

前言
这一章的内容是表、栈和队列,主要介绍链表、栈和队列的运用,因为之前有单独讲过链表了,这里就补充一点就好。
对应书本《Data Structures and Algorithm Analysis in C》第3章 表、栈和队列
抽象数据类型
抽象数据类型(abstract data type, ADT) 是一些操作的集合。抽象数据类型是数学的抽象:ADT的定义中根本没涉及如何实现操作的集合。
对诸如表、集合、图和它们的操作一起可以看作是抽象数据类型,就像整数、实数和布尔量是数据类型一样。对于ADT,我们的操作有交(intersection),并(union),取大小(size),取余(complement),查找(find)等。其中并和查找这两种操作又在该集合上定义了一种不同的ADT(并查集)。
表
我们可以像表ADT就像是表的操作。关于表的操作都可以通过使用数组来实现,即使我们使用动态数组使得分配的空间是动态指定的,但仍需要对最大值进行估计,可能还是会出现空间浪费。而且对于操作插入元素、删除元素,这些都会至少有 的时间。
为了避免插入和删除的线性开销,我们需要允许表可以不连续存储,否则表的部分或全部需要整体移动。
所以我们引入单向链表的概念:链表由一系列不必在内存中相连的结构组成。每一个结构均含有表元素和指向包含该元素和后继元素的结构的指针。
这一部分我们在链表专题里有介绍过:
https://hoyue.fun/linkedlist_c.html
接下来我们复习一下相关操作的代码:
创建
首先我们需要新建一个表,需要使用typedef定义一个类型(因为C语言中类型需要跟上struct,会导致代码体验感下降):
typedef struct Linklist{ int data; struct Linklist * next;}link;双向链表的话:
typedef struct Linklist{ int data; struct Linklist * next; struct Linklist * prev;}link;接下来需要对它进行初始化:当然这里没有初始化节点内容,可以在创建时就导入数组之类的。
link *ini() //返回head指针{ link *p=(link *)malloc(sizeof(link)); head=p; head->next=NULL; head->data=0; return head;}查找
link * find(int d) //设head是一个全局变量,data为int型{ if(head->next==NULL) //如果链表为空 { return NULL; } link *p=head; while(p->next) //由next来判断会导致最后一个元素不进入循环 { if(p->data==d) return p; p=p->next; } if(p->data==d) return p; //判断最后一位元素 else return NULL;}插入
插入节点是我们把数据导入链表的方法:
link *insertlink(int d,link * pos) //在pos位置后面插入节点{ link *p=(link *)malloc(sizeof(link)); p->next=pos->next; //连接上原来后面的节点 p->data=d; pos->next=p; //替换掉下一个位置 return p;}删除
删除我们可以结合前面的查找函数:
link *deletenode(int d) //删除指定数据{ if(!find(d)) { link *p=find(d); if(p==head) //特判首节点 { head=head->next; free(head); return head; } link *t=head; while(t->next!=p) //找到上一个节点 t=t->next; t->next=p->next; free(p); return t; } else return NULL;}还可以删除整个表:
void *deletelink(){ link *p=head; while(p->next!=NULL) //除最后一个节点 { link *t=p->next; free(p); p=t; } free(p); //删除最后一个节点}防止出现NULL->NEXT的这种情况导致的程序崩溃,最后再删除最后一个节点。
双向链表与循环链表
我们发现有些时候单向链表只能记录后面的节点,不知道前面的节点,不好进行插入和删除的操作等,我们可以使用双向链表,它有两个指针,分别指向前一个节点和后一个节点。
