

前言
本期专题:《C语言结构体和链表》
本期专题主要讲的是C/C++语言中结构体和链表的使用,C++中大部分适用。
这学期因为疫情,导致课时少了几节,期末考试内容包含了结构体和链表,但是老师又不补课,只发了一份全英文的简单介绍,导致这一节根本就没上过就要考试,故写了这篇来记录下我自学的笔记。联合(Union)部分好像不考,就不讲了。期考也不考这么难好像。
带有*的标题可以选学(应该)。本专题文章内容相对基础,过于专业的部分会省略。
本专题参考文献或网站如下(References):
- 《C Primer Plus》
- 《Pointer On C》
- biancheng.net
- LeetCode
本文文案:@Hoyue
结构
C语言提供了一些由系统已定义好的数据类型,如:int,float, char等,用户可以在程序中用它们定义变量,解决一般的问题,但是人们要处理的问题往往比较复杂,只有系统提供的类型还不能满足应用的要求,C语言允许用户根据需要自已建立一些数据类型,并用它来定义变量。
C提供了 结构变量 (structure variable)提高你表示数据的能力, 它能让你创造新的形式。
结构和数组
聚合数据类型(aggregate data type)能够同时存储超过一个的单独数据。C提供了两种类型的聚合数据类型, 数组 和 结构 。
- 数组是相同类型的元素的集合,它的每个元素是通过下标引用或指针间接访问来选择的。
- 结构也是一些值的集合,这些值称为它的成员 (member),但一个结构的各个成员可能具有不同的类型。
定义结构体
那么怎么使用结构来存储呢?我们需要定义一个结构体,我们用一个例子引入:
Eg. Gwen小姐要打印一份图书目录。她想打印每本书的各种信息: 书名、作者、出版设、版权日期、页数、册数和价格。
其中的此项目(如书名等)可以储存在数组中。我们可以用7个不同的数组去分别记录每一项比较繁琐, 尤其是Gwen还想对其中的项目进行排序的时候。
下面是用结构来储存的例子:
struct Books { /* structure template: tag is book */ char title[MAXTITL];//记录标题 char author[MAXAUTL];//记录作者 int value;//记录价格}book; /* end of structure template.此时Books相当于是一个标记,book是一个结构变量*/- 在{}里的内容,可以是标准的变量定义,比如 int i; 或者 float f,或者其他有效的变量定义。
- book是结构变量,定义在结构的末尾,最后一个分号之前,当然我们也可以单独定义。
- 单独定义时,book处可省略 (分号不能省) ,在之后需要加上定义:struct Books name;就像定义变量一样,只是此时类型是你自己定义的结构标签。
结构变量的初始化
和其它类型变量一样,对结构体变量可以在定义时指定初始值。例如:
struct Books{ char title[50]; char author[50]; int value;}book = {"C语言程序设计", "谭浩强", 50};它们在初始化时有一一对应关系。
结构成员的访问
直接访问
为了访问结构的成员,我们使用 成员访问运算符(.) 。点操作符接受两个操作数,左操作数就是结构变量的名字,右操作数就是需要访问的成员的名字。
例如上面例子中,我要访问书的价格,我可以这么表示:book.value,然后你就把它当成普通变量使用就行了。
本质上,.title、 .author和.value的作用相当于book结构的下标。
间接访问
如果你拥有一个指向结构的指针,你要访问结构,首先就是对指针执行间接访问操作,这使你获得这个结构。然后你使用点操作符来访问它的成员。
但要注意:但是,点操作符的优先级高于间接访问操作符,所以你必须在表达式中使用括号,确保间接访问首先执行。
例如,你定义了一个结构体和一个函数的参数是个指向结构的指针:
struct COMPLEX{ int f; int *lp;}struct COMPLEX comp;void func( struct COMPLEX *cp );函数可以使用这个表达式来访问这个变量所指向的结构的成员f:(*cp).f
