

前言
现实生活中,我们完成一件事会存在先后顺序,而在完成一个重要的项目的时候,我们会给这些事情安排一个进行顺序。这些事情之间,通常会受到一定的条件约束,如其中某些活动必须在另一些活动完成之后才能开始。我们要如何安排这些顺序,就是这一章会涉及的了。
本章内容为拓扑排序,是书本《Data Structures and Algorithm Analysis in C》的第九章的1~2节。
图论基础内容
在学习拓扑排序之前,我们需要先了解一些图论的基础内容。
在 线性表 中,数据元素之间是被串起来的,仅有线性关系,每个数据元素只有一个直接前驱和一个直接后继。在 树形结构 中,数据元素之间有着明显的层次关系,并且每一层上的数据元素可能和下一层中多个元素相关,但只能和上一层中一个元素相关,且它们这一层之间的元素也基本没什么关系。
但是就像现实中一样,人与人之间关系就非常复杂,我认识的朋友,可能他们之间也互相认识,这就不是简单的一对一、一对多,研究人际关系很自然会考虑多对多的清况。
于是就出现了新的数据结构——图。 在图形结构中,结点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关。
我们定义: 图(Graph) 是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为: G (V,E) ,其中, G 表示一个图, V 是图G 中顶点(Vertex)的集合, E 是图G 中边(Edge)的集合。
注意,在图结构中,不允许没有顶点,即V是非空集合。而E可以为空集,说明V之间没有边连接,它们没有联系。
接下来是一些图中的定义。
图的一些定义
无向边/无向图
若顶点Vi到Vj之间的边 没有方向 ,则称这条边为无向边(Edge)。用(Vi,Vj)表示,此时它等价于(Vj,Vi)。如果图中任意两个顶点之间的边都是无向边,则称该图为 无向图 (Undirected graphs)。
有向边/有向图
若从顶点Vi到Vj的边 有方向 ,则称这条边为有向边,也称为 弧(Arc) 。用 有向序偶(Vi,Vj) 来表示, Vi 称为弧尾(Tail), Vj 称为弧头(Head) 。如果图中任意两个顶点之间的边都是有向边,则称该图为 有向图 (Directed graphs) 。
用一张图来表示无向图和有向图:

简单图
每条边都连接着两个不同的顶点,且没有两条不同的边连接同一对顶点,则称这样的图为简单图。
完全图
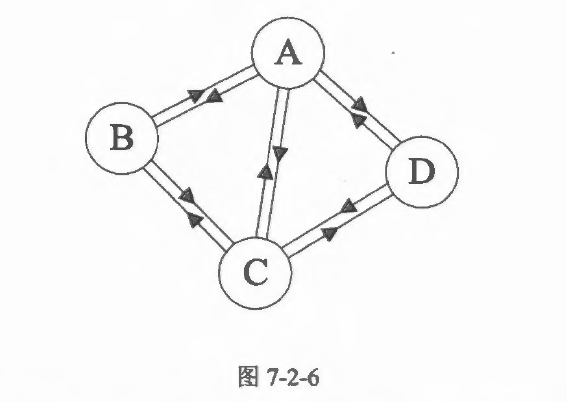
如果任意两个顶点之间都存在边,则称该图为完全图。在无向图中,则称为无向完全图。在有向图中,如果任意两个顶点之间都存在方向互为相反的两条弧,则称该图为有向完全图。(如图)
权
有些图的边或弧具有与它相关的数字,这种与图的边或弧相关的数叫做权(Weight)。
子图
假设有两个图G= {V,E} 和G’= (V’,E’),如果V’ ⊆ V 且E’ ⊆ E, 则称G’为G 的子图(Subgraph).
