

前言
堆排序(HeapSort)我们之前已经学习过,但分析建堆和堆排序没有详细见过,这一篇将回顾堆与堆排序与分析它们。
之前的堆学习笔记请见数据结构中:
https://hoyue.fun/data_structure_5.html
建堆与堆排序算法与分析
堆属性
二叉堆(binary heap) 可以用数组表示,这个数组对应一棵完全二叉树。根据层序遍历顺序对完全二叉树结点进行编号,其中根结点下标为 1 。
堆可以存储在数组(A)中,那么其他的属性我们可以很容易得到:
- 节点高度= 从节点到叶子的最长简单路径上的边数。
- 堆的高度= 根的高度= 。
- 树的根(root)是A[1]。
- A[i]的父母(parent)节点= ,向下取整。
- A[i]的左孩子(left child)= 。
- A[i]的右孩子(right child)= 。
- A.heap-size表示A中存储了多少元素。只有 在堆中。
- 对于max-heaps(根上为最大元素):对于除根之外的所有节点i, 。
- 对于min-heaps(根上为最小元素):对于除根之外的所有节点i, 。
我们把父母节点与孩子用函数表示:
PARENT(i) return ⌊i/2⌋LEFT(i) return 2iRIGHT(i) return 2i + 1维护堆
我们要检查数组A下标i的元素,是否符合堆的性质,我们需要根据堆的性质,将其调整到合理的位置。
在堆中下标i的元素发生变化的时,我们要对堆进行维护,将其重新调整为一个堆,使得堆的性质不变。
以大根堆为例,我们使用下面函数来维护堆:
MAX-HEAPIFY(A, i) l = LEFT(i) r = RIGHT(i) if l ≤ A.heap-size and A[l] > A[i] largest = l else largest = i if r ≤ A.heap-size and A[r] > A[largest] largest = r if largest ≠ i exchange A[i] with A[largest] MAX-HEAPIFY(A, largest)这个过程是一个向下调整(Percolate Down)的过程,将A[i]和其左右孩子进行比对,如果不是三者中最大的,就说明不符合大根堆性质,该结点和三个结点中最大的结点进行交换,递归执行。
例如下面这个例子,维护 位置2结点值为4 的结点:
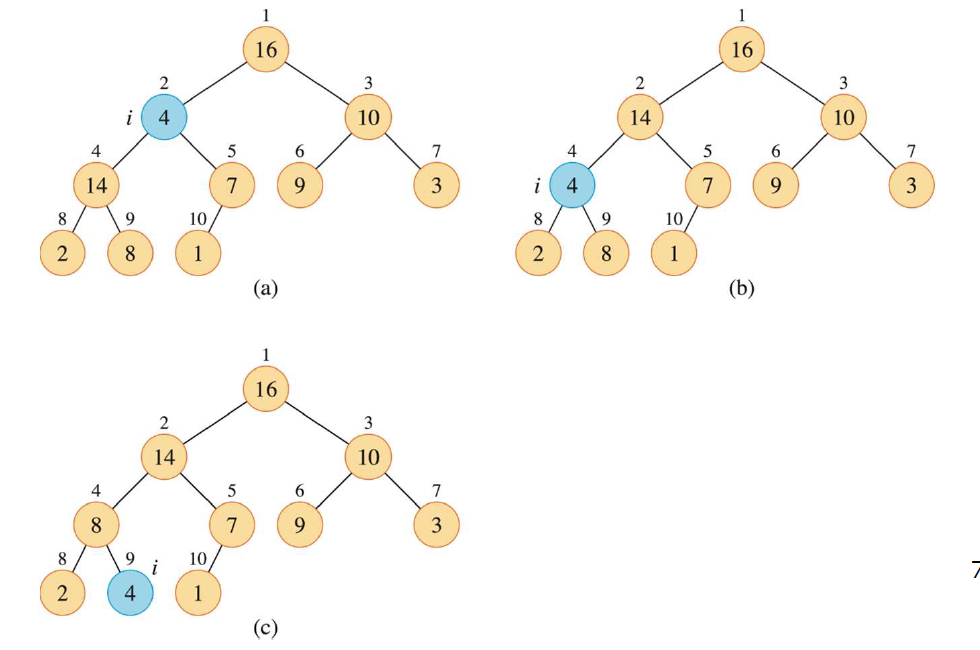