即对指针执行间接访问将访问结构,然后点操作符访问一个成员。
结构作为函数参数
可以把结构作为函数参数,传参方式与其他类型的变量或指针类似。例如:
struct Books{ char title[50]; char author[50]; int value;};void printBook( struct Books book );//声明结构参数使用时候和指针的传址调用方式差不多,这里就不赘述了。
结构数组
回到我们刚开始的图书的例子,假设此时不止一本书,我们该怎么办呢?我们需要把结构和数组结合在一起,定义结构数组。
struct Books { char title[MAXTITL];//记录标题 char author[MAXAUTL];//记录作者 int value;//记录价格}book[101];//定义了一个结构体数组这个相当于在外面定义:struct Books book[101];
我们在使用中就可以使用数组和结构的功能了,例如,我要访问第i本书的价格,我可以这么表示:book[i].value;
数组部分和一般的数组使用没有什么区别,就是它还有结构的性质。
高维度二维数组
我们平常可能会遇到要定义二维数组,但数据很大,例如m[1001][1001],如果有内存限制1MB的话,这肯定会爆内存(410001000=4MB),但是如果是一维数组的话上限就更大,于是我们想到可以用结构和数组结合来定义高维度二维数组,例如:
struct matrix{ int c[1001];//column}r[1001];//row指向结构的指针
可以定义指向结构的指针,方式与定义指向其他类型变量的指针相似。这一部分在指针专题的第三章会具体讲的,这里只是简单提一下。我们可以声明一个结构指针:
struct Books *struct_pointer;
我们还可以继续给它赋值,如果stru是一个Books的结构,让指针指向它,我们可以这么写:struct_pointer = &stru;注意, 结构的名字不是地址,不要和数组名记混 。
或者如果我们想指向一个结构数组,例如它的名字是s[N],我们可以这么写:struct_pointer = &s[0];此时s是结构数组, 结构数组的名字也不是地址。
用指针访问成员
接上面的例子,如果我们想用指针访问结构变量下的成员,我们该这样表示:
使用->运算符。该运算符由一个连接号(-)后跟一个大于号(>)组成。
- 如果struct_pointer = &stru, 那么struct_pointer->value 即是stru.value
- 如果struct_pointer = &s[0], 那么struct_pointer->value 即是s[0].value
注意由 “指针->成员” 的形式组成的是一个值,表示访问结构成员的值。
当然我们还可以用间接访问符*访问,例如:
如果struct_pointer = &s[0], 那么*struct_pointer == s[0], 因为&和*是一对互逆运算符。
因此, 可以这么表达:s[0].value==(*struct_pointer).value; 必须要使用圆括号, 因为.运算符比*运算符的优先级高。
*位域
有些信息在存储时,并不需要占用一个完整的字节,而只需占几个或一个二进制位。例如在存放一个开关量时,只有 0 和 1 两种状态,用 1 位二进位即可。为了节省存储空间,并使处理简便,C 语言又提供了一种数据结构,称为”位域”或”位段”。
所谓”位域”是把一个字节中的二进位划分为几个不同的区域,并说明每个区域的位数。每个域有一个域名,允许在程序中按域名进行操作。这样就可以把几个不同的对象用一个字节的二进制位域来表示。
位域定义与结构定义相仿,其形式为:
struct 位域结构名{ 位域列表};其中位域列表的形式为:类型 位域名: 位域长度。
例如:
struct bs{ int a:8; int b:2; int c:6;}data;说明 data 为 bs 变量,共占两个字节。其中位域 a 占 8 位,位域 b 占 2 位,位域 c 占 6 位。