循环链表就是头尾相接的链表,它的末节点next指向了head,head的prev也指向了末节点,形成一个循环,如图:
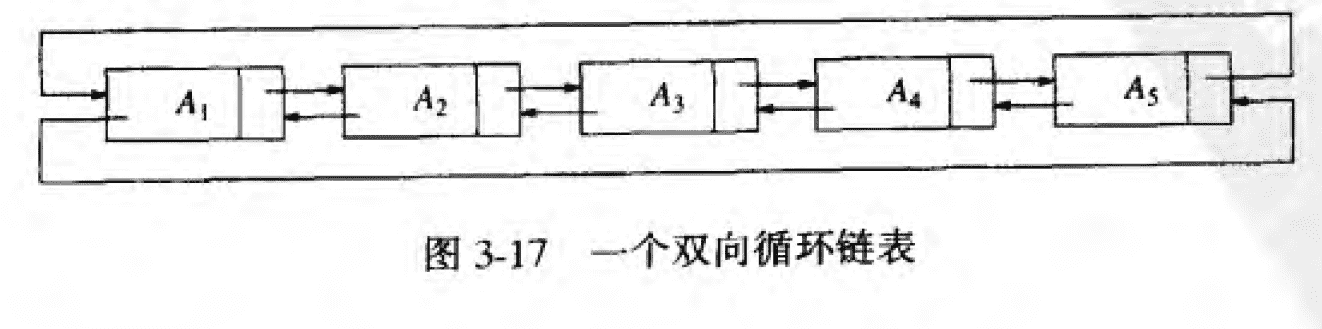
链表与顺序表的区别
| 不同点 | 顺序表 | 链表 |
|---|---|---|
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问 | 可以直接访问任何元素 | 必须从头节点开始往后寻找 |
| 任意位置插入或删除元素 | 要搬移其他的元素,效率低。 | 只需要修改节点的指针指向,效率高 |
| 插入 | 动态顺序表,当空间不够时需要扩容 | 无容量概念,需要就申请,不用就释放 |
| 应用场景 | 元素高效存储,并且需要频繁访问 | 需要在任意位置插入或者删除频繁 |
栈
栈(stack)是限制插入和删除只能在一个位置上进行的表。该位置是表的末端,叫做 栈顶(top) 。
栈中的数据元素遵守 后进先出(先进后出) 的原则。对栈的基本操作有Push (进栈)和Pop (出栈),前者相当于插入,后者则是删除最后插入的元素——即栈顶元素。
我们可以通过想象它是一个水桶:注入水时,水桶的头当做入口。倒水时,水桶的头当做出口。

由于栈是一个表,因此任何实现表的方法都能实现栈。于是我们就可以使用两种以上的方法实现,一种方法使用链表,而另一种方法则使用数组。
栈的链表实现
栈的第一种实现方法是使用 单链表。我们通过在表顶端插入来实现Push, 通过删除表顶端元素实现Pop 。栈顶的操作只是考查表顶端元素并返回它的值。
下面的代码先是创建了一个栈,并且实现创建一个空栈,判断是否为空栈的功能:
typedef struct Stack{ int data; struct Stack *next;}stack;
int isempty(stack *head) //传入栈顶指针即可,不必建立头节点{ return (head->next == NULL)?1:0;}
void create(stack *head){ head->next=NULL;}接下来是最关键的部分——Push和Pop操作:
stack *push(stack *head, int d){ stack *p=(stack *)malloc(sizeof(stack)); if(p==NULL){ printf("Out of space!\\n"); return NULL; } p->next=head; p->data=d; head=p; return head;}
stack *pop(stack *head){ if(!isempty(head)) { stack *p=head; head=head->next; free(p); return head; } else { return NULL; }}最后加上一点连携功能,例如清空整个栈,返回栈顶元素等等:
void emptystack(stack *head){ if(isempty(head)) return; while(!isempty(head)) head=pop(head);}
int gettop(stack *head){ if(isempty(head)) return 0; else return head->data;}这种实现方法的缺点在于对malloc和free造成的开销高,有的缺点通过使用第二个栈可以避免,该第二个栈初始时为空栈。当一个单元从第一个栈弹出时,它只是被放到了第二个栈中。此后,当第一个栈需要新的单元时,它首先去检查第二个栈。
栈的数组实现
另一种实现方法避免了指针并且可能是更流行的解决方案。声明一个数组足够大而不至于浪费太多的空间通常并没有什么困难。如果不能做到这一点,那么节省的做法是使用链表来实现。接下来我们使用数组来实现栈:
我们首先先设定一个变量top,指向栈的顶部,初始化为-1,栈中没有数据元素;只要数据元素进栈,top 就加 1 ;数据元素出栈, top 就减 1。(因为数组从0开始,top从-1开始可以一一对应)
我们在数组的栈中,数组存储数据,此时top作为index来增加移动。所以此时数组我们可以作为参数传入,于是重要的部分即push和pop操作:
int push(int *s, int top, int d){ top++; s[top]=d; return top;}
int pop(int *s, int top){ if(top == -1) return -1; top--; return top;}- pop时此时并没有删除元素,只是引索减一了而已,当然也可以设置一个特殊值,我们把出栈的元素设置为特殊值来判断。
- 当然此时也可以设置为全局变量或结构,不需要作为参数也行。