根结点和其左结点或者右结点发生元素交换,检查和交换的代价为 ,设子树规模为 ,左子树或者右子树最大规模为 (这是结论,下面将证明) 。
这个递归式的表达式可以写为: ,根据Master Theorem Case 2, ,则递归式的时间复杂度 。
下面证明左子树或者右子树最大规模为 :
我们知道,堆是一个完全二叉树的模型,它每一层将数据分成两个部分,它的高度可以通过: 。
堆的结点数n,我们可以计算得,最多结点数为全满的情况: ,最少的为最后一层仅有一个结点的情况: 。
由于堆是对应一棵完全二叉树,根结点的左子树结点数 大于等于 根结点的右子树结点数。
对于一个完全二叉树,它的最后一层可能不是完全填满的。假设我们假设左子堆是一个高度为 的满二叉树,右子堆是一个高度为 的满二叉树。于是此时总高度为 。
左子堆的结点数量: (因为有 有h+1个数)
同理,右子堆的结点数量: ,总数为: 。
左子树的最大规模:
于是我们就得到了左子树规模为 。
当二叉树为满二叉树时,左右子树结点个数相等。经过上面的计算很容易知道,左右子树的规模均为 。所以堆维护的递归式为:
根据Master Theorem Case 2,它们最后为 。
建堆
我们对一个数组,按照自底向上的顺序多次调用MAX-HEAPIFY,就能将这个数组转换为一个大根堆。于是有这样的代码:
BUILD-MAX-HEAP(A, n) A.heap-size = n for i = floor(n/2) down to 1 MAX-HEAPIFY(A, i)建堆过程的调整操作是从后往前遍历数组,对应完全二叉树调整顺序就是从倒数第二层往上调整,每层从右往左调整。
叶结点作为子树只有一个结点,一定符合堆性质,所以就从这些叶结点的父母结点开始调整,这就是一个自下而上的过程,只要所有子树都符合堆的性质,那么这个完全二叉树一定符合堆的性质,这样也就建堆完成了。
例如下面这个例子:
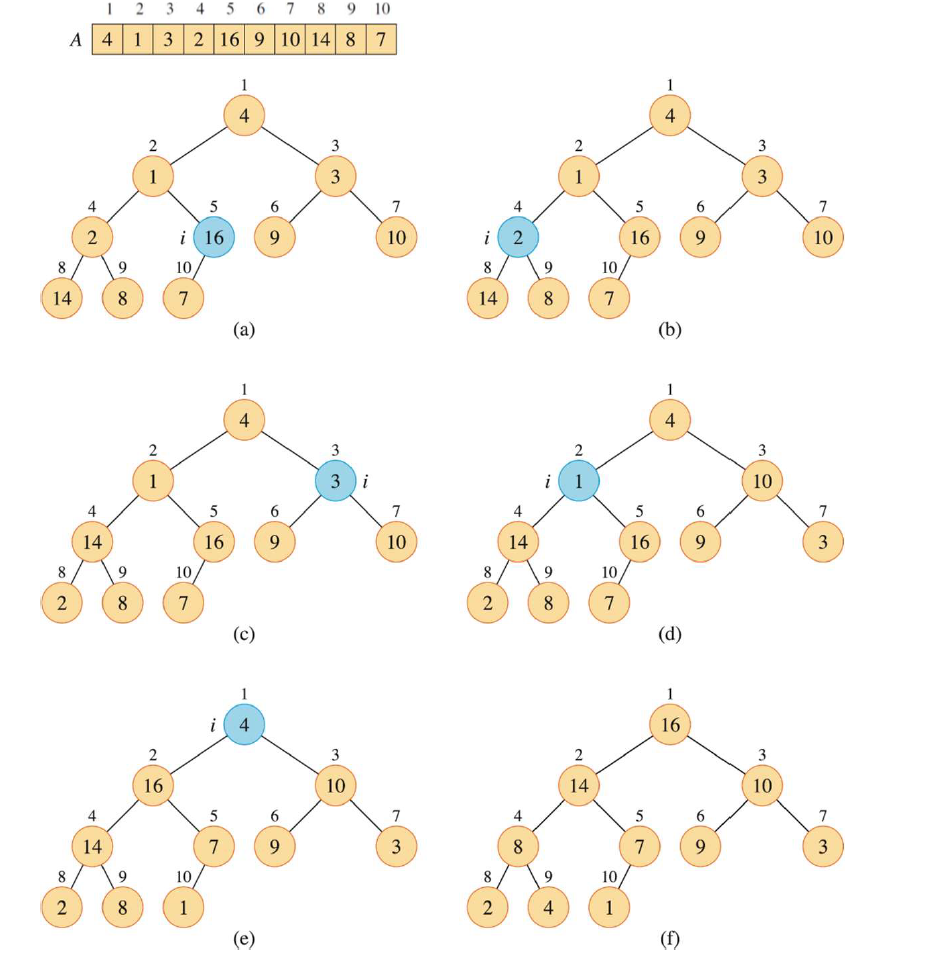
分析建堆算法,最简单的情况为for循环执行了n/2次,即 被调用了 次,于是建堆的时间复杂度 。
为了精确证明它,我们先需要找到,堆有多少个高度为h的结点。
在前面的证明中我们知道,一棵有n个节点的二叉树的深度为 。如果我们设在任何一个有n个元素的满二叉堆中,从叶子节点到某节点的高度为h(从叶子节点一直到某个节点的高度为h,而不是整个堆的高度为h)。那么该节点位于距离根节点 的深度(从根节点到该节点的路径上经过的边数)上。
举个例子解释:
1 / \ 2 3 / \ / \4 5 6 7这个堆是一棵完整的二叉树,并且有7个节点。我们可以看到,根节点的深度为0,第二层(包括节点2和节点3)的深度为1,第三层(包括节点4、5、6和7)的深度为2。
现在假设我们要找到节点5的深度。从上面的图中可以看出,节点5是叶子结点,距离叶子结点的高度为0,因此它的h=0。我们知道这个堆有7个结点,因此根据公式,节点5位于深度 的位置。
所以在这一层,高度为h,一共有 个结点,因为 。
我们有一个结论 ,可以通过数学归纳法证明它:
当n=1时:
,不等式成立。
假设当n=k时,不等式成立,即 。
当n=k+1时,有:
(由于k>=1)
因此,当 时,不等式也成立。因此,对于所有的正整数n,都有
于是, 。我们知道了在高度h处最多有 个结点, 函数在高度h的时间需要O(h)。设每一层的消耗为c,那么我们就可以计算建堆的总消耗了。
用 表示,对这个式子进行一些化简得:
于是建堆的过程,时间复杂度为 。
堆排序
堆排序算法就是先建堆,并一个个删除头部结点,再维护堆即可。删除堆只需要将A[1]与A[A.size]交换,然后维护1的位置的结点即可。以大根堆为例:
HEAPSORT(A, n) BUILD-MAX-HEAP(A, n) for i = n downto 2 swap(A[1], A[i]) A.heap-size = A.heap-size - 1 MAX-HEAPIFY(A, 1)这个过程例如:
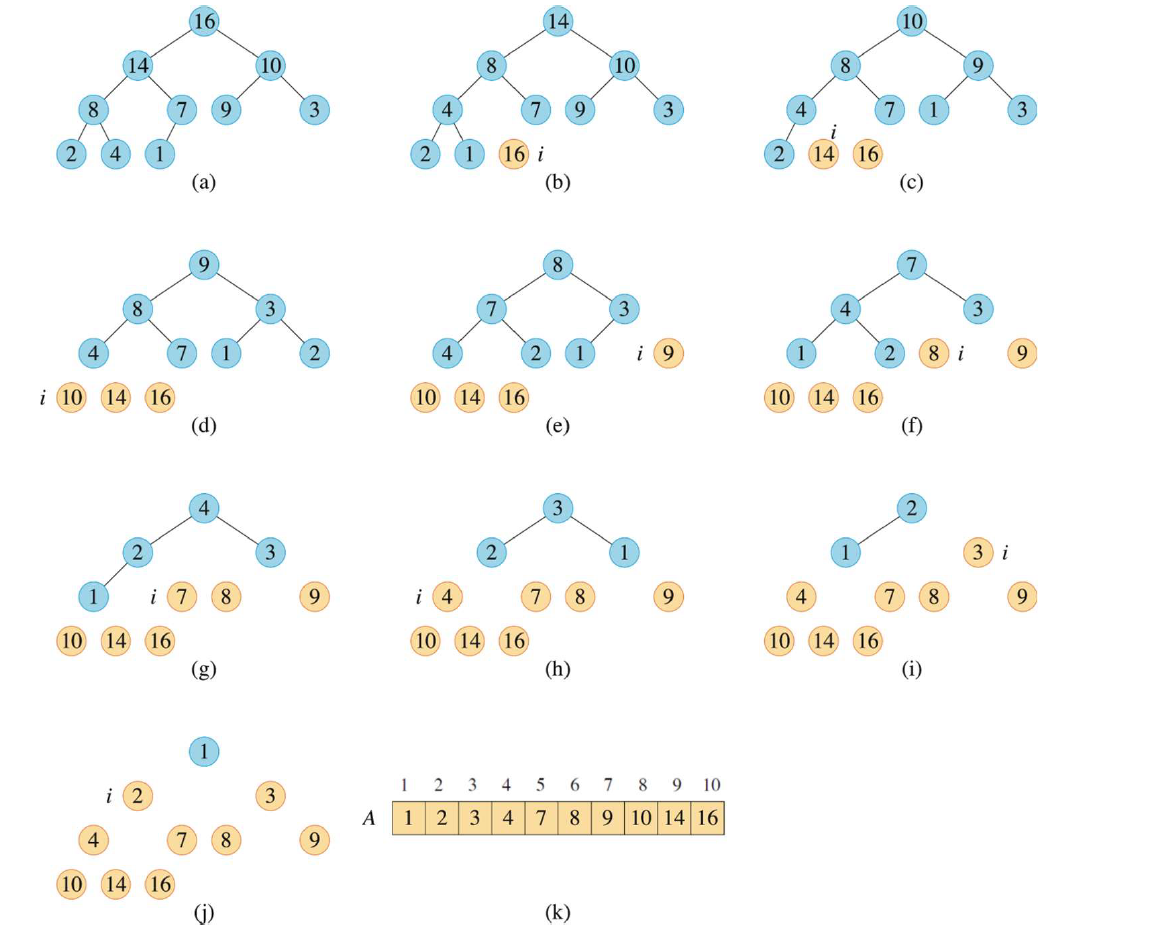
分析这个算法就非常简单了,一步步看:
- BUILD-MAX-HEAP:
- for loop: times
- Exchange elements:
- MAX-HEAPIFY:
那么最后结果就是
优先队列
优先队列是一组包含关键字(key)的元素的集合S,一个最大优先队列(max-priority queue),可以做到下面这些内容:
INSERT(S, x, k): 将key为k的元素x插入到集合S中,这等价于操作 。MAXIMUM(S): 返回S中key最大的元素。INSERT(S, x, k): 移除并返回S中具有最大key的元素。INCREASE-KEY(S, x, k): 将元素x的key的值增加到新的值k,假设该值至少与x的当前key值一样大。
维护一个优先队列,在堆中可以使用元素数组下标作为句柄,优点是优先队列中每个元素都有此特征,不需要额外修饰,缺点是建立和维护映射需要额外代价,可以使用哈希表进行映射。我们把用来和元素形成映射的元素称为句柄(handle),通过句柄可以访问元素。