位域的使用和结构成员的使用相同,其一般形式为:
- 位域变量名.位域名
- 位域变量名->位域名
其他的内容我们可以显然的发现和结构体的使用差不多。
链式结构
结构有很多种用途,其多种用途之一: 创建新的数据形式。计算机用户已经开发出的一些数据形式比我们提到过的数组和简单结构更有效地解决特定的问题。这些形式包括队列、二叉树、堆、哈希表和图表。许多这样的形式都由 链式结构 (linked structure)组成。
通常, 每个结构都包含一两个数据项和一两个指向其他同类刚结构的指针。这些指针把一个结构和另一个结构链接起来, 并提供一种路径能遍历整个彼此链接的结构。
了解了链式结构,我们接下来看链表是什么。
链表
我们定义数组是需要预先知道数据大小,然后申请连续的存储空间,而在进行扩充时又需要进行数据的搬迁,所以使用起来并不是很灵活。采用链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。
与数组相似,链表也是一种线性数据结构。 链表 (Linked list)是一种线性表,但是不像顺序表一样连续存储数据,而是在每一个节点(数据存储单元)里存放下一个节点的位置信息(即 地址 )。

单向链表
单向链表也叫单链表,是链表中最简单的一种形式,它的每个节点包含两个域,一个信息域(元素域)和一个链接域。这个链接指向链表中的下一个节点,而最后一个节点的链接域则指向一个空值。
下面是一个单链表的例子:蓝色箭头显示单个链接列表中的结点是如何组合在一起的。

一般模板:定义存放链表结点的类Node,类中包含两个字段: data 字段和 next 字段, data 字段是结点中的数值域, next 是指向链表下一个结点的引用
struct Node { // type of a node in a single linked list int data; struct node * next;//指向下一步的指针};这个模板可以这么解释:
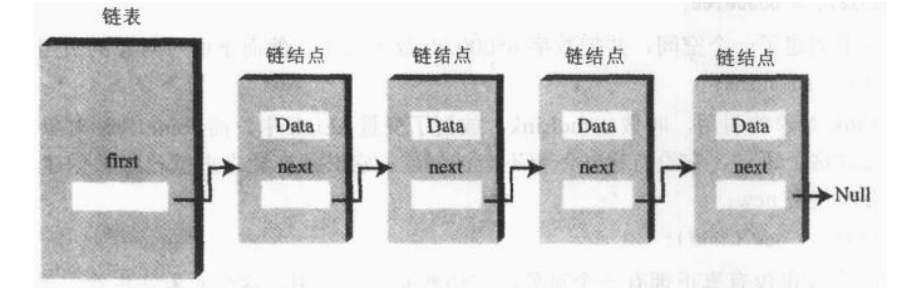
链表头first,是一个指针,末尾的结点没有下一个结点了,所以下一个字段是NULL(空指针)。
双向链表
我们在前面的章节中介绍了单链表。单链接列表中的结点具有 data 字段用于存储数据,以及用于顺序链接结点的”Next”引用字段。
双链表也以类似的方式工作,但还有一个引用字段,称为prev字段。有了这个额外的字段,就能够知道当前结点的前一个结点。那么我们就知道了前一个结点的和后一个结点的地址了,它的图是例如这样的。

一般模板:在单链表的基础上增加一个字段即可。
struct dNode{ // type of a node in a double linked list int data; struct dNode * prev; // address of the previous node struct dNode * next; // address of the next node};和单链表一样,末尾的结点没有下一个结点了,所以下一个字段是NULL(空指针),双链表还多一个性质,头结点之前也没有结点了,所以头结点的上一个字段也是NULL。
头结点、头指针和首元结点
头结点:有时,在链表的第一个结点之前会额外增设一个结点,结点的数据域一般不存放数据(有些情况下也可以存放链表的长度等信息),此结点被称为 头结点 。
若头结点的指针域为空(NULL),表明链表是 空表 。头结点对于链表来说,不是必须的,在处理某些问题时,给链表添加头结点会使问题变得简单。
首元结点:链表中第一个元素所在的结点,它是头结点后边的第一个结点。
头指针:永远指向链表中第一个结点的位置的 指针 (如果链表有头结点,头指针指向头结点;否则,头指针指向首元结点)。
头结点和头指针的区别:头指针是一个指针,头指针指向链表的头结点或者首元结点;头结点是一个实际存在的结点,它包含有数据域和指针域。两者在程序中的直接体现就是:头指针只声明而没有分配存储空间,头结点进行了声明并分配了一个结点的实际物理内存。
单链表中可以没有头结点,但是不能没有头指针!
