 目标 | 保密 confidentiality | 认证与完整性 authenticity + integrity |
| 谁使用公钥 | 发送者用接收者公钥加密 | 验证者用签名者公钥验证 |
| 谁使用私钥 | 接收者用私钥解密 | 签名者用私钥签名 |
| 数学操作 | ||
| 反向操作 | 检查 | |
| 核心含义 | 只有私钥持有者能读 | 只有私钥持有者能签 |
ElGamal 签名方案
ElGamal 签名是基于离散对数困难问题的签名。它的签名过程也和 ElGamal 密码系统类似。
设 是一个足够大的质数,选定一个生成元 ,在非零元素循环群 中,定义一个密钥:。对 ,选定一个随机数 , 必须和 互素 ,保证它有逆元。定义:
- 签名函数:,它实际上是构造了一个指数方程:。其中 表示一个随机的印章, 表示信息真正的签名。
- 检验函数:只需要检查 . 如果成立,就接受签名;否则拒绝。
其中,, , 组成公钥, 则是私钥, 是每次随机生成的,不会被传递。
在验证时:Bob 不知道 也不知道 ,他可以把整个方程放到以 为底数的指数上去看 。
此时:
- 就是 Alice 的公钥 。
- 就是签名里带着的 。
只需要计算: 如果它等于 ,就说明签名正确。
我们发现这个过程中, 模数是 ,但是 模数是 . 因为 的大小是 ,而 的阶也是 , 所以指数只需要在模 下相等即可。
- 底数运算在模 下做;
- 指数关系在模 下做。
我们同样通过一个例子来看这个过程:
设 ,则有:
- Alice 的私钥: 。
- Alice 的公钥的一部分:。
现在 Alice 要对消息 签名。她随机选 。()。所以 在模 下有逆元,并且:。
- 首先我们计算 :.
- 接着计算 :.
- 因此 Alice 的签名是 .
- 验证者知道:,收到 . 代入验证函数:。
- 同时,。左右两边相等,签名验证通过。
比较 RSA 签名和 ElGamal 签名方案:
| 项目 | RSA Signature | ElGamal Signature |
|---|---|---|
| 基础困难问题 | 大整数分解 | 离散对数 |
| 签名是否随机 | 通常基础形式不随机 | 随机 |
| 签名形式 | 一个数 | 两个数 |
| 私钥 | RSA 私钥指数 | |
| 公钥 | ||
| 核心验证 | ||
| 数学核心 | 指数互逆 | 指数线性关系 |
密钥分配
前面学过很多加密、MAC、认证方法,它们经常都有一个前提:Alice 和 Bob 手里已经有同一把秘密钥匙。
密钥分配 (Key Distribution) 要解决的问题是:在一个有 个用户的网络里,如何让他们两两之间都能生成一把共同的秘密钥匙,同时又能抵御一定数量的恶意用户合谋攻击,而且还要尽可能减少每个人需要预先存储的秘密信息。
Blom 方案
Trusted Authority,简称 TA,可以为每一对用户都生成一把不同的密钥用于它们之间的通信:。然后分别安全地发给 和 。
因为任意两个人以后都可能通信。如果提前给每一对用户都发一把钥匙,那么每个人要存很多钥匙,系统也要管理大量钥匙。如果网络中有 个用户,那么用户 需要和其他 个用户分别存一把密钥。整个系统需要大约生成: 对钥匙。
Blom 方案是一种密钥预分配方案 (Key Predistribution Scheme,KPS)。它的核心原理是:TA 不直接给每一对用户发完整钥匙,而是给每个人发一个“钥匙生成器”。用户拿自己的钥匙生成器,输入对方的公开编号,就能得到两人之间的共享密钥。
Blom 方案分配密钥的过程简单来说可以描述如下:
- 首先,选定一个公开的大素数 。给网络里的每一个用户 都分配一个公开的、独一无二的编号 。
- TA 在后台秘密构造一个最高次数为 的 二元对称多项式 。
- 对于用户 ,TA 把他的编号 代入到 里面去,将其变成一个常数。 降维成了一个只剩 的一元多项式切片 。TA 把这个切片 发给用户 。同理,对于用户 经过同样的操作后,发送给用户 。
- 若用户 想要和用户 交流,
- 拿出自己的多项式切片 ,把 的公开编号 代入进去,算出 。
- 拿出自己的多项式切片 ,把 的公开编号 代入进去,算出 。
- 因为 ,所以他们成功获得了共享密钥。
下面是一个例子展示了这个过程:
假设 , TA 设计了一个二元对称多项式:,它是对称的因为:
现在有两个用户 Alice 和 Bob:.