找到最大元素
找到最大元素非常简单,就是堆的根。当然还需要检查是否堆已空。
MAX-HEAP-MAXIMUM(A) if A.heap-size < 1 error "heap underflow" return A[1]它的时间复杂度显而易见为Θ(1)。
取得并删除最大元素
和堆排序一样,取得堆的根并维护堆:
MAX-HEAP-EXTRACT-MAX(A) max = MAX-HEAP-MAXIMUM(A) A[1] = A[A.heap-size] A.heap-size = A.heap-size - 1 MAX-HEAPIFY(A, 1) return max它的时间复杂度显而易见为O(lgn)。
替换并维护元素
对于位置x,新的值为k,当k>=x时,x的值将会被替换为k,替换后并维护堆。
MAX-HEAP-INCREASE-KEY(A, x, k) if k < x.key error "new key is smaller than current key" x.key = k find the index i in array A where object x occurs while i > 1 and A[PARENT(i)].key < A[i].key exchange A[i] with A[PARENT(i)], updating the information that maps priority queue objects to array indices i = PARENT(i)它的时间复杂度显而易见为O(lgn)。
插入元素
为了使用之前替换的函数,我们需要先把插入位置置为极小值,再替换即可。
MAX-HEAP-INSERT(A, x, n) if A.heap-size == n error "heap overflow" A.heap-size = A.heap-size + 1 k = x.key x.key = -∞ A[A.heap-size] = x map x to index heap-size in the array MAX-HEAP-INCREASE-KEY(A, x, k)它的时间复杂度显而易见为O(lgn)。
优先队列在队列不为空的情况下可以执行出队操作,移除队头元素,在队列未满的情况下可以执行入队操作,新增元素加入队尾,每次队列发生变化(增删改)均要重新调整堆,此外还要维护好句柄的映射。
后记
本章分析了堆的基本操作和优先队列的相关时间复杂度。