链表操作
也许大家看了链表的定义后还是一头雾水,它在使用中要如何使用呢?我们接下来才是重点。
链表的创建和遍历
初始化链表首先要做的就是 创建链表的头结点 或者 首元结点 。创建的同时,要保证有一个指针永远指向的是链表的表头,这样做不至于丢失链表。
例如创建一个链表(1,2,3,4):
Node * initLink(){ Node * p=(link*)malloc(sizeof(link));//创建一个头结点 Node * temp=p;//声明一个指针指向头结点,用于遍历链表 //生成链表 for (int i=1; i<=4; i++) { Node *a=(Node*)malloc(sizeof(Node)); a->data=i;//数据存储 a->next=NULL;//指针指向下一位 temp->next=a; temp=temp->next; } return p;}链表中查找某结点
一般情况下,链表只能通过头结点或者头指针进行访问,所以实现查找某结点最常用的方法就是对链表中的结点进行逐个遍历。
int selectElem(link * p,int data){ link * t=p; int i=1; while (t->next) { t=t->next; if (t->data==data) { return i; } i++; } return -1;}如果返回-1则没找到,否则就会返回查找到的位置。
向链表中插入结点
链表中插入头结点,根据插入位置的不同,分为3种:
- 插入到链表的首部,也就是头结点和首元结点中间;
- 插入到链表中间的某个位置;
- 插入到链表最末端;
插入时,一般为图示的插入方法:
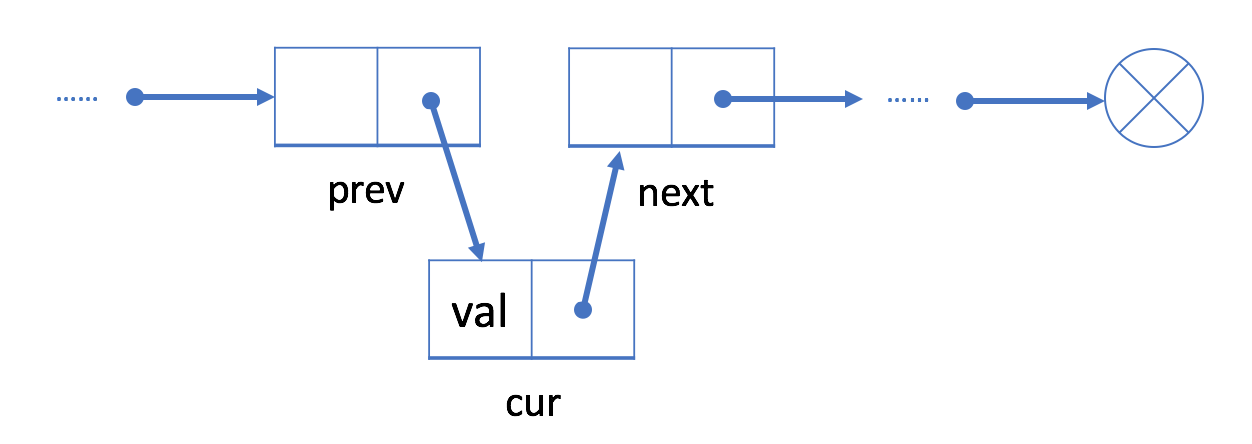
- 将新结点的next指针指向插入位置后的结点;
- 将插入位置前的结点的next指针指向插入结点;
Node * insertElem(Node * p,int data,int add){ Node * temp=p;//创建临时结点temp //首先找到要插入位置的上一个结点 for (int i=1; i<add; i++) { if (temp==NULL) { printf("插入位置无效\n"); return p; } temp=temp->next; } //创建插入结点c Node * c=(Node*)malloc(sizeof(Node)); c->data=data; //向链表中插入结点 c->next=temp->next; temp->next=c; return p;}从链表中删除节点
当需要从链表中删除某个结点时,需要进行两步操作:
- 将结点从链表中摘下来;
- 手动释放掉结点,回收被结点占用的内存空间;
使用malloc函数申请的空间,一定要注意手动free掉。否则在程序运行的整个过程中,申请的内存空间不会自己释放(只有当整个程序运行完了以后,这块内存才会被回收),造成内存泄漏.