Alice 的编号是 ,所以 TA 给 Alice:,代入 Alice 的编号后得到:。
Bob 的编号是 4,所以 TA 给 Bob:,代入 Bob 的编号后得到:。
当 Alice 想要与 Bob 通信时,她将 Bob 的编号 代入自己的切片中:, 所以 Alice 得到了密钥是 。
同理,Bob 也将 Alice 的编号代入自己的切片中:, Bob 得到 。
两个人的通信没找 TA,也没存储彼此的密钥,而是算出了同一把密钥:。
Blom 方案只能抵抗最多 个人的共谋。如果 TA 设定的多项式最高次数是 ,那么只要有 个用户叛变并把他们的信息拼凑起来,就能恢复整个 。它利用了二次拉格朗日插值法,这里就不做演示了。
密钥协商方案
在密钥分配中,我们一直假设有一个可信任的 TA 在帮忙分发密钥,例如构造的多项式切片等。如果没有这样一个可信的中心呢?在公共网络中,Alice 和 Bob 彼此相隔万里只通过网络交流,从未见过面,且他们之间的所有通信都会被黑客(网络扫描器)一字不落地监听,他们能否在这样的环境下,凭空 “商量 (Key Agreement)” 出一个只有他们俩知道的秘密密码?
这一章里将专注于 密钥协商方案 (Key Agreement):两个人或多个人不直接发送最终密钥,而是 通过交换一些公开信息,各自算出同一把秘密钥匙。
其中最经典且应用最广泛的协议便是 Diffie-Hellman (DH) 密钥交换协议。它允许双方在完全公开的通信环境下,利用大素数和离散对数问题 (Discrete Logarithm Problem) 等数学性质,通过交换各自计算出的中间值来生成共享密钥。即使攻击者截获了所有的通信数据,由于离散对数问题的计算困难性,在不知道双方私有秘密的情况下也无法推导出最终的密钥。
Diffie-Hellman 密钥交换协议
我们在之前的 ElGamal 密码系统中学过,离散对数问题具有 计算指数容易,求离散对数极难 的特点。
回顾一下 ElGamal 密码系统的过程如下:
- 首先选择一个大质数 ,并选择一个 作为模 下的一个生成元,构建出循环群 。
- Bob 选择一个私钥:,然后计算公钥 :。根据离散对数问题的性质,别人知道 ,但很难从 反推出 。于是得到:公钥:,私钥:。
- Alice 想加密消息 ,他将随机选择一个临时随机数 ,然后计算:, ,得到一组密文: 。这里的 类似 提示纸条,而 则是真正加密的内容。
- Bob 收到密文,他用自己的私钥 计算:, 在之前我们计算了一个公钥 ,根据乘法交换律替换:,我们就解出了真正加密内容 中的重要参数 ,而不需要知道 的值。最后,只需要继续计算逆元 乘回 中,即可计算出明文 :。
Alice 用 Bob 的公钥 和自己的随机数 ,算出共享遮罩 ,然后用它加密消息。Bob 用自己的公钥算了 。他们都计算了一个共同秘密值是:。
Diffie-Hellman 密钥交换协议的思想是:既然 Alice 和 Bob 可以在不直接发送秘密值的情况下,共同算出 ,那就 直接将这个值当成密钥好了。它不传消息 ,不生成 ,只生成共享密钥 。
这个协议的具体流程如下:
- Alice 和 Bob 约定一个大素数 ,以及一个生成元 。
- Alice 自己选一个随机数 。她计算 ,并把 发给 Bob。
- Bob 也自己选一个随机数 。他计算 ,并把 发给 Alice。
- 最后两人各自合成最终密钥:
- Alice 拿到 ,计算 。
- Bob 拿到 ,计算 。
最后,他们算出了一个共享密钥:
对于窃听者而言,即便截获了公开传输的 和 ,也无法从 中反推出 ,自然算不出 。
Diffie-Hellman 密钥交换协议与 ElGamal 密码系统不同的是 Alice 和 Bob 都各自选一个随机数,交换 和 ,然后共同算出共享密钥 。DH 只生成这个共享值,把它作为密钥。
下面是一个例子展示了 DH 协议的过程:
- Alice 和 Bob 选定 。
- Alice 选定 ,发送:;
- Bob 选定 ,发送:.