顶点与边间关系
度
顶点V的度(Degree)是 和V相关联的边的数目。 在有向图中,度我们一般分为入度和出度。以顶点V为头的弧的数目称为V的 入度 (lnDegree),以V为尾的弧的数目称为V的 出度 (OutDegree)。
路径
图G = {V,E}中从顶点v 到顶点v’ 的 路径(Path) 是一个顶点序列。
环
第一个顶点到最后一个顶点相同的路径称为回路或 环 (Cycle)。
邻接
对于无向图G={V,E},如果边(V,V’)被边连接, 则称顶点V和V’ 互为邻接点 (Adjacent) ,即V和V’相邻接。
联通性
联通图
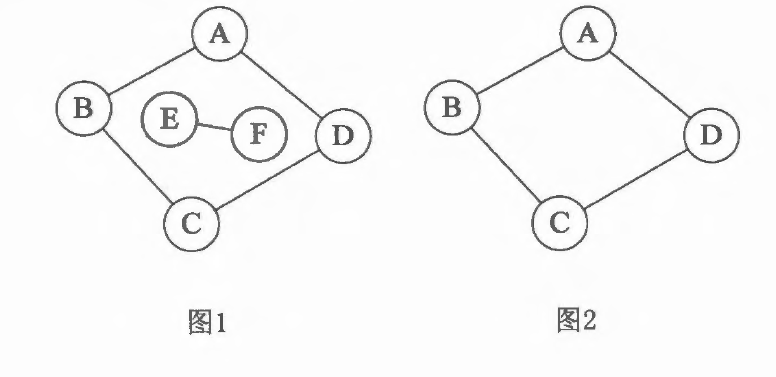
在无向图G 中,如果从顶点V到顶点V’有路径,则称V和V’是连通的。如果对于图中任意两个顶点之间均为联通的的图,称为连通图(Connected Graph)。如图1不是联通图,因为E、F没有和其他顶点联通;图2是连通图。
强连通
在有向图G中,如果对于每一对Vi和Vj,都有Vi->Vj、Vj->Vi的路径,则称G是 强连通 图(Strong Connected)。有向图中的极大强连通子图称做有向图的强连通分量。
弱连通
有向图G中,若任意两个顶点之间均存在通路,则称G为 弱连通 图(Weak Connected)。均存在通路是指去除方向后连通即可。
总结一下:
- 若每个顶点到其他各个顶点之间有通路 ,则是 强连通 的。
- 若有向图对应的无相图是连通的 ,则这个有向图是 弱连通 的。
- 一个有向图可以 同时存在 强连通和弱连通属性。
图的表示
邻接矩阵
用二维矩阵来表示顶点(V,V’)的相邻关系,这个矩阵是 邻接矩阵 (Adjacency Matrix)。
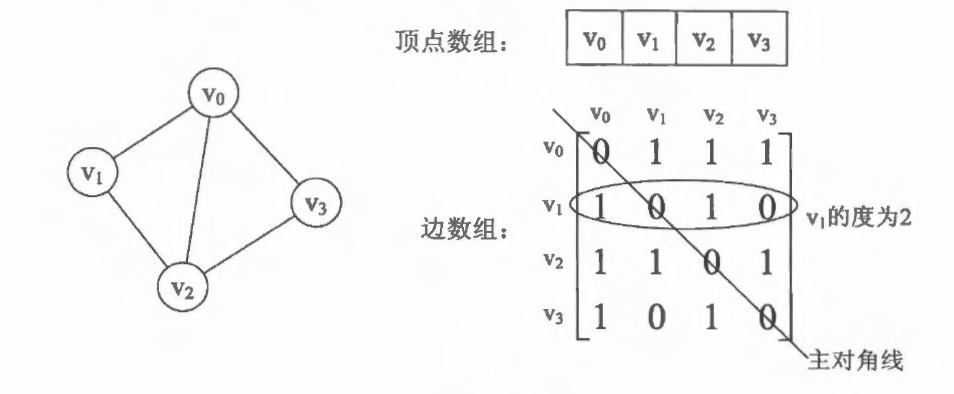
可以看出,在0-1邻接矩阵中,若Vi与Vj相邻,则矩阵中(i,j)处为1,反之为0。无向图中,它们沿着主对角线对称,每一行加起来则为那个顶点的度。
我们实现邻接矩阵一般使用二维数组,它适用于顶点比较少,图较为稠密(边、弧比较多)的情况。
邻接表
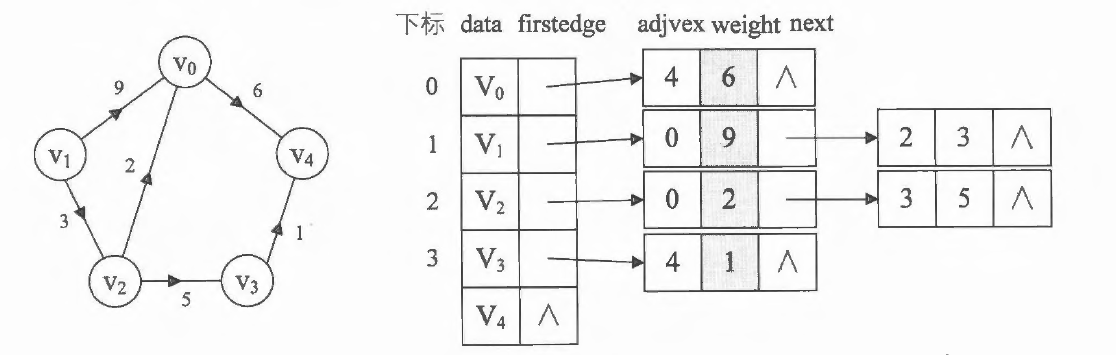
当我们的图顶点比较多,比较稀疏(边、弧比较少)时,我们一般会使用邻接表来表示图。我们把数组与链表相结合的存储方法称为 邻接表 (Adjacency List)。其中数组下标表示顶点的编号,数组内存储的是指向第一个邻接点的指针。
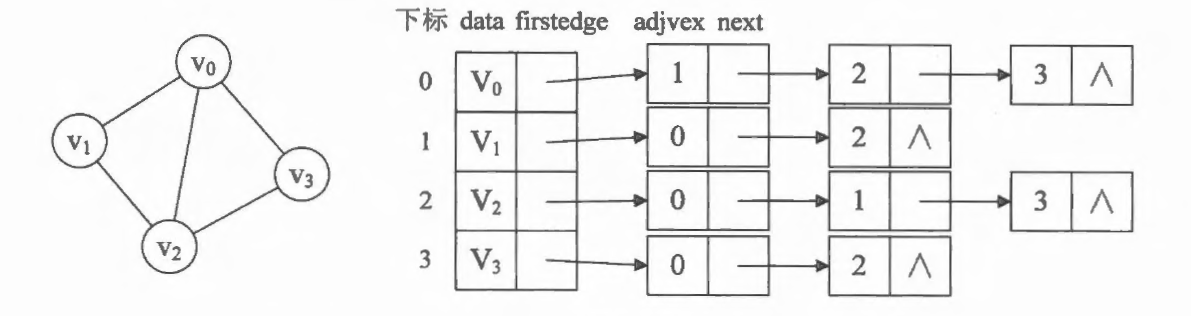
此时我们很容易就可以算出某个顶点的入度或出度是多少,判断两顶点是否存在弧也很容易实现。