这是一个纯数组的展示,它需要我们提前定义一个数组,这可能造成浪费,接下来是一个数组+结构的设计,使得空间更好地利用。
我们定义结构的时候有三个域,其中前两个和上面的相同,而Capacity是指容积——最大容量。若它确定。栈即可被动态地确定。
typedef struct Stack{ int *s; int top; int capacity;}stack;
void stackini(stack *head){ head->top=-1;}
int isempty(stack *head){ return (head->top == -1)?1:0;}
int isfull(stack *head){ return (head->top == head->capacity-1)?1:0;}
void push(stack *head, int d){ if(isfull(head)) printf("Stack Full!\\n"); else{ head->top++; head->s[head->top]=d; }}
void pop(stack *head){ if(isempty(head)) printf("Empty stack!\\n"); else head->top--;}如果是需要动态调整,我们则需要在push和pop的时候,根据不同的Capacity,对数组执行realloc。
应用
我们知道了栈的写法,那在实际中如何应用呢,来看一题经典题——平衡符号:
给定一个只包括 ’(’,’)’,’{’,’}’,’[’,’]’ 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- https://leetcode-cn.com/problems/valid-parentheses
这道题就是一个很明显的栈的应用:
左括号一定要和右括号对齐,非常满足栈的特性,所以我们可以将所有的左括号存入一个栈中。然后遇到匹配的右括号,就出栈,判断是否匹配。直到栈为空且字符串中的括号也遍历完了,那么所有括号就正确的匹配了。
所以我们先来造一个栈先,参考上面的代码:
#include<stdlib.h>#include<stdio.h>#include<string.h>
typedef struct Stack{ char *s; int top; int capacity;}stack;
void stackini(stack *head, int l){ head->top=-1; head->capacity=l;}
int isempty(stack *head){ return (head->top == -1)?1:0;}
int isfull(stack *head){ return (head->top == head->capacity-1)?1:0;}
void push(stack *head, char d){ if(isfull(head)) printf("Stack Full!\\n"); else{ head->top++; head->s[head->top]=d; }}
void pop(stack *head){ if(isempty(head)) printf("Empty stack!\\n"); else head->top--;}
char gettop(stack *head){ if(!isempty(head)) return head->s[head->top];}有了这个栈了,我们就来写执行判断命令的函数:
int vaild(char *s){ stack *head; int len=strlen(s); stackini(head,len); for(int i=0;i<len;i++) { if(s[i]=='(' || s[i]=='[' || s[i]=='{') { push(head,s[i]); } else { if(isempty(head)) return 0; //右边多 char t=gettop(head); pop(head); if((t=='(' && s[i]!=')') || (t=='[' && s[i]!=']') || (t=='{' && s[i]!='}') ) return 0; } } if(isempty(head)) return 1; else return 0; //左边多}队列
像栈一样,队列(queue)也是表。然而,使用队列时插入在一端进行而删除则在另一端进行。允许插入的一端称为队尾,允许删除的一端称为队头。
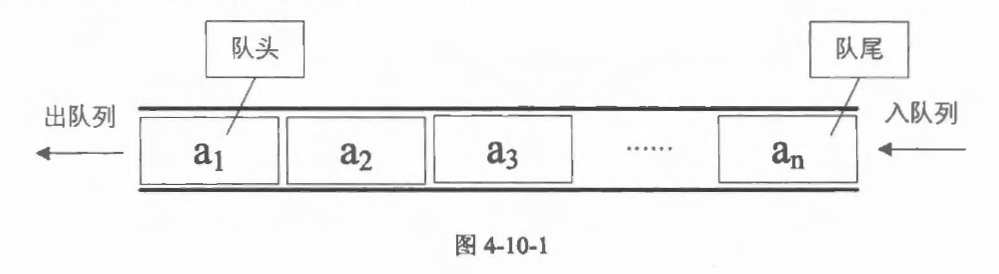