Node * delElem(Node * p,int add){ Node * temp=p; //temp指向被删除结点的上一个结点 for (int i=1; i<add; i++) { temp=temp->next; } Node * del=temp->next;//单独设置一个指针指向被删除结点,以防丢失 temp->next=temp->next->next;//删除某个结点的方法就是更改前一个结点的指针域 free(del);//手动释放该结点,防止内存泄漏 return p;}完整代码
我们看了上面的内容,其他博主写了个完整的代码供大家参考。
#include<stdio.h>#include<stdlib.h>typedef struct Link{ int elem; struct Link *next;}link;link * initLink();//链表插入的函数,p是链表,elem是插入的结点的数据域,add是插入的位置link * insertElem(link * p,int elem,int add);//删除结点的函数,p代表操作链表,add代表删除节点的位置link * delElem(link * p,int add);//查找结点的函数,elem为目标结点的数据域的值int selectElem(link * p,int elem);//更新结点的函数,newElem为新的数据域的值link *amendElem(link * p,int add,int newElem);void display(link *p);
int main() { //初始化链表(1,2,3,4) printf("初始化链表为:\n"); link *p=initLink(); display(p);
printf("在第4的位置插入元素5:\n"); p=insertElem(p, 5, 4); display(p);
printf("删除元素3:\n"); p=delElem(p, 3); display(p);
printf("查找元素2的位置为:\n"); int address=selectElem(p, 2); if (address==-1) { printf("没有该元素"); }else{ printf("元素2的位置为:%d\n",address); } printf("更改第3的位置的数据为7:\n"); p=amendElem(p, 3, 7); display(p);
return 0;}
link * initLink(){ link * p=(link*)malloc(sizeof(link));//创建一个头结点 link * temp=p;//声明一个指针指向头结点,用于遍历链表 //生成链表 for (int i=1; i<5; i++) { link *a=(link*)malloc(sizeof(link)); a->elem=i; a->next=NULL; temp->next=a; temp=temp->next; } return p;}link * insertElem(link * p,int elem,int add){ link * temp=p;//创建临时结点temp //首先找到要插入位置的上一个结点 for (int i=1; i<add; i++) { if (temp==NULL) { printf("插入位置无效\n"); return p; } temp=temp->next; } //创建插入结点c link * c=(link*)malloc(sizeof(link)); c->elem=elem; //向链表中插入结点 c->next=temp->next; temp->next=c; return p;}
link * delElem(link * p,int add){ link * temp=p; //遍历到被删除结点的上一个结点 for (int i=1; i<add; i++) { temp=temp->next; } link * del=temp->next;//单独设置一个指针指向被删除结点,以防丢失 temp->next=temp->next->next;//删除某个结点的方法就是更改前一个结点的指针域 free(del);//手动释放该结点,防止内存泄漏 return p;}int selectElem(link * p,int elem){ link * t=p; int i=1; while (t->next) { t=t->next; if (t->elem==elem) { return i; } i++; } return -1;}link *amendElem(link * p,int add,int newElem){ link * temp=p; temp=temp->next;//tamp指向首元结点 //temp指向被删除结点 for (int i=1; i<add; i++) { temp=temp->next; } temp->elem=newElem; return p;}void display(link *p){ link* temp=p;//将temp指针重新指向头结点 //只要temp指针指向的结点的next不是Null,就执行输出语句。 while (temp->next) { temp=temp->next; printf("%d",temp->elem); } printf("\n");}后记
链表这一部分确实是比较复杂的,链表和数组的使用有什么区别呢?线性表的链式存储相比于顺序存储,有两大优势:
- 链式存储的数据元素在物理结构没有限制,当内存空间中没有足够大的连续的内存空间供顺序表使用时,可能使用链表能解决问题。(链表每次申请的都是单个数据元素的存储空间,可以利用上一些内存碎片)
- 链表中结点之间采用指针进行链接,当对链表中的数据元素实行插入或者删除操作时,只需要改变指针的指向,无需像顺序表那样移动插入或删除位置的后续元素,简单快捷。
链表和顺序表相比,不足之处在于,当做遍历操作时,由于链表中结点的物理位置不相邻,使得计算机查找起来相比较顺序表,速度要 慢 。