对于带权值的图,可以在边表结点定义中再增加一个weight 的数据域,存储权值信息即可:
拓扑排序
介绍完图论的一些简单基础知识后,就到了无环的图应用——拓扑排序。在拍摄电影的时候,这个项目会有很多的事件,我们将它们做成一个流程图,如下:
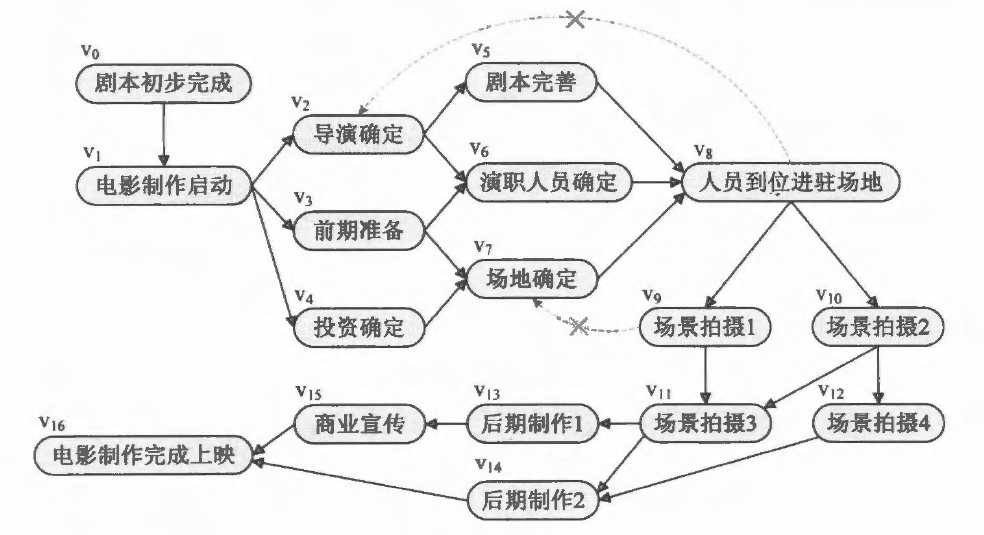
在这些活动之间,通常会受到一定的条件约束,如其中某些活动必须在另一些活动完成之后才能开始。例如场景拍摄不可能在人员到位进驻场地前,因为现在场地都没有怎么拍。因此这样的工程图,一定是 无环的有向图。
设G=(V,E)是一个具有n个顶点的有向图, V 中的顶点序列V1, V2, ……,Vn,满足若从顶点Vi到Vj有一条路径,则在顶点序列中顶点Vi必在顶点Vj之前。则我们称这样的顶点序列为一个 拓扑序列 。
此时在有向图中顶点Vi到Vj有一条路径,意思为Vi -> Vj,而不蕴含Vj -> Vi。此时因为在一个项目中,故此时存在先后顺序,顶点序列中顶点Vi必在顶点Vj之前。
拓扑排序 ,其实就是 对一个有向图构造拓扑序列的过程 。这个过程会让项目中 全部顶点 输出,而排序的结果不一定唯一,合理的输出均正确。
拓扑排序的基本思路是: 从无圈图中选择一个入度为0的顶点,然后删去此顶点,并删除以此顶点为尾的弧,继续重复此步骤,直到输出全部顶点或者无圈图中不存在入度为0的顶点为止。
我们一般使用邻接表来存储图,至于入度为0的顶点如何处理我们有如下方案:
- 写一个Indegree()函数,在每次删除顶点和它的弧后,用于找到入度为0的顶点,并用数组存储。
- 用一个全局的数组、 栈或队列 储存入度为0的顶点们,在每次删除顶点和它的弧后,检查调整入度的节点入度是否为0,为0则加入到队列中。
第一种方案明显是耗费更多时间的,因为每次查找都要扫描所有的顶点。而第二种方案是为了避免每个查找时都要去遍历顶点表找有没有入度为0的顶点,我们存储结构的选取就很关键。
一般情况下,我们会选取 队列 作为存储入度为0的顶点编号,而使用 栈 存储也是可以的。它们两种不同的存储方法可能会带来不同的拓扑序列,它们都是正确的。
故拓扑排序算法我们一般如下设计:
- 建图,初始化图。
- 建队列或栈,把入度为0的顶点编号放入队列或栈中。
- 出队或出栈首元素,并把那个元素放入数组中。
- 扫描首元素相邻的邻接点,并把它们的入度-1,如果该邻接点入度-1后入度为0,则将该点入队或入栈。
- 重复2操作,直到队列或栈为空。
接下来我们就用两种不同的存储方法实现拓扑排序。
首先是这两种方法统一的图的存储:
typedef struct Edge_Node /* 边表结点 */{ int adjvex; /* 邻接点域,存储该顶点对应的下标 */ struct Edge_Node *next; /* 链域,指向下一个邻接点 */}EdgeNode;
typedef struct Vertex_Node /* 顶点表结点 */{ int in; /* 顶点入度 */ int data; /* 顶点域,存储顶点信息 */ EdgeNode *firstedge;/* 边表头指针 */}VertexNode, *AdjList;
typedef struct{ AdjList adjList; int numVertexes; /* 图中当前顶点数 */}graphAdjList,*GraphAdjList;我们此时用一个域 in ,来记录入度,这样就不用反复计算了。
接下来是创建邻接表:
GraphAdjList CreateGraph(int ver[], int **edge, int n){ /*ver[]为顶点的数组,**edge为边的数组,n为顶点数*/ GraphAdjList G=(GraphAdjList)malloc(sizeof(graphAdjList)); if(G == NULL) { printf("No space!\\n"); exit(-1); } G->numVertexes=n; G->adjList=(AdjList)malloc(sizeof(VertexNode) * n); for(int i=0;i<n;i++) { G->adjList[i].data=ver[i]; G->adjList[i].firstedge=NULL; G->adjList[i].in=0; } for(int i=0;i<n;i++) for(int j=0;j<n;j++) { if(edge[i][j] == 1) { EdgeNode *e=(EdgeNode *)malloc(sizeof(EdgeNode)); e->adjvex=j; e->next=G->adjList[i].firstedge->next; G->adjList[i].firstedge->next=e; /* 插入到链表首部 */ G->adjList[j].in++; } } return G;}基于队列
基于队列的排序,我用到的队列ADT来源于《队列的链表实现》
根据之前所说的方法,我们的拓扑排序算法就很简单了:
void TopologicalSort_Queue(int *A, GraphAdjList G){ int count=0; Queue Q=CreateQueue(); for(int i=0;i<G->numVertexes;i++) /* 将入度为0的顶点入队 */ { if(!G->adjList[i].in) Enqueue(i,Q); } while(!IsEmpty(Q)) { int v=FrontAndDequeue(Q); /* 出队并得到队首元素 */ A[count++]=v; EdgeNode *p=G->adjList[v].firstedge->next; while(p) { int t=p->adjvex; G->adjList[t].in--; /* 将顶点t的邻接点的入度减1 */ if(!G->adjList[t].in) /*如果当前顶点入度减1后为0,则入队 */ Enqueue(t,Q); p=p->next; } } if(count < G->numVertexes) { printf("Error, the graph has loops\\n."); return; }}基于栈
同理,基于栈的拓扑排序,我们只需要改变队列为栈即可。这里用到的栈ADT是栈的链表实现:
https://hoyue.fun/data_structure_2.html#%E6%A0%88%E7%9A%84%E9%93%BE%E8%A1%A8%E5%AE%9E%E7%8E%B0
void TopologicalSort_Stack(int *A, GraphAdjList G){ int count=0; Stack S=create(); for(int i=0;i<G->numVertexes;i++) /* 将入度为0的顶点入栈 */ { if(!G->adjList[i].in) push(S,i); } while(!IsStackEmpty(S)) { int v=pop(S); /* 出栈并得到队首元素 */ A[count++]=v; EdgeNode *p=G->adjList[v].firstedge->next; while(p) { int t=p->adjvex; G->adjList[t].in--; /* 将顶点t的邻接点的入度减1 */ if(!G->adjList[t].in) /*如果当前顶点入度减1后为0,则入栈 */ S=push(S,t); p=p->next; } } if(count < G->numVertexes) { printf("Error, the graph has loops\\n."); return; }}后记
以上则为拓扑排序的内容,队列和栈带来的拓扑序列结果不一定相同,但都正确。此刻我们涉及到的是无权的图,在有权图中的拓扑排序往往会存在一些条件,我们需要根据那些条件来设计拓扑排序算法。