同样是线性表,队列也有类似线性表的各种操作,不同的就是插入数据只能在队尾进行,删除数据只能在队头进行。
队列可以数组和链表的结构实现。链表需要定义两个指针,进行指针操作;而数组的实现只需要移动两个线性引索即可, 对比来说数组的方法更加简便。
队列的链表实现
使用队列的链表就需要我们存储有头指针和尾指针,此时我们应该使用一种嵌套的结构体来实现:
typedef struct QueueNode{ struct QueueNode *next; int data;}Qnode;
typedef struct Queue{ Qnode *head; Qnode *tail;}queue;当我们建立一个队列的时候,只需要传入队列指针就可以获取到它的头和尾的情况。
接下来就是关键的入队和出队,以及其他函数。
void InitQueue(queue *p){ p->head=NULL; p->tail=NULL;}
void EnQueue(queue *p, int d){ Qnode *q=(Qnode *)malloc(sizeof(Qnode)); if(q == NULL) { printf("No space!\\n"); exit(-1); } q->data=d; q->next=NULL; if(p->head==NULL) //空的情况 { p->head=q; p->tail=q; } else{ p->tail->next=q; p->tail=q; }}
void Dequeue(queue *p){ if(p->head==NULL) return; if(p->head->next==p->tail) //只有一个的情况 { free(p->head); p->head=p->tail=NULL; return; } Qnode *q=p->head->next; free(p->head); p->head=q;}接下来是其他辅助函数:
int gettop(queue *p){ return p->head->data;}
int gettail(queue *p){ return p->tail->data;}
int isempty(queue *p){ return (p->head == NULL)?1:0;}
void clearqueue(queue *p){ if(!isempty(p)) { while(p->head != NULL) { Dequeue(p); } }}队列的数组实现
我们定义一个数组Array存储元素数据,同时需要头引索front和尾引索rear,以及需要知晓数组的元素的个数Size,以及判断是否满的容积。
然后在入队时,rear++,front不变。但是在出队的时候,我们不应该 固定front在0位置,应该移动front指向后一位,而不是逐个向前替换。 这样就能把时间复杂度从 降到了 。
但是此时还会出现一个问题,如果rear<front呢?我们一般 使用首尾相接的循环数组 来实现。
故代码:
typedef struct queue{ int Front; int Rear; int Size; int Capacity; int * Array;}Queue;
void queueini(Queue *q, int Capacity){ q->Front=q->Rear=0; q->Size=0; q->Capacity=Capacity;}
int isempty(Queue *q){ return q->Front == q->Rear;}
int isfull(Queue *q){ return q->Size == q->Capacity;}
void Enqueue(Queue *q, int d){ if(isfull(q)) { printf("Full, No space!\\n"); exit(-1); } q->Array[q->Rear]=d; if(++q->Rear == q->Capacity) //if rear is tail of array, then go to begining. q->Rear=0; q->Size++;}
void Dequeue(Queue *q){ if(isempty(q)) { return; } if(++q->Front == q->Capacity) //if front is tail of array, then go to begining. q->Front=0; q->Size--;}使用动态数组的话需要每次入队出队都重新调整数组大小。
后记
才疏学浅,难免有错误和不当之处,欢迎交流批评指正!