- Alice 收到 ,用自己的秘密数 计算:;
- Bob 收到 ,用自己的秘密数 计算:.
- 于是双方得到同一个密钥:.
但是基础 DH 有一个重要缺陷:Alice 收到的这个值真的来自 Bob。所以基础 DH 容易被 中间人攻击 (man-in-the-middle attack)。
Diffie-Hellman 密钥交换协议与 ElGamal 密码系统的对比如下:
| 对比点 | ElGamal 密码系统 | Diffie-Hellman Key Agreement |
|---|---|---|
| 主要目的 | 加密消息 | 协商密钥 |
| 是否有明文 | 有 | 没有 |
| 谁有长期私钥 | Bob 有 | 基础 DH 中双方每次临时选 |
| Alice 做什么 | 选随机数 ,生成密文 | 选秘密数 ,发送 |
| Bob 做什么 | 用私钥 解密 | 选秘密数 ,发送 |
| 共同秘密值 | ||
| 共同秘密值的用途 | 用来遮住消息 | 直接作为共享密钥或密钥材料 |
| 核心数学 |
会议密钥协商
普通的 Diffie-Hellman 是两个人,但现实里可能是多人会议、群聊、团队通信:即用户 需要共享同一把群组密钥:,该如何生成所有用户都知道,但黑客不知道的密钥呢?这就引出了 会议密钥协商方案 (Conference Key Agreement Scheme, CKAS)。
一种常见的实现方式是 Burmester-Desmedt 协议。在该方案中,所有参与者首先把 个参与者看成一个环,每个人先给左右邻居发送 ,然后每个人广播一个 ,最后所有人都能算出同一个会议密钥。
假设共有 个人,在模数空间 中, 围成一个环,收尾相连:, .
具体来说流程如下:
- 广播:每个用户 选择一个随机数作为秘密 ,计算一个传播值 ,然后把 发给左右邻居:.
- 计算差值:每个人收到邻居发来的两个计算结果 , 后,计算它们之间的差值 。算完之后,每个人把自己的 广播给环里的所有人。
- 计算群密钥:每个人先用自己和邻居的信息算出已知小块:, 结合其他人上一步计算出来广播的差值 , 中包含的 信息逐步推导出所有相邻小块。最后把所有小块乘起来,得到:,得到 ,这就是大家共同得到的会议密钥。
下面是一个简单的例子:
假设有 个用户 ,公开的参数是:,每个人选择秘密数:。
- 广播:每个人算 ,并把自己的 发给左右邻居:
- 计算差值:每个人计算与邻居的差值:,并且广播给所有人:
- 计算群组密钥:以 为例 ,它收到了左邻居 的:,所以他可以先算出自己已知的相邻小块:。接下来用广播出来的差值提示一个个推:,所以:;再用 推:;再用 ,得到 。现在 已经拼出了所有小块:。最后把它们乘起来:,所以得到了群组密钥 .
同理,环中的其他用户 也可以通过这样的方法得到相同的群组密钥。
